
[LLM] ASL-Signs
Ref: https://www.kaggle.com/markwijkhuizen/code
Google - Isolated Sign Language Recognition
背景知识
-
可视化
ASL Competition Drawing landmarks
250个类别,也不算多。
链接中如下代码可见,通过 please_sign_id 再到 path 再到 landmark文件,最后 "可视化"。
def show_sign(sign_id): landmark_path = train_df.query(f"sequence_id=={sign_id}").iloc[0,0] sign_df = pd.read_parquet(f"{BASE_PREFIX}/{landmark_path}") convert_landmarks_to_video(sign_id, sign_df) convert_video_to_gif(sign_id) ## sign sample: please please_sign_id = '1012730846' show_sign(please_sign_id)
-
编程基础
https://www.kaggle.com/code/pradhyumnbhale/transformer-model-training
Transformer Model Training中文注释版
--> 注意 “统计视频数据” 的代码部分:每个视频的 不同帧数、缺失帧数 和 最大帧数 的统计信息
--> MediaPipe holistic model 的模型的output解析代码也不错。
--> 从model config 开始 是核心技术
Need to implement transformer from scratch as TFLite does not support the native TF implementation of MultiHeadAttention.由于TFLite(TensorFlow Lite,一种针对移动和嵌入式设备进行优化的TensorFlow版本)不支持TensorFlow原生的MultiHeadAttention层实现,因此需要从头开始实现Transformer模型(一种在自然语言处理任务中使用的神经网络架构),其中包括MultiHeadAttention层。由于MultiHeadAttention层是Transformer模型的关键组成部分,因此如果TFLite不支持其实现,则可能无法在TFLite中使用TensorFlow中预先存在的Transformer实现。因此,需要自己编写Transformer的实现代码,而不依赖于TensorFlow中的MultiHeadAttention层的实现。
# Full Transformer class Transformer(tf.keras.Model): def __init__(self, num_blocks): super(Transformer, self).__init__(name='transformer') self.num_blocks = num_blocks def build(self, input_shape): self.ln_1s = [] self.mhas = [] self.ln_2s = [] self.mlps = [] # Make Transformer Blocks for i in range(self.num_blocks): # Multi Head Attention self.mhas.append(MultiHeadAttention(UNITS, 8)) # <---- Final embedding and transformer embedding size, 以及这里用到了8个block~ # Multi Layer Perception self.mlps.append(tf.keras.Sequential([ tf.keras.layers.Dense(UNITS * MLP_RATIO, activation=GELU, kernel_initializer=INIT_GLOROT_UNIFORM), tf.keras.layers.Dropout(MLP_DROPOUT_RATIO), tf.keras.layers.Dense(UNITS, kernel_initializer=INIT_HE_UNIFORM), ])) def call(self, x, attention_mask): # Iterate input over transformer blocks for mha, mlp in zip(self.mhas, self.mlps): x = x + mha(x, attention_mask) x = x + mlp(x) return x
# Based on: https://stackoverflow.com/ # Questions/67342988/verifying-the-implementation-of-multihead-attention-in-transformer # replaced softmax with softmax layer to support masked softmax # scaled dot-product attention是Transformer模型中的一种Attention机制,它是一种计算Attention权重的方法。 # 在这种方法中,Query和Key的点积被除以一个缩放因子,然后通过softmax函数进行归一化处理,最后与Value相乘得到Attention输出。 