LangChain Tutorial
第三讲 LLM模块
“一锤子”提问 vs 持续问答式提问
from langchain.llms import OpenAI import os os.environ['OPENAI_API_KEY'] = '您的有效OpenAI API Key' llm = OpenAI(model_name="text-davinci-003") response = llm.predict("What is AI?") print(response)
问答式有更丰富的“可控性”,如下。
from langchain.chat_models import ChatOpenAI from langchain.schema import AIMessage, HumanMessage, SystemMessage import os os.environ['OPENAI_API_KEY'] = '您的有效OpenAI API Key' chat = ChatOpenAI(temperature=0, model_name='gpt-3.5-turbo') response = chat.predict_messages([ HumanMessage(content="What is AI?") ]) print(response) response = chat.predict_messages([ SystemMessage(content="You are a chatbot that knows nothing about AI. When you are asked about AI, you must say 'I don\'t know'"), HumanMessage(content="What is deep learning?") ]) print(response)
任务生成
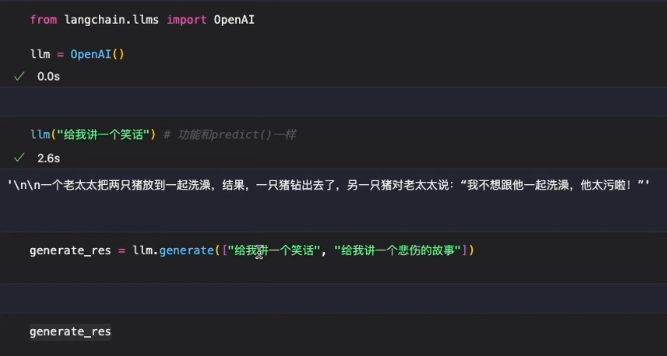
提示词模板
-
一次性赋值
from langchain import PromptTemplate multiple_input_prompt = PromptTemplate( input_variables=["color", "animal"], template="A {color} {animal} ." ) multiple_input_prompt.format(color="black", animal="bear") template = """ 你精通多种语言,是专业的翻译官。你负责{src_lang}到{dst_lang}的翻译工作。 """ prompt = PromptTemplate.from_template(template) # 自动解析出其中的变量 prompt.format(src_lang="英文", dst_lang="中文") # 然后使用
-
分步赋值
不同阶段,分次给模板赋值。
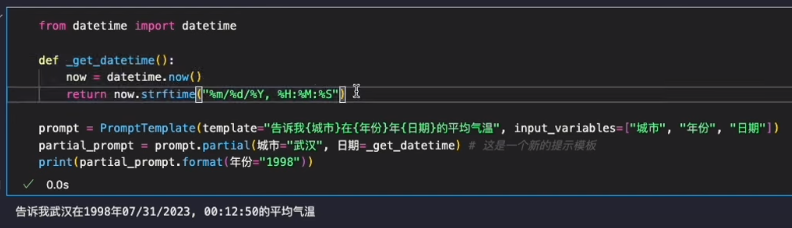
聊天提示词模板
得到的只是模板结果,之后还需要chain去具体执行 by integrating LLM with this template。
from langchain.prompts import ( ChatPromptTemplate, SystemMessagePromptTemplate, AIMessagePromptTemplate, HumanMessagePromptTemplate, ) system_template="You are a professional translator that translates {src_lang} to {dst_lang}." system_message_prompt = SystemMessagePromptTemplate.from_template(system_template) human_template="{user_input}" human_message_prompt = HumanMessagePromptTemplate.from_template(human_template) chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt]) chat_prompt.format_prompt( src_lang="English", dst_lang="Chinese", user_input="Did you eat in this morning?" ).to_messages()
