
[Kubeflow] 00 - Introduction to Kubeflow
Ref: Introduction to Kubeflow: Fundamentals【课程不错】
Ref: Introduction【官网文档】
Ref: Kubeflow Pipelines standalone【我需要的】
Background
** KubeFlow **
Ref: 最好的任务编排工具:Airflow vs Luigi vs Argo vs MLFlow vs KubeFlow
Argo vs. Kubeflow
Parts of Kubeflow (like Kubeflow Pipelines) are built on top of Argo, but Argo is built to orchestrate any task, while Kubeflow focuses on those specific to machine learning – such as experiment tracking, hyperparameter tuning, and model deployment. Kubeflow Pipelines is a separate component of Kubeflow that focuses on model deployment and CI/CD and can be used independently of Kubeflow’s other features. Both tools rely on Kubernetes and are likely to be more interesting to you if you’ve already adopted that. With Argo, you define your tasks using YAML, while Kubeflow allows you to use a Python interface instead.
-
- Use Argo if you need to manage DAG of general tasks running as Kubernetes pods.
- Use Kubeflow if you want a more opinionated tool focused on machine learning solutions.
Ref: Argo: Kubernetes Native Workflows and Pipelines | Canva
Canva's choice
At Canva, we leverage it to schedule and run all model trainers on our Kubernetes clusters.
The map-reduce approach requires two kinds of application containers with differing responsibilities:
-
- Optimizer: A single container generating the next batch of hyperparameters to explore based on all previous hyperparameters and model evaluation results.
- Model Trainers: A batch of model trainer containers that accepts hyperparameter values and returns pre-defined evaluation metrics.

Ref: KubeFlow-Pipeline及Argo实现原理速析
Based on Argo
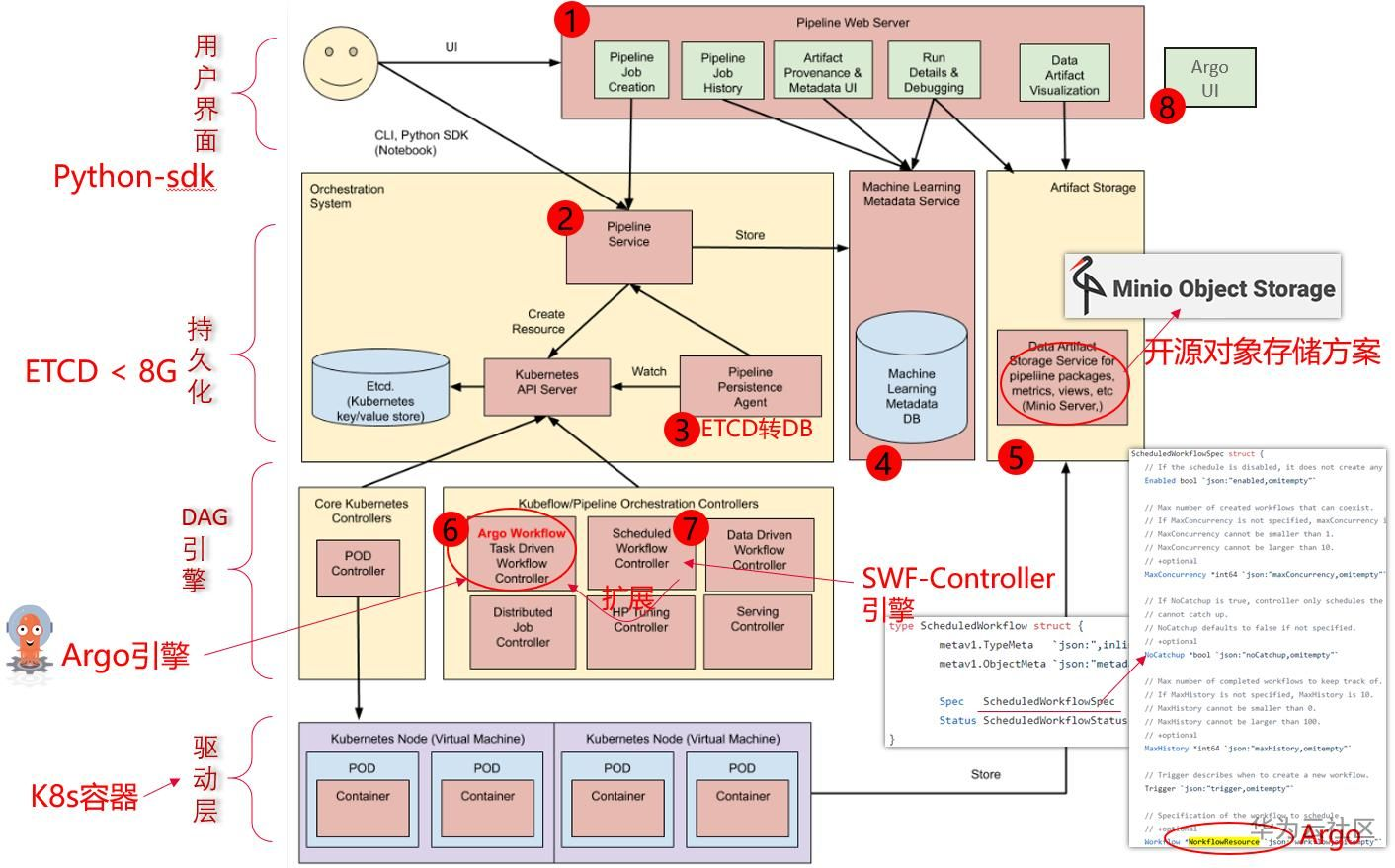
KubeFlow的Pipeline子项目,由Google开源,其全面依赖Argo作为底层实现,并增强持久层来补充流程管理能力,同时通过Python-SDK来简化流程的编写。
描述了Argo "下一步容器怎么拿到上一步容器的结果"。
为什么要在Argo之上重新开发一套?
部署一套Argo很简单,启动一个K8s-Controller就行。可是部署一套 Kubeflow-Pipeline 系统就复杂多了,总共下来有8个组件。那是Argo什么地方不足,需要新开发一套KFP,并搞这么复杂呢?主要的原因还在于Argo是基于K8s云原生这套理念,即ETCD充当“数据库”来运行的,导致约束比较大。
流程模板,历史执行记录,这些大量的信息很明显需要一个持久化层(数据库)来记录的,单纯依赖ETCD会有单条记录不能超过1M,总记录大小不能超过8G的约束。
所以一个完整的流程引擎,包含一个数据库也都是很常规的。因此KFP在这一层做了较大的增强。
世界上为什么有这么多的 "流程引擎"
DAG基础核心非常简单,同时,各个领域想要做的事情却迥然不同。即使一个简单的步骤,
-
- 大数据步骤说:“这一步要执行的SQL语句是xxx”,
- 而K8s任务步骤却说:“这一步执行需要的Docker镜像是yyy”。
所以,各种各样的流程引擎就自然的出现了。


