[DE] Pipeline for Data Engineering
How to build an ML pipeline for Data Science
垃圾信息分类
Ref:Develop a NLP Model in Python & Deploy It with Flask, Step by Step
其中使用naive bayes模型 做分类,此文不做表述。
重点来啦:Turning the Spam Message Classifier into a Web Application
其实就是http request 对接模型的 prediction。
Python & GPU加速
效果对比
Ref: 测试pytorch 调用gpu 加速矩阵相乘. accelerate matrix multiplication
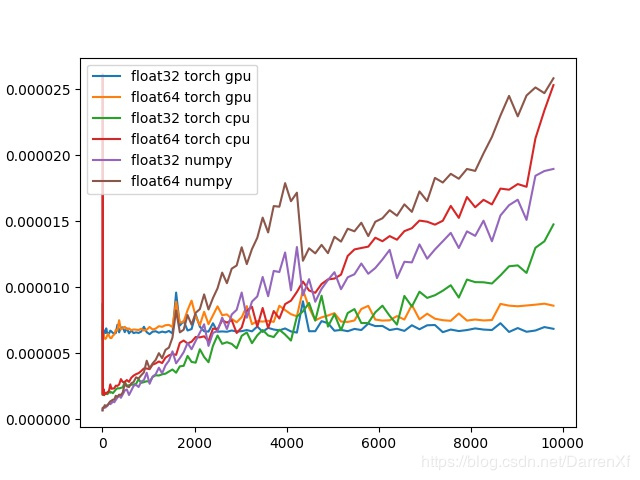
这个级别的矩阵加速似乎并不是很明显。尤其是元素数两千之前,cpu是比gpu效果好的。
元素数目超过两千就可以选择用gpu,能有加速效果。
CUDA加速方案
Ref: Python GPU加速
(1)一个来自Anaconda的Python编译器Numba,它可以在CUDA-capable GPU或多核cpu上编译Python代码。
(2)Numba团队的另一个项目叫做pyculib,它提供了一个Python接口,用于
-
- CUDA cuBLAS (dense linear algebra,稠密线性代数)
- cuFFT (Fast Fourier Transform,快速傅里叶变换)
- cuRAND (random number generation,随机数生成)
其他方案大全
All libraries below are free, and most are open-source.
Goto: A Beginner's Guide to Python Machine Learning and Data Science Frameworks
ML Pipeline
定义理解
Data Pipeline,中文译为数据工作流。
你所要处理的数据可能包含CSV文件、也可能会有JSON文件、Excel等各种形式,可能是图片文字,也可能是存储在数据库的表格,还有可能是来自网站、APP的实时数据。
在这种场景下,我们就迫切需要设计一套Data Pipeline来帮助我们对不同类型的数据进行自动化整合、转换和管理,并在这个基础上帮我们延展出更多的功能,比如可以自动生成报表,自动去进行客户行为预测,甚至做一些更复杂的分析等。
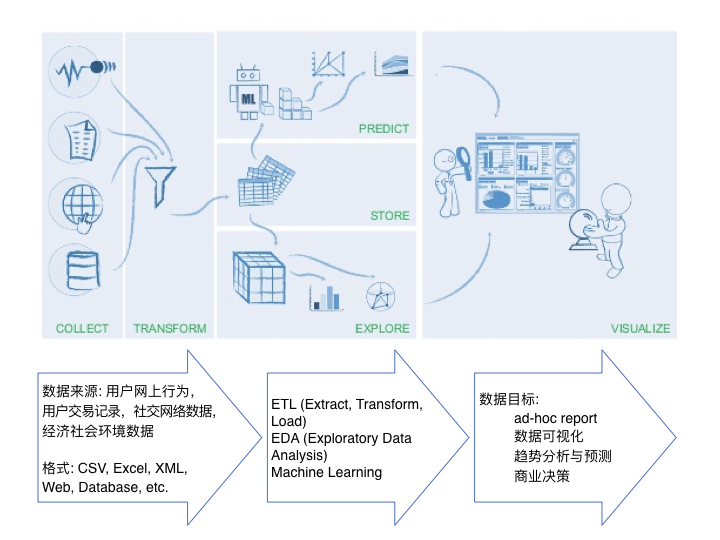
与传统方式的区别
相对于传统的ETL,Data Pipeline的出现和广泛使用,主要是应对目前复杂的数据来源和应用需求,是跟“大数据”的需求密不可分的。
Zuper Cor.
跟superannuation相关的AI Platform?
/* implement */
Data Pipeline在机器学习中的应用案例
科技巨头都爱的Data Pipeline,如何自动化你的数据工作?