[SystemMessage(content='You are a professional translator that translates English to Chinese.', additional_kwargs={}), HumanMessage(content='Did you eat in this morning?', additional_kwargs={}, example=False)]
少样本学习 FewShotPromptTemplate
这也算是大模型“开悟”的一个迷人特性。
-
examples

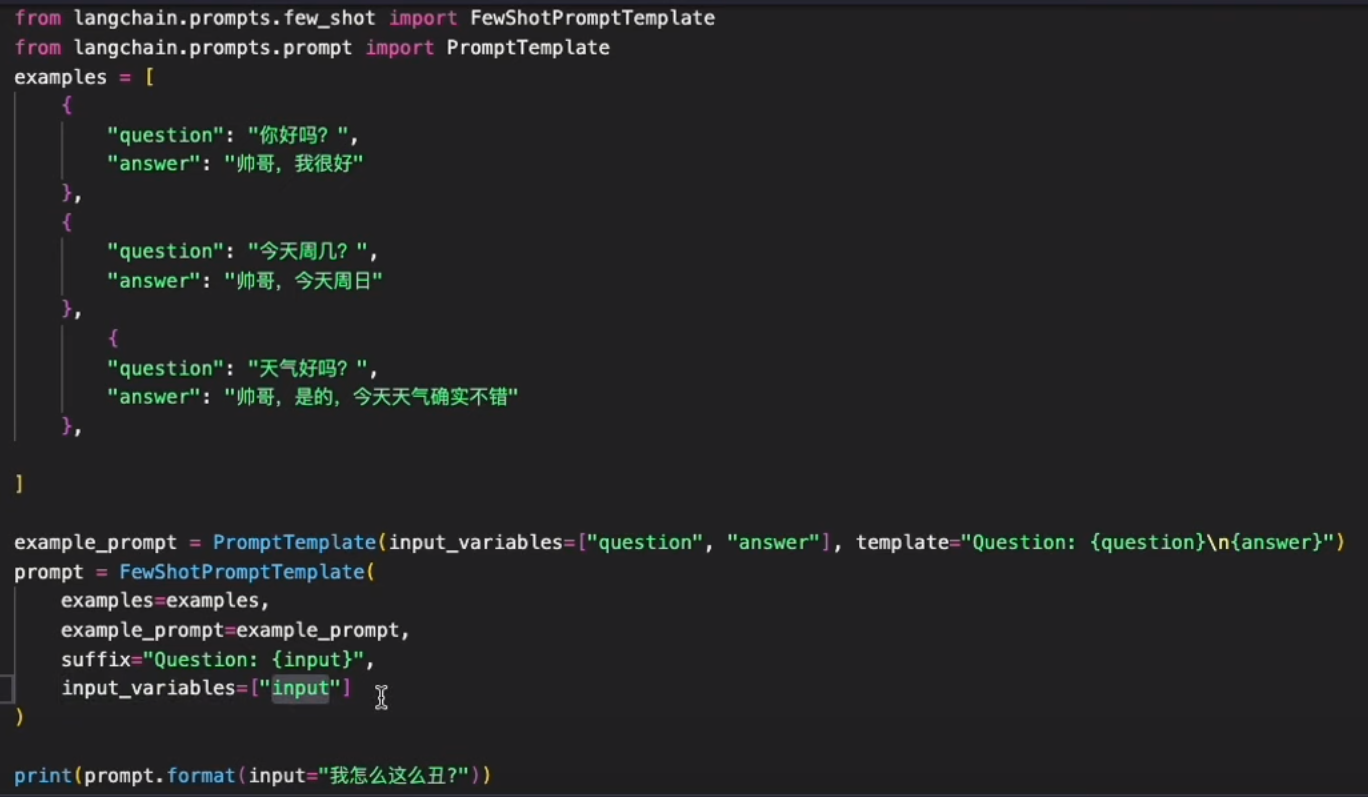
-
example + example_selector
这个设计,看似扯淡,参数交叉使用。。。 暂时不清楚有什么使用的必要性。
from langchain.prompts import PromptTemplate from langchain.prompts import FewShotPromptTemplate from langchain.prompts.example_selector import LengthBasedExampleSelector examples = [ {"input": "happy", "output": "sad"}, {"input": "tall", "output": "short"}, {"input": "energetic", "output": "lethargic"}, {"input": "sunny", "output": "gloomy"}, {"input": "windy", "output": "calm"}, ] example_prompt = PromptTemplate( input_variables=["input", "output"], template="Input: {input}\nOutput: {output}", ) example_selector = LengthBasedExampleSelector( # 可选的样本数据 examples=examples, # 提示词模版 example_prompt=example_prompt, # 格式化的样本数据的最大长度,通过get_text_length函数来衡量 max_length=4, # get_text_length: ... )
dynamic_prompt = FewShotPromptTemplate( example_selector=example_selector, example_prompt=example_prompt, prefix="Give the antonym of every input", suffix="Input: {adjective}\nOutput:", input_variables=["adjective"], ) # 输入量极小,因此所有样本数据都会被选中 print(dynamic_prompt.format(adjective="big"))
第四讲,数据连接
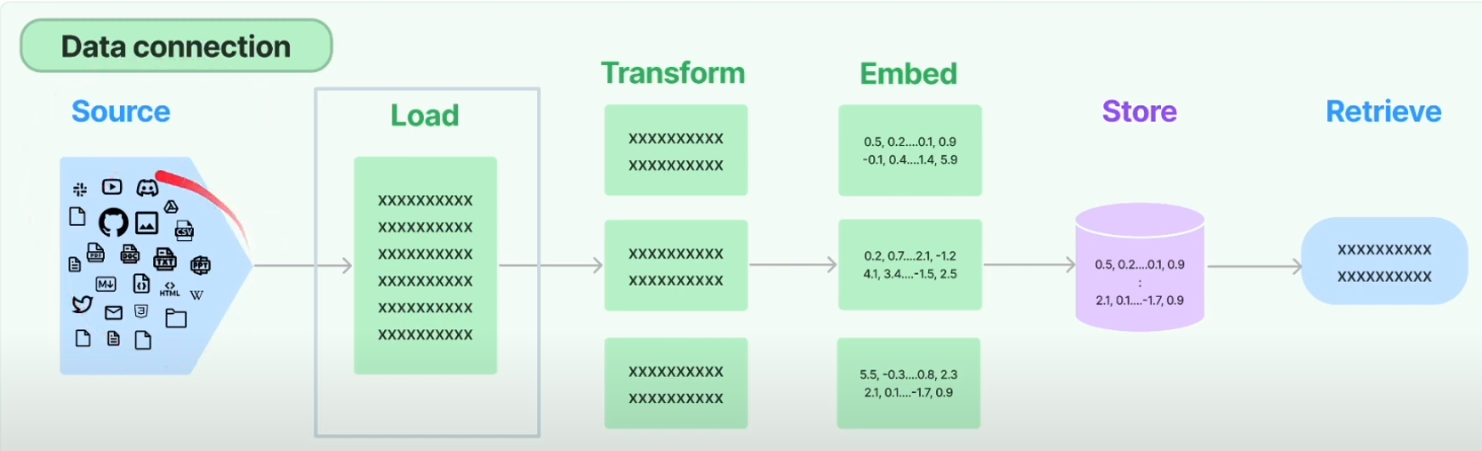
Load
结构化文件,直接加载并解析,得到例如字典类型的结构化数据。
非结构化数据,BiliBili, S3, etc.
Transform
更多的处理,例如“分割块”
Embed + Store + Retrieve
向量化。
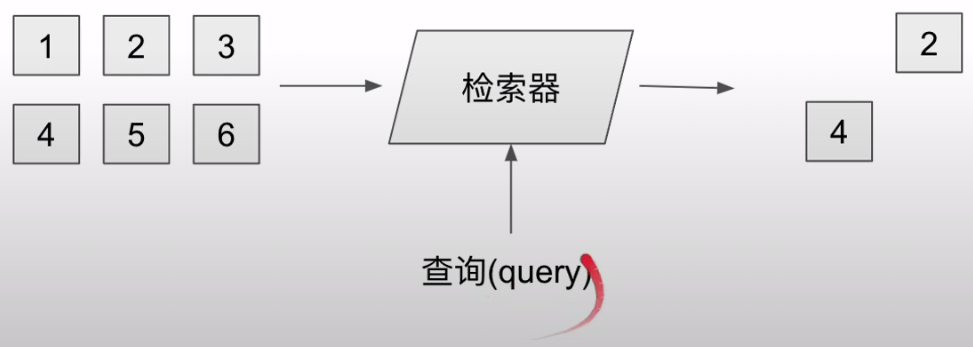