AWS:Cloudformation编排,Batch服务,SageMaker-ML Pipeline,Data Pipeline Azure:Pipeline服务,ML Pipeline,Data Factory Aliyun:函数Pipeline服务,ROS资源编排,Batch服务,PAI-Studio 大数据领域:Oozie,AirFlow 软件部署:Puppet,Chef,Ansible 基因分析:DNAnexus,NextFlow,Cromwell
成熟的流程引擎的4层架构
- 第一层:用户交互层。如:模板语法规则,Console界面等
- 第二层:API持久化层。如:模板记录,历史执行记录等
- 第三层:引擎实例层。如:能否水平扩容,流程是否有优先级等
- 第四层:驱动层。如:一个步骤能干什么活。跑一个容器还是跑一个Spark任务。
基本比较成熟的引擎都符合这种架构,例如AirFlow流程引擎,华为云的应用编排(AOS)引擎,数据湖工厂(DLF)引擎等都是如此。
目前Argo以及Kubeflow-Pipeline在引擎核心组件的水平扩展上,也即第三层引擎能力层稍有不足。同时其驱动层,目前也只能对接K8s(即只能跑容器任务)。在选型的时候需要考虑进去。
** Kubernetes **
Ref: Kubeflow Fundamentals - How To Build ML/AI Pipelines
Ref: [K8S] 00 - Kubernetes Arch
一些简单的相关知识点的回顾。
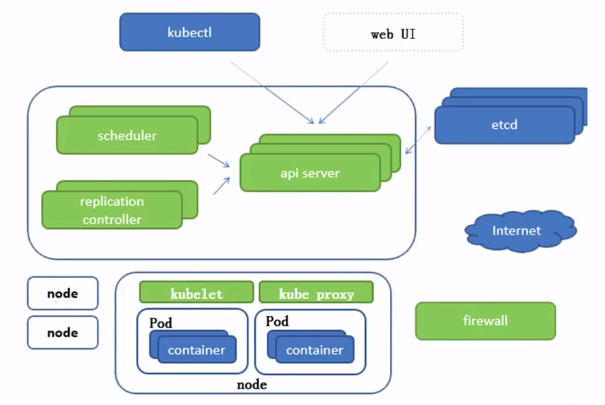
IBM课程
Ref: Kubeflow 系列,第 1 讲:Kubeflow 概览和功能介绍

 浙公网安备 33010602011771号
浙公网安备 33010602011771号