def scaled_dot_product(q,k,v, softmax, attention_mask): #calculates Q . K(transpose) qkt = tf.matmul(q,k,transpose_b=True) #caculates scaling factor dk = tf.math.sqrt(tf.cast(q.shape[-1],dtype=tf.float32)) scaled_qkt = qkt/dk softmax = softmax(scaled_qkt, mask=attention_mask) z = tf.matmul(softmax,v) #shape: (m,Tx,depth), same shape as q,k,v return z class MultiHeadAttention(tf.keras.layers.Layer): def __init__(self, d_model, num_of_heads): super(MultiHeadAttention,self).__init__() self.d_model = d_model self.num_of_heads = num_of_heads self.depth = d_model//num_of_heads self.wq = [tf.keras.layers.Dense(self.depth) for i in range(num_of_heads)] self.wk = [tf.keras.layers.Dense(self.depth) for i in range(num_of_heads)] self.wv = [tf.keras.layers.Dense(self.depth) for i in range(num_of_heads)] self.wo = tf.keras.layers.Dense(d_model) self.softmax = tf.keras.layers.Softmax() def call(self,x, attention_mask): multi_attn = [] for i in range(self.num_of_heads): Q = self.wq[i](x) K = self.wk[i](x) V = self.wv[i](x) multi_attn.append(scaled_dot_product(Q,K,V, self.softmax, attention_mask)) multi_head = tf.concat(multi_attn,axis=-1) multi_head_attention = self.wo(multi_head) return multi_head_attention
-
-
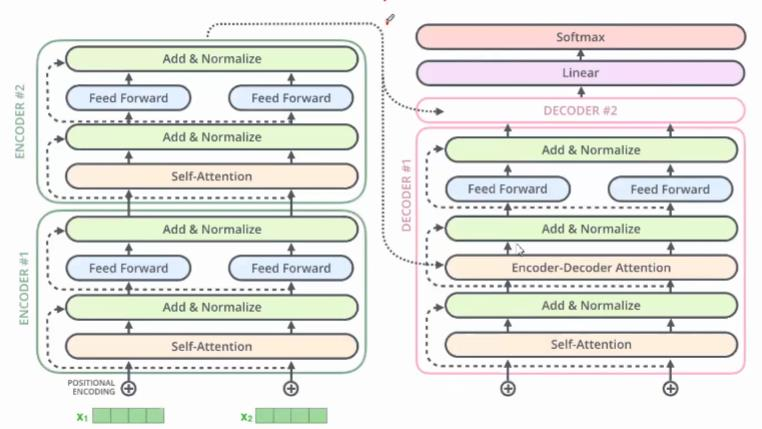
En-coder
-
Encoder部分是N个相同结构的堆叠,每个结构中又可以细分为如下结构:
- 1. 对输入 one-hot 编码的样本进行 embedding(词嵌入)
- 2. 加入位置编码
- 3. 引入多头机制的 Self-Attention
- 4. 将 self-attention 的输入和输出相加(残差网络结构)
- 5. Layer Normalization(层标准化),对所有时刻的数据进行标准化
- 6. 前馈型神经网络(Feedforword)结构
- 7. 将 Feedforword 的输入和输出相加(残差网络结构)
- 8. Layer Normalization,对所有时刻的数据进行标准化
重复N层 3-8 的结构
-
-
De-coder
-
Decoder部分同样也是N个相同结构的堆叠,每个结构中又可以细分为如下结构:
1. 对输入 one-hot 编码的样本进行 embedding(词嵌入) 2. 加入位置编码 3. 引入多头机制的 Self-Attention 4. 将 self-attention 的输入和输出相加(残差网络结构) 5. Layer Normalization(层标准化), 6. 对所有时刻的数据进行标准化将上一步得到的只作为value,并和编码器端得到 q和k进行Self-Attenton 7. 将 self-attention 的输入和输出相加(残差网络结构) 8. Layer Normalization(层标准化),对所有时刻的数据进行标准化 9. 前馈型神经网络(Feedforword) 结构 10. 将 Feedforword 的输入和输出相加(残差网络结构) 11. Layer Normalization,对所有时刻的数据进行标准化
重复N层 3-11 的结构
Landmark Embedding 是一种 将 人脸关键点信息 转换为 低维向量表示 的方法。


class LandmarkEmbedding(tf.keras.Model): def __init__(self, units, name): super(LandmarkEmbedding, self).__init__(name=f'{name}_embedding') self.units = units def build(self, input_shape): # Embedding for missing landmark in frame, initizlied with zeros self.empty_embedding = self.add_weight( name=f'{self.name}_empty_embedding', shape=[self.units], initializer=INIT_ZEROS, ) # Embedding self.dense = tf.keras.Sequential([ tf.keras.layers.Dense(self.units, name=f'{self.name}_dense_1', use_bias=False, kernel_initializer=INIT_GLOROT_UNIFORM), tf.keras.layers.Activation(GELU), tf.keras.layers.Dense(self.units, name=f'{self.name}_dense_2', use_bias=False, kernel_initializer=INIT_HE_UNIFORM), ], name=f'{self.name}_dense') def call(self, x): return tf.where( # Checks whether landmark is missing in frame tf.reduce_sum(x, axis=2, keepdims=True) == 0, # If so, the empty embedding is used self.empty_embedding, # Otherwise the landmark data is embedded self.dense(x), )