Ref: https://github.com/WTFAcademy/WTF-Langchain/blob/main/03_Data_Connections/03_Data_Connections.ipynb
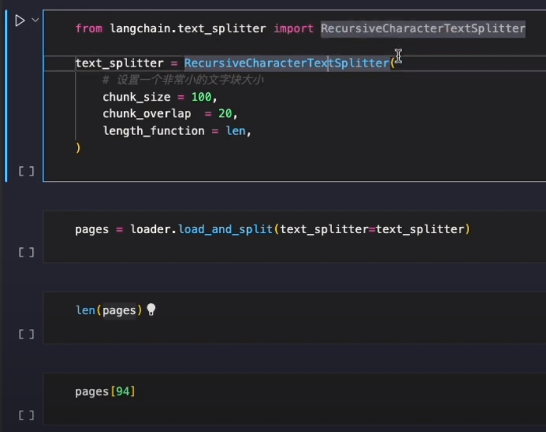
以上只适用于 text这一种,但分割还有很多类型的文档,所以更朴实的方式如下:
-
加载文档
from langchain.document_loaders import TextLoader loader = TextLoader("./README.md") docs = loader.load()
-
按字符拆分
from langchain.text_splitter import CharacterTextSplitter text_splitter = CharacterTextSplitter( separator = "\n\n", chunk_size = 1000, chunk_overlap = 200, length_function = len, ) split_docs = text_splitter.split_documents(docs) print(len(docs[0].page_content)) for split_doc in split_docs: print(len(split_doc.page_content))
-
拆分代码
from langchain.text_splitter import RecursiveCharacterTextSplitter, Language PYTHON_CODE = """ def hello_langchain(): print("Hello, Langchain!") # Call the function hello_langchain() """ python_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.PYTHON, chunk_size=50, chunk_overlap=0 ) python_docs = python_splitter.create_documents([PYTHON_CODE]) python_docs
-
Markdown文档拆分
from langchain.text_splitter import MarkdownHeaderTextSplitter markdown_document = "# Chapter 1\n\n ## Section 1\n\nHi this is the 1st section\n\nWelcome\n\n ### Module 1 \n\n Hi this is the first module \n\n ## Section 2\n\n Hi this is the 2nd section" headers_to_split_on = [ ("#", "Header 1"), ("##", "Header 2"), ("###", "Header 3"), ] splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on) splits = splitter.split_text(markdown_document) splits
-
按字符递归拆分
from langchain.text_splitter import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( chunk_size = 100, chunk_overlap = 20, length_function = len, ) texts = text_splitter.split_documents(docs) print(len(docs[0].page_content)) for split_doc in texts: print(len(split_doc.page_content))
-
按token拆分