Approaching (Almost) Any Machine Learning Problem | Abhishek Thakur
System Architectures for Personalization and Recommendation
Pipeline框架
在这个案例中,我们用到的数据是来源于亚马逊的产品分类信息,其中包含了产品介绍、用户对产品的评分、评论,以及实时的数据。

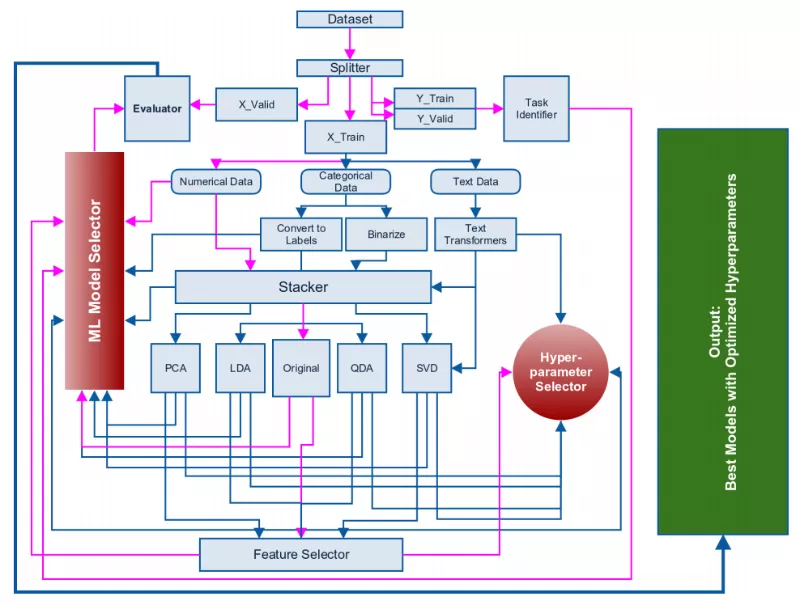
产品打分
这个项目的主要目的是希望可以用这些实时获取的数据构建模型,从而对新的产品进行打分。
第一个Data Pipeline,用于构建基本的模型。
第二个Data Pipeline,使其服务于实时预测。
推荐系统
这个项目的主要目的是希望可以用这些实时获取的数据构建模型,从而对新的产品进行打分。
三条工作流
Netflix的Data Pipeline系统可以分成三个部分:实时计算、准实时计算、离线部分。
-
- 实时计算部分,主要是用于对实时事件的响应和与用户的互动,它必须在极短的时间里对用户的请求作出响应,因此它比较适用于小量数据的简单运算。
- 离线计算,它则不会受到这些因素的干扰,比较适用于大量数据的批处理运算。
- 准实时运算,则是介于实时和离线之间。它可以处理实时运算,但是又不要求很快给出结果。比如当用户看过某部电影之后再给出推荐,就是准实时运算,可以用来对推荐系统进行更新,从而避免对用户的重复推荐。

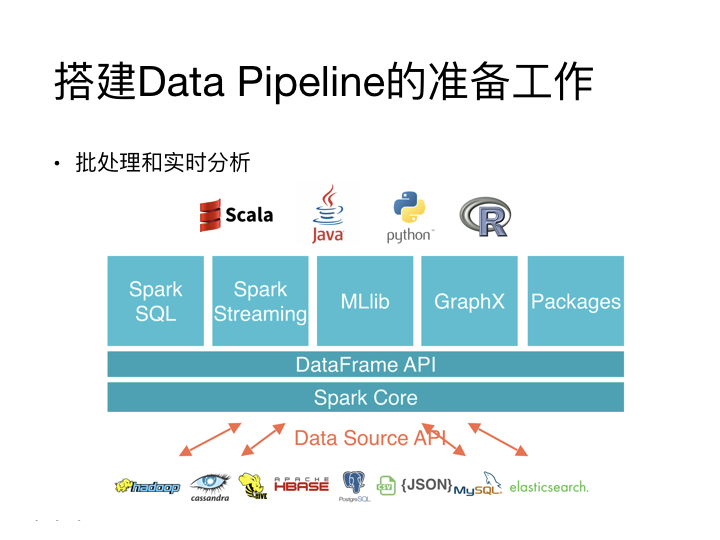
搭建Data Pipeline的常用工具
数据存储
如果你的数据量特别大,你很有可能需要使用像是Hive这样的基于大数据的数据存储工具。
数据处理
像是Spark就是比较流行的的处理方案,因为它包含了很多接口,基本上可以处理Data Pipeline中所需要面临的绝大多数问题。
分享一个搭建Data Pipeline可能会用到的小管理工具。它是由Airbnb开发的一款叫做Airflow的小软件。
这个软件是用Data Pipeline来写的,对于Python的脚本有良好的支持。
它的主要作用是对数据工作的调度提供可靠的流程,而且它还自带UI,方便使用者监督程序进程,进行实时的管理。
原文赏析
主要是对链接中文章仔细再过一遍,总结知识点。
- Approaching (Almost) Any Machine Learning Problem | Abhishek Thakur
- System Architectures for Personalization and Recommendation
/* implement */
End.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号