[face] Since 3D Morphable models (3DMM)
Ref: 基于FLAME的三维人脸重建技术总结
基本概念
3DMM
研究人员们在很早就提出了一个三维可形变人脸模型(即3D Morphable models),它的核心思想就是可以定义一组人脸作为基底人脸,然后任意一个人脸都可以由这组基底人脸线性加权得到。
1999年文章《A Morphable Model For The Synthesis Of 3D Faces》提出了建立人脸数据库的方法,但没有开源数据集;
Pascal Paysan等人在2009年使用激光扫描仪精确采集了200个人脸数据得到了Basel Face Model数据集,称作BFM数据集;另一个著名的数据集是2014年提出的FaceWarehouse,同样没有开源。(关于3DMM的详细细节可以参考知乎大V的这一篇文章:https://zhuanlan.zhihu.com/p/161828142)
但BFM数据集提供的人脸基地能够表征的人脸表情丰富度十分有限,于是马普所在2017年开源了FLAME,当下最准确、表情最丰富的开源人脸模型。
基于人脸图像的三维重建方法非常多,常见的包括
-
- 立体匹配,
- Structure From Motion(简称SfM),
- Shape from Shading(简称sfs),
- 三维可变形人脸模型(3DMM),
FLAME的表示
FLAME uses standard vertex based linear blend skinning (LBS) with corrective blendshapes, with N = 5023 vertices, K = 4 joints (neck, jaw, and eyeballs), and blendshapes, which will be learned from data.
从表示方式上来看,FLAME借鉴了身体模型SMPL的表示方式,基于LBS(linear blend skining)并结合blendshapes作为表示,包含5023个顶点,4个关节。
具体来说,FLAME将人头拆分成了左眼球、右眼球、下巴、脖子这四个部位,这四个部位都可以绕着自定义的“关节”进行旋转形成新的三维表示。
- LBS
LBS刻画的就是当部位与部位之间发生相对旋转时,连接处的顶点应该如何发生变化。其实这个名称取得非常清晰,linear blend skining直接翻译过来就是 线性混合蒙皮。
举个例子,下面的视频中两个圆柱代表两个人体部位,圆柱中间有一块骨骼(刚性),其他灰色的部分表示皮肤(柔性),然后它们可以绕着某个关节进行旋转。那么当两个圆柱完全成一定角度的时候,两个圆柱连接处的“皮肤”会发生拉伸,产生一些新的“皮肤”。通俗来讲,LBS就是刻画当骨骼发生相对旋转导致皮肤拉伸时,如何计算产生的新“皮肤”的位置。
- Blendshape:也称作"Morph target animation"
Blendshape就可以理解一个方法,而不是一个数据(它的名称有一定困惑性)。
- 前面提到FLAME等参数化模型可以让人脸的各个属性解耦合,
- Blendshape的输入就是每个属性的值,输出就是对应人脸模型怎么发生形变的,具体来说就是5023个顶点发生的偏移量。
DECA
FLAME模型的参数有三类:shape,pose,expression,
由于FLAME模型的上述各种优势,在NoW challenge(人脸重建)中,基于FLAME模型的方法基本已经形成碾压之势。下面我们来看看如何用FLAME来完成人脸重建这个任务,并介绍最近效果非常突出、比较 的三个工作:DECA、EMOCA、MICA。
我们以2021 SIGGRAPH的DECA这篇工作为例来详细介绍FLAME模型是如何用来重建三维人头的,然后简要介绍2022 CVPR的EMOCA以及2022 ECCV的MICA两个改进工作。
下面是整体的框架:
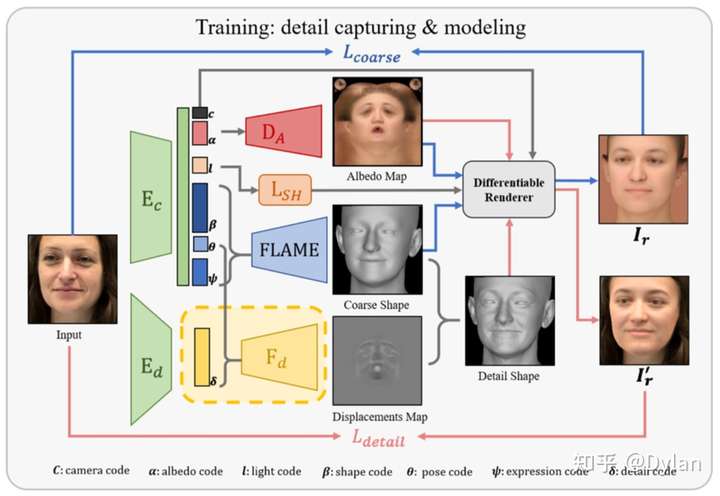
这篇文章的输入是单张图片:
- 经过两个不同的encoder和mapping网络,得到一系列的7个参数,包括:
- camera code,
- albedo code,
- light code,
- shape code,
- pose code,
- expression code,
- detail code;
- albedo code经过decoder生成texture;
- light code经过decoder得到光照系数;
- shape code, pose code, expression code 经过FLAME模型得到一个粗糙的人脸mesh表示;
- detail code经过decoder得到一个更精细化的mesh偏移作用在FLAME的输出上,得到一个更精细化的人脸表示(为了建模人脸上的皱纹等细节);
- 将texture、光照系数、mesh带入进行可微渲染,得到渲染图片;
- 在渲染图片上和原始图片进行比较,计算各种loss function,包括关键点的loss、图像的loss等等;
- 经过两个不同的encoder和mapping网络,得到一系列的7个参数,包括:
DECA的改进:EMOCA以及MICA
缺陷1. DECA虽然建模出比FLAME更精细的mesh,但在一些极端的表情上表现不是很好。
缺陷2. DECA和EMOCA都无法恢复人头的真实尺度,因为整个网络的训练框架是基于可微渲染,而相机的投影是一个相似矩阵,把头变大等效于把相机拉近(这一点等效于单目SLAM无法恢复尺度)
代码理解
Ref: https://github.com/NetEase-GameAI/Face2FaceRHO/blob/master/src/fitting.py
DECA的效果看起来也很牛逼,来自马普所的工作。可以说是行业老司机了。
这篇文章做的主要的事情是 将表情和皮肤去偶和,换句话说,任何表情都可以迁移到一个特定的人脸上。这应该是做虚拟主播非常有用的东西吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号