from langchain.text_splitter import CharacterTextSplitter text_splitter = CharacterTextSplitter.from_tiktoken_encoder( chunk_size=100, chunk_overlap=0 ) split_docs = text_splitter.split_documents(docs) split_docs
-
向量化文档并分块
from langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(openai_api_key="") embeddings = embeddings_model.embed_documents( [ "你好!", "Langchain!", "你真棒!" ] ) embeddings
-
存储并检索
这里展示了一个“完整”的过程。
from langchain.document_loaders import TextLoader from langchain.embeddings.openai import OpenAIEmbeddings from langchain.text_splitter import CharacterTextSplitter from langchain.vectorstores import Chroma text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
splitted_documents = text_splitter.split_documents(docs)
db = Chroma.from_documents(splitted_documents, OpenAIEmbeddings(openai_api_key=""))
开始通过向量检索,因为向量是模型可以理解的语言。
query = "什么是WTF Langchain?" docs = db.similarity_search(query) docs docs = db.similarity_search_with_score(query) docs
第五讲 链结构

基础链结构
LLM chain
Router chain
Sequential chain
Transformation chain
应用链结构
Document chains
Retrieval QA
构造简单链 LLM chain
# from langchain.llms import OpenAI from langchain.prompts import PromptTemplate from langchain.chains import LLMChain from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(model_name="gpt-4-turbo", temperature=0, openai_api_key='sk-proj-saosile') prompt = PromptTemplate( input_variables=["color"], template="What is the relationship between US and {color}? Please answoer in Chinese.", ) chain = LLMChain(llm=llm, prompt=prompt) # <---- print(chain.run("China"))
导入链
from langchain.chains import load_chain import os os.environ['OPENAI_API_KEY'] = "您的有效openai api key" chain = load_chain("lc://chains/llm-math/chain.json") # <---- chain.run("whats the area of a circle with radius 2?")
