[MySQL] 01- Basic sql
准备
一、配置
1. 登录:mysql -u root -p
2. phpMyAdmin创建数据库,并导入.sql文件。
3. 支持中文:set names utf8;
二、面试题
参考:面试宝典----数据库【一些经典的问题】
基础教程
详见: http://www.runoob.com/sql/sql-select.html
一、查询
SELECT name,country FROM Websites;
SELECT DISTINCT country FROM Websites;
SELECT * FROM websites ORDER BY country,alexa DESC; # 不写明ASC DESC的时候,默认是ASC
SELECT * FROM Websites LIMIT 2; # MS使用select top, oracle使用rownum
SELECT * FROM Websites WHERE id=1;
- 常见运算符
| 运算符 | 描述 |
|---|---|
| = | 等于 |
| <> | 不等于。注释:在 SQL 的一些版本中,该操作符可被写成 != |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| BETWEEN | 在某个范围内 |
| LIKE | 搜索某种模式 |
| IN | 指定针对某个列的多个可能值 |
| IS NULL | e.g. where comm is null Goto: SQL NULL 函数 |
| REGEXP | 操作正则表达式 |
补充 - 逻辑运算
Select * from emp where sal > 2000 and sal < 3000; Select * from emp where sal > 2000 or comm > 500; select * from emp where not sal > 1500;
- 模糊查询
-
- LIKE
Select * from emp where ename like 'M%';
Select * from emp where ename like '[CK]ars[eo]n'; # 将搜索下列字符串:Carsen、Karsen、Carson 和 Karson(如 Carson)
查询 EMP 表中 Ename 列中有 M 的值,M 为要查询内容中的模糊信息。
| '%a' | 以a结尾的数据 |
| 'a%' | 以a开头的数据 |
| '%a%' | 含有a的数据 |
| ‘_a_’ | 三位且中间字母是a的 |
| '_a' | 两位且结尾字母是a的 |
| 'a_' | 两位且开头字母是a的 |
-
- SQL [charlist] 通配符
SELECT * FROM websites WHERE name REGEXP '^[GFs]';
SELECT * FROM Websites WHERE name REGEXP '^[^A-H]'; # 选取 name 不以 A 到 H 字母开头的网站。第一个^是开头的意思;第二个^表否定。
-
- Between 作用于 '字符串' 和 '日期'
SELECT * FROM Websites WHERE name BETWEEN 'A' AND 'H'; SELECT * FROM Websites WHERE name NOT BETWEEN 'A' AND 'H'; SELECT * FROM access_log WHERE date BETWEEN '2016-05-10' AND '2016-05-14';
详情请见:SQL Date 函数
二、插入
INSERT INTO websites (name, url, alexa, country) VALUES ('百度', 'https://www.baidu.com/', '4', 'CN');
# 前后一一对应即可。
三、更新
UPDATE websites SET alexa='5000', country='USA' WHERE name='菜鸟教程';
# MySQL中强制在update 语句后携带 where 条件,否则就会报错。set sql_safe_updates=1; 表示开启该参数
四、删除
DELETE FROM websites WHERE name='百度' AND country='CN';
DELETE
|
DELETE FROM test
|
| 删除 所有内容,不保留表的定义,释放空间。 | |
TRUNCATE
|
TRUNCATE test;
|
| 删除 所有内容,保留表的定义,释放空间。 | |
DROP
|
DROP test;
|
|
仅删除 所有内容,保留表的定义,不释放空间。 DROP INDEX / TABLE / DATABASE <name> |
五、Create Db then Table
CREATE DATABASE my_db;
CREATE TABLE Persons
(
PersonID int,
LastName varchar(255),
FirstName varchar(255),
Address varchar(255),
City varchar(255)
);
详情请见:SQL 通用数据类型,SQL 用于各种数据库的数据类型
高级教程
一、别名
- 一个表
SELECT name AS n, country AS c FROM Websites; SELECT name, CONCAT(url, ', ', alexa, ', ', country) AS site_info FROM Websites;
- 多个表
SELECT w.name, w.url, a.count, a.date FROM Websites AS w, access_log AS a WHERE a.site_id=w.id and w.name="菜鸟教程";
二、SQL JOIN
- 四种类型
| INNER JOIN | 如果表中有至少一个匹配,则返回行 |
| LEFT JOIN | 即使右表中没有匹配,也从左表返回所有的行 (左边没空格) |
| RIGHT JOIN | 即使左表中没有匹配,也从右表返回所有的行 (右边没空格) |
| FULL JOIN | 只要其中一个表中存在匹配,则返回行 (两边可能都有空格) |
- 四个示范
Ref: SQL的各种连接Join详解
select * from Table A inner join Table B on Table A.id=Table B.id select * from Table A left join Table B on Table A.id=Table B.id select * from Table A right join Table B on Table A.id=Table B.id select * from Table A full outer join Table B on Table A.id=Table B.id
三、合并表 UNION
默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
SELECT country, name FROM Websites WHERE country='CN' UNION ALL SELECT country, app_name FROM apps WHERE country='CN' ORDER BY country;