class Embedding(tf.keras.Model):
def __init__(self): super(Embedding, self).__init__() def get_diffs(self, l): S = l.shape[2] other = tf.expand_dims(l, 3) other = tf.repeat(other, S, axis=3) other = tf.transpose(other, [0,1,3,2]) diffs = tf.expand_dims(l, 3) - other diffs = tf.reshape(diffs, [-1, INPUT_SIZE, S*S]) return diffs def build(self, input_shape): # Positional Embedding, initialized with zeros self.positional_embedding = tf.keras.layers.Embedding(INPUT_SIZE+1, UNITS, embeddings_initializer=INIT_ZEROS)
# Embedding layer for Landmarks self.lips_embedding = LandmarkEmbedding(LIPS_UNITS, 'lips') self.left_hand_embedding = LandmarkEmbedding(HANDS_UNITS, 'left_hand') self.pose_embedding = LandmarkEmbedding(POSE_UNITS, 'pose')
# Landmark Weights self.landmark_weights = tf.Variable(tf.zeros([3], dtype=tf.float32), name='landmark_weights')
# Fully Connected Layers for combined landmarks self.fc = tf.keras.Sequential([ tf.keras.layers.Dense(UNITS, name='fully_connected_1', use_bias=False, kernel_initializer=INIT_GLOROT_UNIFORM), tf.keras.layers.Activation(GELU), tf.keras.layers.Dense(UNITS, name='fully_connected_2', use_bias=False, kernel_initializer=INIT_HE_UNIFORM), ], name='fc') def call(self, lips0, left_hand0, pose0, non_empty_frame_idxs, training=False): # Lips lips_embedding = self.lips_embedding(lips0) # Left Hand left_hand_embedding = self.left_hand_embedding(left_hand0) # Pose pose_embedding = self.pose_embedding(pose0)
# Merge Embeddings of all landmarks with mean pooling x = tf.stack(( lips_embedding, left_hand_embedding, pose_embedding, ), axis=3)
x = x * tf.nn.softmax(self.landmark_weights) x = tf.reduce_sum(x, axis=3) # Fully Connected Layers x = self.fc(x) # Add Positional Embedding max_frame_idxs = tf.clip_by_value( tf.reduce_max(non_empty_frame_idxs, axis=1, keepdims=True), 1, np.PINF, ) normalised_non_empty_frame_idxs = tf.where( tf.math.equal(non_empty_frame_idxs, -1.0), INPUT_SIZE, tf.cast( non_empty_frame_idxs / max_frame_idxs * INPUT_SIZE, tf.int32, ), ) x = x + self.positional_embedding(normalised_non_empty_frame_idxs) return x
-
构建 以及 训练模型