多链结构 Router chain
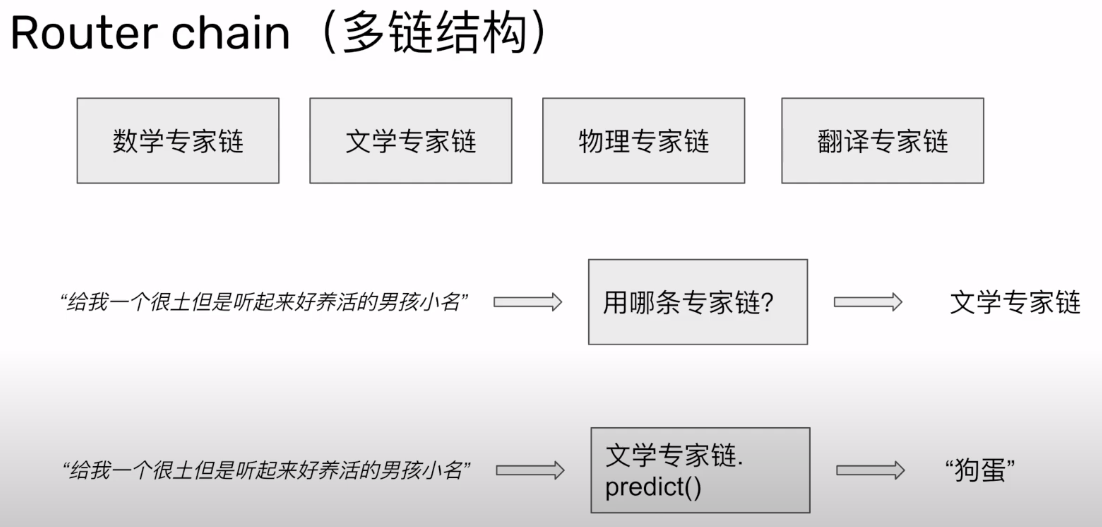
比较绕,但死记住这个模板即可~
from langchain.llms import OpenAI from langchain.prompts import PromptTemplate from langchain.chat_models import ChatOpenAI from langchain.chains import LLMChain from langchain.chains import ConversationChain from langchain.chains.router import MultiPromptChain from langchain.chains.router.llm_router import LLMRouterChain, RouterOutputParser from langchain.chains.router.multi_prompt_prompt import MULTI_PROMPT_ROUTER_TEMPLATE llm = ChatOpenAI(model_name="gpt-4-turbo", temperature=0, openai_api_key='sk-proj-laji') # 并行处理的工作流设计 naming_template = """你现在是一位武侠小说家,擅长起名字。 这里是问题: {input}""" math_template = """你现在是一位大学数学教授。 这里是问题: {input}""" const_prompt_infos = [ { "name": "naming", "description": "我是中文名字专家", "prompt_template": naming_template, }, { "name": "math", "description": "我是数学专家", "prompt_template": math_template, }, ] # ----------------------------------------- destination_chains = {} for p_info in const_prompt_infos: name = p_info["name"] prompt_template = p_info["prompt_template"] prompt = PromptTemplate(template=prompt_template, input_variables=["input"]) chain = LLMChain(llm=llm, prompt=prompt) <---- 初始化了一条“单链” # 这里准备好了这个destination_chains, 也就是2nd stage. destination_chains[name] = chain default_chain = ConversationChain(llm=llm, output_key="text")
#
# 构建 路由链
# destinations = [f"{p['name']}: {p['description']}" for p in const_prompt_infos] destinations_str = "\n".join(destinations) print(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>") print(destinations_str) router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(destinations=destinations_str) router_prompt = PromptTemplate( template=router_template, # <---- 提供了第一次路由的依据:description input_variables=["input"], output_parser=RouterOutputParser(), # <---- ) router_chain = LLMRouterChain.from_llm(llm, router_prompt) # 由 路由提示词 构成的 路由链 # 并行处理然后选择一个很好的,是么? # 这是一个 多提示词链 chain = MultiPromptChain( router_chain=router_chain, destination_chains=destination_chains, default_chain=default_chain, verbose=True, ) print(chain.run("给我一个很土但听起来比较好养活的男孩小名,比较传统的"))
多链结构 Sequential chain
可见如下,就是两个“单链”,然后通过 SimpleSequentialChain连接起来。

文本处理 Transformation chain
在處理 LLM 或資料流程時,經常需要進行一系列的資料轉換。這就是 Transformation Chain 發揮作用的地方。
Transformation Chain 是一個通用的轉換 chain ,可以幫助開發者在不更改原始資料的情況下,對其進行預處理或格式轉換,並且通常會搭配 Sequential Chain 使用。以下面這段程式碼為例,就是把輸入的文本只取前三段來使用。
def transform_func(inputs: dict): text = inputs["text"] shortened_text = "\n\n".join(text.split("\n\n")[:3]) return {"output_text": shortened_text} transform_chain = TransformChain( input_variables=["text"], output_variables=["output_text"], transform=transform_func )
Documentchain type 长文本处理链
-
Retrieval QA stuff type

-
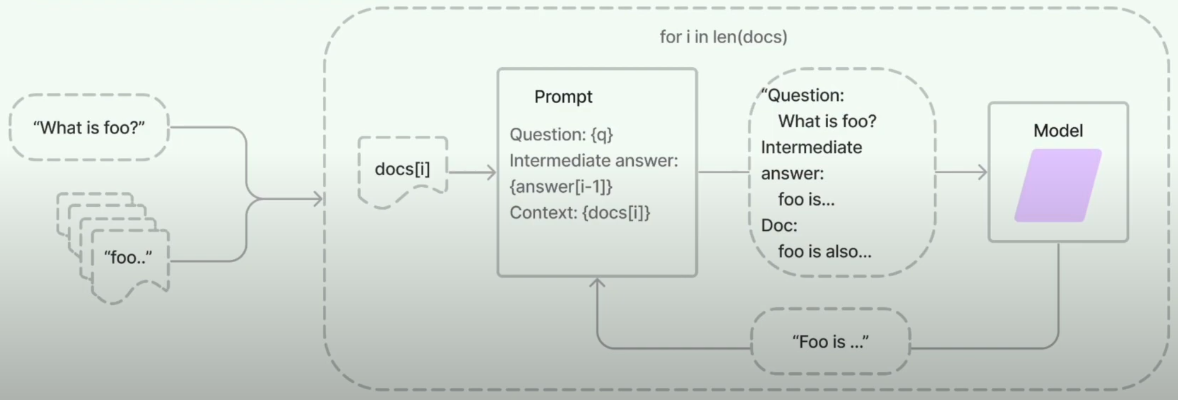
Refine type
-
Map reduce
Todo list.
-
Map rerank
Todo list.
第六讲 代理人模块 (重难点)
让 LLM 了解之前的对话内容。

Paper: https://research.google/blog/react-synergizing-reasoning-and-acting-in-language-models/
Paper: https://github.com/AGI-Edgerunners/Plan-and-Solve-Prompting
** 简单例子 **
[1] 这里初始化了一个agent,手持一个工具套件,里面有两个工具,一个搜索serpapi,以及另一个llm-math。