四、从一个表 copy info to 另一个表
MySQL 数据库不支持 SELECT ... INTO 语句,但支持 INSERT INTO ... SELECT 。
INSERT INTO websites (name, country) SELECT app_name, country FROM apps;
备份表数据:CREATE TABLE emp AS SELECT * FROM scott.emp
还原表数据:INSERT INTO emp SELECT * FROM scott.emp
约束(Constraints)
一、NOT NULL | DEFAULT
- 非空约束
CREATE TABLE Persons ( P_Id int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255) )
- 默认值约束
CREATE TABLE Persons ( P_Id int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255) DEFAULT 'Sandnes'
OrderDate date DEFAULT GETDATE() )
- 自增属性
CREATE TABLE Persons ( ID int NOT NULL AUTO_INCREMENT, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255),
PRIMARY KEY (ID) )
默认地,AUTO_INCREMENT 的开始值是 1,每条新记录递增 1。如果是自定义起始值,如下操作。
ALTER TABLE Persons AUTO_INCREMENT=100
二、唯一 | 主键 | 外键
- UNIQUE
[1] 唯一标识
CREATE TABLE Persons ( P_Id int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255),
CONSTRAINT uc_PersonID UNIQUE (P_Id,LastName) )
注释:
(a) 命名 UNIQUE 约束,
(b) 定义多个列的 UNIQUE 约束
[2] 撤销约束
ALTER TABLE Persons DROP INDEX uc_PersonID # 撤销 UNIQUE
- PRIMARY KEY
[1] PRIMARY KEY - 类似 UNIQUE
CREATE TABLE Persons ( P_Id int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255),
CONSTRAINT pk_PersonID PRIMARY KEY (P_Id,LastName) )
[2] 撤销约束
ALTER TABLE Persons
DROP PRIMARY pk_PersonID # 撤销 PRIMARY KEY
- FOREIGN KEY
[0] 什么是外键
一个表中的 FOREIGN KEY 指向另一个表中的 PRIMARY KEY。
"Orders" 表中的 "P_Id" 列指向 "Persons" 表中的 "P_Id" 列。
["Persons" 表]
| P_Id | LastName | FirstName | Address | City |
|---|---|---|---|---|
| 1 | Hansen | Ola | Timoteivn 10 | Sandnes |
| 2 | Svendson | Tove | Borgvn 23 | Sandnes |
| 3 | Pettersen | Kari | Storgt 20 | Stavanger |
["Orders" 表]
| O_Id | OrderNo | P_Id |
|---|---|---|
| 1 | 77895 | 3 |
| 2 | 44678 | 3 |
| 3 | 22456 | 2 |
| 4 | 24562 | 1 |
[1] 创建外键
CREATE TABLE Orders ( O_Id int NOT NULL, OrderNo int NOT NULL, P_Id int,
PRIMARY KEY (O_Id), # 这里没有命名 CONSTRAINT fk_PerOrders FOREIGN KEY (P_Id) REFERENCES Persons(P_Id) )
[2] 撤销外键
ALTER TABLE Orders DROP FOREIGN KEY fk_PerOrders
三、ALTER
- 为了添加一列
Switch to table Persons. Then, 添加一列: data。
ALTER TABLE Persons
ADD DateOfBirth date
- 为了改变列的数据类型
ALTER TABLE Persons
ALTER COLUMN DateOfBirth year
四、CHECK - 限制列中的值范围
[1] 创建约束
(a) 命名 CHECK 约束,
(b) 并定义多个列的 CHECK 约束
CREATE TABLE Persons ( P_Id int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255),
CONSTRAINT chk_Person CHECK (P_Id>0 AND City='Sandnes') )
[2] 撤销约束
ALTER TABLE Persons DROP CHECK chk_Person
五、索引
在不读取整个表的情况下,索引使数据库应用程序可以更快地查找数据。
用户无法看到索引,它们只能被用来加速搜索/查询。
为Persons表中的LastName, FirstName列做索引。
CREATE INDEX PIndex ON Persons (LastName, FirstName)
SQL函数
一、SQL Aggregate 函数
- 列平均值
AVG() - 返回某一列的平均值
SELECT site_id, count FROM access_log WHERE count > (SELECT AVG(count) FROM access_log);
- 列求和
SUM() - 返回总和
SELECT SUM(count) AS nums FROM access_log;
- 行数
COUNT() - 返回行数 - 因为是新列,当然需要AS。
SELECT COUNT(count) AS nums FROM access_log WHERE site_id=3;
- 行类别数
SELECT COUNT(DISTINCT site_id) AS nums FROM access_log;
- 首、尾
FIRST() - 返回第一个记录的值 - 使用Limit=1关键字
LAST() - 返回最后一个记录的值 - 使用ORDER BY id DESC,以及Limit=1
- 极大极小值
MAX() - 返回最大值,MIN() - 返回最小值
SELECT MAX(alexa) AS max_alexa FROM Websites; SELECT MIN(alexa) AS min_alexa FROM Websites;
二、GROUP BY 语句
- 一张表
Ref: SQL中Group By的使用【写得不错】
结合聚合函数,根据一个或多个列对结果集进行分组。
[1] 任务:根据 '类别' 统计各个 ‘类别' 的 '数量'。
