[AI] 深度数据 - Data
Data Engineering
Data Pipeline
Introduction
[DE] How to learn Big Data【了解大数据】
[DE] Pipeline for Data Engineering【工作流案例示范】
[DE] ML on Big data: MLlib【大数据的机器学习方案】
编程基础
[Spark] Scala programming - basic level【大数据编程基础】
[Spark] Java programming - basic level
DE基础
![]()
[Spark] 00 - Install Hadoop & Spark
[Spark] 01 - What is Spark【RDD原理和方法】
[Spark] 02 - Practice PySpark【实践编程】
[Spark] 03 - Spark SQL【具有了SQL操作的便捷性】
-
- [Hadoop] HBase【分布式稀疏大表】
[Spark] 04 - What is Spark Streaming
[Spark] 06 - Structured Streaming【对应 DataFrame】
DE进阶
[CDH] Cloudera's Distribution including Apache Hadoop【系统环境搭建】
[CDH] New project for ML pipeline【IDE环境搭建】
[CDH] Acquire data: Flume and Kafka【API使用】
[CDH] Redis: Remote Dictionary Server【API使用】
[CDH] Phoenix : SQL on HBase【API使用】
[CDH] Process data: integrate Spark with Spring Boot【Spark计算、Spring服务】
/* continue */
MLOps
![]()
[Full-stack] 一切皆在云上 - AWS【AWS基础服务】
SageMaker
![]()
[Full-stack] 一切皆在云上 - AWS【初步了解】
AirFlow
[Airflow] 02 - Building a Machine Learning Pipeline with Apache Airflow
[Airflow] 03 - Core concepts and try your first DAG
Ray
[Link] Fast and Simple Distributed Computing【官网】
[Link] 蚂蚁金服新计算实践:基于Ray的融合计算引擎
[Link] Deploying reinforcement learning in production using Ray and Amazon SageMaker
Data Science
Local Data Processing
"矩阵"计算
![]()
![]()
[Code] 大蛇之数据工程【语法驱动】
[Code] 变态之人键合一【需求驱动】
[Pandas] 01 - A guy based on NumPy【如何高性能】
[Pandas] 02 - Tutorial of NumPy【NumPy常见用法】
"表格"处理
[Pandas] 03 - DataFrame【读入并处理表格】
[Pandas] 04 - Efficient I/O【从数据库加载到arr, df, EArray】
"特征"工程

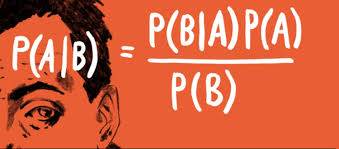
[Feature] Preprocessing tutorial【伟哥的特征工程步骤讲解】
[Feature] Feature engineering【特征工程大纲】
[Feature] Build pipeline【展示Pipeline大概思路过程】
[Feature] Final pipeline: custom transformers【本章总结】
"机器"学习
[AI] 深度数学 - Bayes【Scikit-learn Cookbook】
[Distributed ML] Yi WANG's talk【王益大佬】
数据"可视化"
[Matplotlib] Data Representation
Kaggle经验谈
[Kaggle] Online Notebooks【模块化代码】
[Kaggle] How to kaggle?【方法导论】
[Kaggle] How to handle big data?【方法进阶】
GPU Data Processing
[Spark] Spark 3.0 Accelerator Aware Scheduling - GPU【ing】
Cloud Data Processing
Introduction
[ML] Pyspark ML tutorial for beginners【房价预测之"常规分析套路"】
ML-Features

[ML] Load and preview large scale data【保证特征完整性】
[Link] https://spark.apache.org/docs/2.4.4/ml-guide.html
[ML] Pipeline in Distributed ML Library【Pipline"套路”】
[ML] Online learning【Pipline作为 “在线学习” 的 “数据源”】
Distributed ML
[ML] LIBSVM Data: Classification, Regression, and Multi-label【三种方案时效对比】
[ML] Machine Learning in the Common Infrastructure ecosystem【架构了解】
[Link] 超强的强化学习系统怎么实现?Ray是啥?tune和rllib又是什么?
Big Data Algorithms(整理中)
本篇章终极形态,开发/优化一个大数据分布式算法。
https://github.com/apache/spark/tree/master/examples/src/main/python/ml
https://spark.apache.org/mllib/
http://stanford.edu/~rezab/slides/
Distributed Computing with Spark, Reza Zadeh 20140623
Reza Zadeh, Scalable Machine Learning
Apache Spark™ ML and Distributed Learning (1/5) (databrick)
Module 4: Creating Distributed Algorithms
stanford.edu: Chapter 12 Large-Scale Machine Learning
<Large Scale Machine Learning with Python>
Processing Big Data in Main Memory and on GPU,2016年硕士论文
[Spark News] Spark + GPU are the next generation technology
/* implement */

 浙公网安备 33010602011771号
浙公网安备 33010602011771号