from langchain.agents import load_tools from langchain.agents import initialize_agent from langchain.llms import OpenAI llm = OpenAI(temperature=0) tools = load_tools(["serpapi", "llm-math"], llm=llm)
# What is a tool like this tools[1].name, tools[1].description agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
[2] 然后直接激活agent。Agent将自动在tools中找合适的去执行。
怎么感觉类似并行链?Router Chain. 或者说代理就是其封装后的实现?

以上这个简单的例子,看似跳过了很多中间步骤~
** 标准例子 **
Agent = LLM + MEM + TOOLs
#初始化 agent agent = initialize_agent( tools, # 配置工具集 llm, # 配置大语言模型 负责决策 agent=AgentType.OPENAI_FUNCTIONS, # 设置 agent 类型 https://python.langchain.com/docs/modules/agents/agent_types/openai_functions_agent verbose=True, agent_kwargs=agent_kwargs, # 设定 agent 角色 memory=memory, # 配置记忆模式 )
llm 的选择要匹配 AgentType.OPENAI_FUNCTIONS。
-
设定 agent 角色 by agent_kwargs
描述当前 agent 是个什么人。
https://flowgpt.com/ 会有各种agent的描述用于定义。
#初始话角色详细描述 system_message = SystemMessage( content="""You are a world class researcher, who can do detailed research on any topic and produce facts based results; you do not make things up, you will try as hard as possible to gather facts & data to back up the research Please make sure you complete the objective above with the following rules: 1/ You should do enough research to gather as much information as possible about the objective 2/ If there are url of relevant links & articles, you will scrape it to gather more information 3/ After scraping & search, you should think "is there any new things i should search & scraping based on the data I collected to increase research quality?" If answer is yes, continue; But don't do this more than 5 iteratins 4/ You should not make things up, you should only write facts & data that you have gathered 5/ In the final output, You should include all reference data & links to back up your research; You should include all reference data & links to back up your research 6/ In the final output, You should include all reference data & links to back up your research; You should include all reference data & links to back up your research""" )
#初始化 agent 角色模版 agent_kwargs = { "extra_prompt_messages": [MessagesPlaceholder(variable_name="memory")], "system_message": system_message, }
-
初始化“记忆”类型 by memory
#初始化记忆类型 memory = ConversationSummaryBufferMemory( memory_key="memory", return_messages=True, llm=llm, max_token_limit=300)
-
“工具” 初始化
在列表中,可见这里有两个工具。
#初始化 agent 可使用的工具集合 tools = [ Tool( name="Search", func=search, description="useful for when you need to answer questions about current events, data. You should ask targeted questions" ), ScrapeWebsiteTool(), ]
Tool 1 --> 第一种策略,通过API得到Google搜索结果。www.browserless.io
#调用 Google search by Serper def search(query): serper_google_url = os.getenv("SERPER_GOOGLE_URL") print(f"Serper Google Search URL: {serper_google_url}") payload = json.dumps({ "q": query }) headers = { 'X-API-KEY': serper_api_key, 'Content-Type': 'application/json' } response = requests.request("POST", serper_google_url, headers=headers, data=payload) print(f'Google 搜索结果: \n {response.text}') return response.text
Tool 2 --> 第二种策略,判断Google搜索结果中的“条目”,有价值的则 “进一步” 打开 进一步看细节。