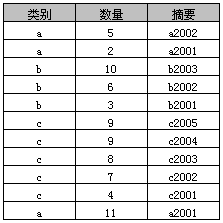
[2] 方案:注意这里把摘要撇在了一边儿。
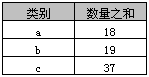
select 类别, sum(数量) as 数量之和 from A group by 类别
[3] 结果:实际上就是分类汇总。
- 两张表
Ref: http://www.runoob.com/sql/sql-groupby.html
[1] 任务:统计所有网站的访问的记录数。
[2] 方案:因为不想显示id,而是需要name,所以需要 LEFT JOIN websites表。
SELECT websites.name, COUNT(access_log.aid) AS nums FROM access_log 【GROUP BY site_id】
LEFT JOIN websites 【websites只是个给出site_id对应名字的参考表】
ON access_log.site_id=websites.id
GROUP BY websites.name;
三、HAVING 子句
- Having 与 Where 的区别
where 子句:是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。
having 子句:是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
- 分组之后的筛选
select 类别, sum(数量) as 数量之和 from A group by 类别 having sum(数量) > 18
一张表,分组后只需要 sum > 18 的。
- Having 和 Where 的联合使用
分组前筛选一次;分组后筛选一次。
select 类别, SUM(数量)from A where 数量 gt;8 group by 类别 having SUM(数量) gt; 10
四、COMPUTE
- 是什么
Ref: SQL中Group By的使用【写得不错】
compute子句能够观察“查询结果”的数据细节或统计各列数据(如例10中max、min和avg),返回结果由select列表和compute统计结果组成。
- 如何用
对阶段性结果表的再次以统计计算。
select * from A where 数量>8
compute max(数量),min(数量),avg(数量)
- 看结果

-
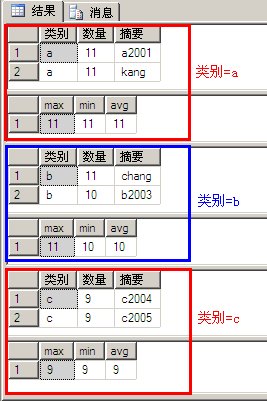
Compute ... By
select * from A where 数量>8
order by 类别
compute max(数量),min(数量),avg(数量) by 类别
执行结果:
五、SQL Scalar 函数
- 大小写转换
UCASE() - 将某个字段转换为大写;LCASE() - 将某个字段转换为小写
SELECT UCASE(name) AS site_title, url FROM Websites; SELECT LCASE(name) AS site_title, url FROM Websites;
- 字段部分显示
MID() - 从某个文本字段提取字符,MySql 中使用
SELECT MID(name,1,4) AS ShortTitle FROM Websites;
- 字段的长度
LENGTH() - 返回某个文本字段的长度
SELECT name, LENGTH(url) as LengthOfURL FROM Websites;
- 四舍五入
ROUND() - 对某个数值字段进行指定小数位数的四舍五入
返回参数X的四舍五入的有 D 位小数的一个数字。如果D为0,结果将没有小数点或小数部分。
mysql> select ROUND(1.298, 1); -> 1.3 mysql> select ROUND(1.298, 0); -> 1
- 当前时间
NOW() - 返回当前的系统日期和时间,日期加时间的完全格式。
SELECT name, url, Now() AS date FROM Websites;
FORMAT() - 格式化某个字段的显示方式,以自定义格式显示时间
SELECT name, url, DATE_FORMAT(Now(),'%Y-%m-%d') AS date FROM Websites;
扩展练习
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import pandas as pd # Please update .csv path here before running this .py. str_path = './data_analyst_sample_data.csv' cols = ["week_sold",'price','num_sold','store_id','product_code','department_name'] dataset=pd.read_csv(str_path,header=None, sep=',',names=cols) ####### # Q1 ####### total_price = 0.0 for i in range(1,len(dataset)): if (dataset['department_name'][i] == 'BEVERAGE'): each_price = float(dataset['price'][i]) * float(dataset['num_sold'][i]) each_price = round(each_price, 2) total_price += each_price print("Total price is %.2f" % total_price) print("") ############################################################################### # SELECT SUM(price*num_sold) AS sales FROM <table name> where department_name='BEVERAGE' ############################################################################### from collections import Counter total_counts = Counter() for i in range(1,len(dataset)): product_code = dataset['product_code'][i] total_counts[product_code] += 1 #print(total_counts) print("There are %d unique products in the store." % len(total_counts) ) print("") ############################################################################### # SELECT product_code, COUNT(*) FROM <table name> GROUP BY product_code ############################################################################### ####### # Q2 ####### from collections import Counter from decimal import * #from datetime import datetime #def convert_to_month(week_sold): # time_str = week_sold # time = datetime.strptime(time_str, '%Y-%m-%d') # return time.strftime('%Y-%m') total_counts = Counter() for i in range(1,len(dataset)): # month_sold = convert_to_month(dataset['week_sold'][i]) store_id = dataset['store_id'][i] product_code = dataset['product_code'][i] each_price = float(dataset['price'][i]) * float(dataset['num_sold'][i]) total_counts[store_id, product_code] += Decimal(each_price/3).quantize(Decimal('0.00')) print(total_counts) ############################################################################### # SELECT store_id, product_code, round(SUM(price*num_sold)/3.0, 2) FROM <table name> GROUP BY store_id ############################################################################### # Save import csv row = ['store_id', 'product_code', 'average_monthly_revenue'] out = open("result.csv", "a", newline = "") csv_writer = csv.writer(out, dialect = "excel") csv_writer.writerow(row) row = ['store_id', 'product_code', 'average_monthly_revenue'] for k, v in total_counts.items(): row = [k[0], k[1], v] out = open("result.csv", "a", newline = "") csv_writer = csv.writer(out, dialect = "excel") csv_writer.writerow(row)
高级特性
一、CASE...WHEN...[ELSE]...END
- 判断三角形类型
SELECT CASE WHEN A + B > C THEN
CASE
WHEN A = B AND B = C THEN 'Equilateral' WHEN A = B OR B = C OR A = C THEN 'Isosceles' WHEN A != B AND B != C OR A != C THEN 'SCALENE' END ELSE 'Not A Triangle' END FROM TRIANGLES;
- case 语句
SELECT id, (case sex
when ' ' then 'bbbbb' when null then 'aaaaa' else sex
end) as sex
FROM aa;
二、concat 拼接字符串
- "前后" 加括号
SELECT concat( NAME, concat("(",concat( substr(OCCUPATION,1,1), ")")) ) FROM OCCUPATIONS ORDER BY NAME ASC;
SELECT "There are a total of ", count(OCCUPATION), concat(lower(occupation),"s.") FROM OCCUPATIONS GROUP BY OCCUPATION ORDER BY count(OCCUPATION), OCCUPATION ASC
三、变量
- "横向" 列出来

set @r1=0, @r2=0, @r3=0, @r4=0; select min(Doctor), min(Professor), min(Singer), min(Actor) from( select case when Occupation='Doctor' then (@r1:=@r1+1) when Occupation='Professor' then (@r2:=@r2+1) when Occupation='Singer' then (@r3:=@r3+1) when Occupation='Actor' then (@r4:=@r4+1)
end as RowNumber,
case when Occupation='Doctor' then Name end as Doctor, case when Occupation='Professor' then Name end as Professor, case when Occupation='Singer' then Name end as Singer, case when Occupation='Actor' then Name end as Actor from OCCUPATIONS order by Name ) Temp group by RowNumber;
- 其他符号
一个以at符号(@)开头的标识符表示一个本地的变量或者参数。
一个以数字符号(#)开头的标识符代表一个临时表或者过程。
一个以两个数字符号(##)开头的标识符标识的是一个全局临时对象。
四、嵌套
SET sql_mode = ''; SELECT Start_Date, End_Date FROM (SELECT Start_Date FROM Projects WHERE Start_Date NOT IN (SELECT End_Date FROM Projects)) a, (SELECT End_Date FROM Projects WHERE End_Date NOT IN (SELECT Start_Date FROM Projects)) b
WHERE Start_Date < End_Date GROUP BY Start_Date ORDER BY DATEDIFF(End_Date, Start_Date), Start_Date
sql_mode="",即强制不设定MySql模式(如不作输入检测、错误提示、语法模式检查等)应该能提高性能,但有如下问题:
如果插入了不合适数据(错误类型或超常),mysql会将数据设为“最好的可能数据”而不报错,如:
| /数字 | 0/可能最小值/可能最大值 |
| /字符串 | 空串/能够存储的最大容量字符串 |
| /表达式 | 返回一个可用值(1/0-null) |
所以,解决办法是:所有列都要采用默认值,这对性能也好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号