[DE] ML on Big data: MLlib
Pipeline的最终目的就是学会Spark MLlib,这里先瞧瞧做到心里有数:知道之后要学什么,怎么学。
首要问题
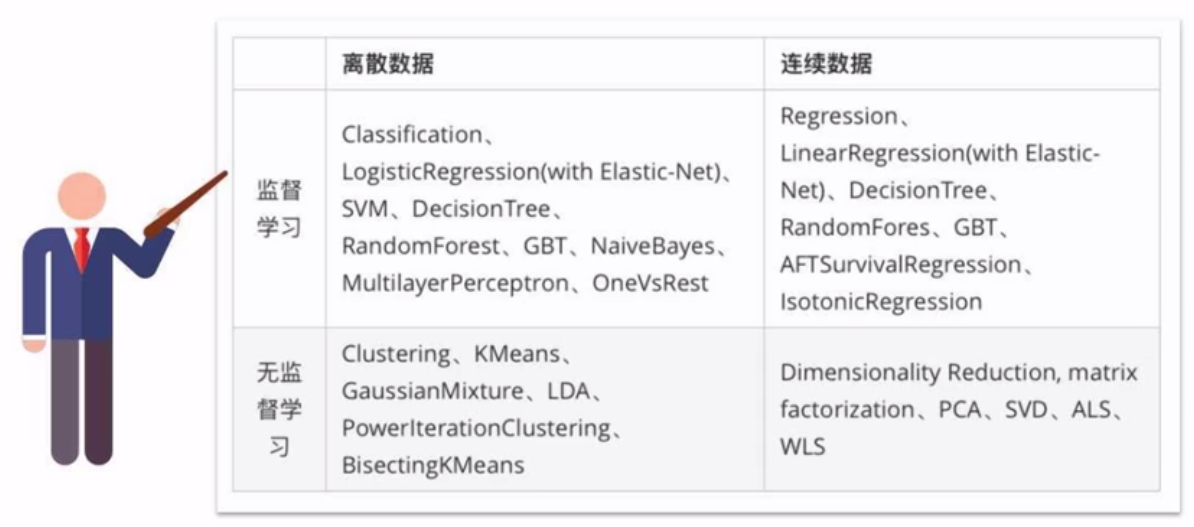
一、哪些机器学习算法可以并行实现?
四类算法:分类、回归、聚类、协同过滤
以及特征提取、降维、数据流管理功能。
后者可以与Spark SQL完美结合,支持的算法如下:
二、何为机器学习流水线?
Spark SQL中的DataFrame作为数据集。
Transformer: 打上标签。
Estimator: 训练数据的算法。
parameter: 参数。
最后,通过接口将各个Transformer组装起来构成”数据流“。
>>> pipeline = Pipeline(stags=[stage1,stage2,stage3])
构建文本分类流水线
构建评估器
Tokenizer ----> HashingTF ----> Logistic Regression
参考:[ML] Naive Bayes for Text Classification
tokenizer = Tokenizer(inputCol = "text", outputCol = "words") hashingTF = HashingTF(inputCol = tokenizer.getOutputCol(), outputCol = "feature") lr = LogisticRegression(maxIter = 10, regParam = 0.001)
# 得到一个评估器
pipeline = Pipeline(stages = [tokenizer, hashingTF, lr])
训练转换器
model = pipeline.fit(training)
测试模型
test = spark.createDataFrame([ (4, "spark i j k"), (5, "l m n"), (6, "spark hadoop spark"), (7, "apache hadoop") ], ["id", "text"])
# 测试过程
prediction = moel.transform(test)
# 展示测试结果
selected = prediction.select("id", "text", "probability", "prediction")
for row in selected.collect():
rid, text, prob, prediction = row
print(...)
MLlib的算法教程
一、大数据文件加载
文件格式解析
part-00178-88b459d7-0c3a-4b84-bb5c-dd099c0494f2.c000.snappy.parquet
加载文件
1. 连接spark
2. 创建dataframe
2.1. 从变量创建
2.2. 从变量创建
2.3. 读取json
2.4. 读取csv
2.5. 读取MySQL
2.6. 从pandas.dataframe创建
2.7. 从列式存储的parquet读取
2.8. 从hive读取
3. 保存数据
3.1. 写到csv
3.2. 保存到parquet
3.3. 写到hive
3.4. 写到hdfs
3.5. 写到mysql
注意,这里的 “users.parquet” 是个文件夹!
# 读取example下面的parquet文件 file = r"D:\apps\spark-2.2.0-bin-hadoop2.7\examples\src\main\resources\users.parquet"
df = spark.read.parquet(file) df.show()
查询数据
Spark2.1.0+入门:读写Parquet(DataFrame)(Python版)
>>> parquetFileDF = spark.read.parquet("file:///usr/local/spark/examples/src/main/resources/users.parquet"
>>> parquetFileDF.createOrReplaceTempView("parquetFile") >>> namesDF = spark.sql("SELECT * FROM parquetFile") >>> namesDF.rdd.foreach(lambda person: print(person.name)) Alyssa Ben
二、AWS S3 文件处理
大文件一般都放在S3中,如何在本地远程处理呢?
其实AWS已经提供了方案:Amazon EMR
三、MLlib算法学习
Welcome to Spark Python API Docs!
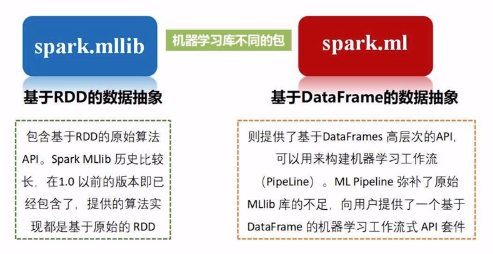
Spark MLlib是Spark中专门用于处理机器学习任务的库,但在最新的Spark 2.0中,大部分机器学习相关的任务已经转移到Spark ML包中。
两者的区别在于MLlib是基于RDD源数据的,而ML是基于DataFrame的更抽象的概念,可以创建包含从数据清洗到特征工程再到模型训练等一系列机器学习工作。
所以,未来在用Spark处理机器学习任务时,将以Spark ML为主。
End.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号