class ScrapeWebsiteInput(BaseModel): """Inputs for scrape_website""" target: str = Field( description="The objective & task that users give to the agent") url: str = Field(description="The url of the website to be scraped") class ScrapeWebsiteTool(BaseTool): name = "scrape_website" description = "useful when you need to get data from a website url, passing both url and objective to the function; DO NOT make up any url, the url should only be from the search results" args_schema: Type[BaseModel] = ScrapeWebsiteInput def _run(self, target: str, url: str): return scrape_website(target, url) # ----> 进一步 浏览 web details def _arun(self, url: str): raise NotImplementedError("error here")
根据具体 URL 爬取网页内容,给出最终解答。
# 根据 url 爬取网页内容,给出最终解答。 # target :分配给 agent 的初始任务 # url : Agent 在完成以上目标时所需要的URL,完全由Agent自主决定并且选取,其内容或是中间步骤需要,或是最终解答需要 def scrape_website(target: str, url: str): print(f"开始爬取: {url}...") headers = { 'Cache-Control': 'no-cache', 'Content-Type': 'application/json', } payload = json.dumps({ "url": url }) post_url = f"https://chrome.browserless.io/content?token={browserless_api_key}" response = requests.post(post_url, headers=headers, data=payload) #如果返回成功 if response.status_code == 200: soup = BeautifulSoup(response.content, "html.parser") text = soup.get_text() print("爬取的具体内容:", text) #控制返回内容长度,如果内容太长就需要切片分别总结处理 if len(text) > 5000: #总结爬取的返回内容 output = summary(target, text) return output else: return text else: print(f"HTTP request failed with status code {response.status_code}")
趴取后总结网页内容。
# 如果需要处理的内容过长,先切片分别处理,再综合总结 # 使用 Map-Reduce 方式 def summary(target, content): #model list : https://platform.openai.com/docs/models # gpt-4-32k gpt-3.5-turbo-16k-0613 llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-16k-0613") #定义大文本切割器 # chunk_overlap 是一个在使用 OpenAI 的 GPT-3 或 GPT-4 API 时可能会遇到的参数,特别是当你需要处理长文本时。 # 该参数用于控制文本块(chunks)之间的重叠量。 # 上下文维护:重叠确保模型在处理后续块时有足够的上下文信息。 # 连贯性:它有助于生成更连贯和一致的输出,因为模型可以“记住”前一个块的部分内容。 text_splitter = RecursiveCharacterTextSplitter( separators=["\n\n", "\n"], chunk_size=5000, chunk_overlap=200) docs = text_splitter.create_documents([content]) map_prompt = """ Write a summary of the following text for {target}: "{text}" SUMMARY: """ map_prompt_template = PromptTemplate( template=map_prompt, input_variables=["text", "target"]) summary_chain = load_summarize_chain( # 长文本链处理 llm=llm, chain_type='map_reduce', map_prompt=map_prompt_template, combine_prompt=map_prompt_template, verbose=True ) output = summary_chain.run(input_documents=docs, target=target) return output
Agent 角色扮演构造数据集
Ref: CAMEL:角色扮演的Agent生成高质量对话数据集
CAMEL用于生成高质量对话,那么也可以生成剧场对话咯。对于剧场,重要的是冲突制造,例如左派右派对于同一个问题的探讨,主持人(导演)对于节奏的把控(作为admin的代理人)。
实践:剧本生成
这是结构化的结果。
[ Line(character="郭德纲", content="各位观众朋友们好,我是郭德纲。"), Line(character="于谦", content="我是于谦,郭老师的老搭档。"), Line(character="郭德纲", content="今天咱们聊聊悉尼西部的大动作,听说那边要开新机场,还没开呢,公交车线路都规划好了。"), Line(character="于谦", content="是啊,这不是有点儿本末倒置吗?机场还是图纸上的,公交车倒先跑起来了。"), Line(character="郭德纲", content="这叫先行先试,咱们这叫有备无患。不过听说这公交不仅要服务机场,还要连着周边社区,这是要把整个西悉尼变成一个大车站啊。"), Line(character="于谦", content="对,还有个叫布拉德菲尔德的地方,要建个新的换乘站和公交车总站。这名字听着就高大上,不知道到时候车站是不是也得高大上些。"), Line(character="郭德纲", content="高不高大上不知道,反正先得和地主老板们商量商量,毕竟人家的地你得先说好话。"), Line(character="于谦", content="这不就跟相亲一样,先得见家长,家长满意了,这婚事儿才好办。"), Line(character="郭德纲", content="说到底,这还是为了方便大家,到时候不仅有公交,还有地铁,连高速都不收费。"), Line(character="于谦", content="这可真是大手笔,不收费的高速在咱们这儿可不多见,这下可好,不用担心塞车,直接飞一样的感觉。"), Line(character="郭德纲", content="对,不过这飞的不是车,是人的心情。想想看,从家门口坐公交,转地铁,再到机场,全程无缝接驳,多美!"), Line(character="于谦", content="美是美,就怕到时候人多,咱们这美好的心情也得排队等候。"), Line(character="郭德纲", content="那也比堵在路上强,至少人在动,心情也跟着动。"), Line(character="于谦", content="说的也是,动心动情,这才是生活。对了,要是有兴趣了解更多,还可以去新南威尔士交通部的网站看看。"), Line(character="郭德纲", content="看来这次咱们不仅是聊天,还得当导游,带大家先睹为快啊。"), ]
关键函数设计。
def news2script(news): # 选好一个大模型 llm = ChatOpenAI( model_name="gpt-4-turbo", temperature=0, openai_api_key='sk-proj-hao123') # --------------------------------------------- # 构造一个 chain, 包括 llm + prompt template # --------------------------------------------- summary_prompt_template = """Summarize the news please: "{text}" 150 words in Chinese language. """ chinese_summary_prompt = PromptTemplate(template=summary_prompt_template, input_variables=["text"]) chain = load_summarize_chain(llm, prompt=chinese_summary_prompt) # Run!
summary = chain.run(doc) # 这里的参数就是“输入”
################################################################################################### # 生成对话的具备 by chat llm. ###################################################################################################
# 可以选个不同的模型 openaichat = ChatOpenAI( model_name="gpt-4-turbo", temperature=0, openai_api_key='sk-proj-hao123') xiangsheng_prompt_template = """\ 我将给你一段新闻的概括,请按照要求把这段新闻改写成郭德纲和于谦的对口相声剧本。 新闻:"{新闻}" 要求:"{要求}" {output_instructions} """ parser = PydanticOutputParser(pydantic_object=XiangSheng) # --> parser definition. ## xiangsheng_prompt = PromptTemplate.from_template(template=xiangsheng_prompt_template) xiangsheng_prompt = PromptTemplate( template=xiangsheng_prompt_template, input_variables=["新闻", "要求"], partial_variables={"output_instructions": parser.get_format_instructions()} ) # chat model 的参数需要的格式如下, and run! msg = [HumanMessage( content=xiangsheng_prompt.format(新闻=summary, 要求="风趣幽默,十分讽刺,对话剧本是郭德纲和于谦,以他们的自我介绍为开头"))] res = openaichat(msg) xiangsheng = parser.parse(res.content) return xiangsheng
其他部分,如下。
from langchain.document_loaders import UnstructuredURLLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.llms import OpenAI from langchain.chat_models import ChatOpenAI from langchain.prompts import PromptTemplate from langchain.schema import HumanMessage from langchain.output_parsers import PydanticOutputParser from langchain.chains.summarize import load_summarize_chain from pydantic import BaseModel, Field def url2News(url): text_splitter = RecursiveCharacterTextSplitter( separators=["Consultation about", "Share via"], chunk_size=1000, chunk_overlap=20, length_function=len) loader = UnstructuredURLLoader([url]) # data = loader.load() data = loader.load_and_split(text_splitter=text_splitter) return data[0:2] class Line(BaseModel): character: str = Field(description="说这句台词的角色名字") content: str = Field(description="台词的具体内容,其中不再包括角色的名字") class XiangSheng(BaseModel): script: list[Line] = Field(description="一段相声的台词剧本")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号