if TRAIN_MODEL: # Clear all models in GPU tf.keras.backend.clear_session() # Get new fresh model model =get_model() # ----> # Sanity Check model.summary() # Actual Training history = model.fit( x=get_train_batch_all_signs(X_train, y_train, NON_EMPTY_FRAME_IDXS_TRAIN), steps_per_epoch=len(X_train) // (NUM_CLASSES * BATCH_ALL_SIGNS_N), epochs=N_EPOCHS, # Only used for validation data since training data is a generator # "只用于验证数据,因为训练数据是生成器"。 # 如果使用生成器来训练模型,则必须使用验证数据来评估模型的性能。 # 这是因为生成器在每个时期中都会生成新的数据,而不是将所有数据加载到内存中。 # 因此,无法在训练期间使用训练数据来评估模型的性能。相反,必须使用验证数据来评估模型的性能. batch_size=BATCH_SIZE, validation_data=validation_data, callbacks=[ lr_callback, WeightDecayCallback(), ], verbose = 2, )
构建模型如下所示:
def get_model():
# Inputs frames = tf.keras.layers.Input([INPUT_SIZE, N_COLS, N_DIMS], dtype=tf.float32, name='frames') non_empty_frame_idxs = tf.keras.layers.Input([INPUT_SIZE], dtype=tf.float32, name='non_empty_frame_idxs')
# Padding Mask mask0 = tf.cast(tf.math.not_equal(non_empty_frame_idxs, -1), tf.float32) mask0 = tf.expand_dims(mask0, axis=2)
# Random Frame Masking mask = tf.where( (tf.random.uniform(tf.shape(mask0)) > 0.25) & tf.math.not_equal(mask0, 0.0), 1.0, 0.0, )
# Correct Samples Which are all masked now... mask = tf.where( tf.math.equal(tf.reduce_sum(mask, axis=[1,2], keepdims=True), 0.0), mask0, mask, ) """ left_hand: 468:489 pose: 489:522 right_hand: 522:543 """ x = frames x = tf.slice(x, [0,0,0,0], [-1,INPUT_SIZE, N_COLS, 2])
# LIPS lips = tf.slice(x, [0,0,LIPS_START,0], [-1,INPUT_SIZE, 40, 2]) lips = tf.where( tf.math.equal(lips, 0.0), 0.0, (lips - LIPS_MEAN) / LIPS_STD, ) # LEFT HAND left_hand = tf.slice(x, [0,0,40,0], [-1,INPUT_SIZE, 21, 2]) left_hand = tf.where( tf.math.equal(left_hand, 0.0), 0.0, (left_hand - LEFT_HANDS_MEAN) / LEFT_HANDS_STD, ) # POSE pose = tf.slice(x, [0,0,61,0], [-1,INPUT_SIZE, 5, 2]) pose = tf.where( tf.math.equal(pose, 0.0), 0.0, (pose - POSE_MEAN) / POSE_STD, ) # Flatten lips = tf.reshape(lips, [-1, INPUT_SIZE, 40*2]) left_hand = tf.reshape(left_hand, [-1, INPUT_SIZE, 21*2]) pose = tf.reshape(pose, [-1, INPUT_SIZE, 5*2]) # Embedding x = Embedding()(lips, left_hand, pose, non_empty_frame_idxs) # Encoder Transformer Blocks x = Transformer(NUM_BLOCKS)(x, mask) # Pooling x = tf.reduce_sum(x * mask, axis=1) / tf.reduce_sum(mask, axis=1) # Classifier Dropout x = tf.keras.layers.Dropout(CLASSIFIER_DROPOUT_RATIO)(x) # Classification Layer x = tf.keras.layers.Dense(NUM_CLASSES, activation=tf.keras.activations.softmax, kernel_initializer=INIT_GLOROT_UNIFORM)(x) outputs = x # Create Tensorflow Model model = tf.keras.models.Model(inputs=[frames, non_empty_frame_idxs], outputs=outputs) # Sparse Categorical Cross Entropy With Label Smoothing loss = scce_with_ls #SGDW是一种优化器,它是基于SGD的,但是加入了动量的概念。 #动量的作用是在更新参数时,不仅仅减去了当前迭代的梯度,还减去了前t-1迭代的梯度的加权和。 #这样做的好处是可以让参数更新更加平滑,避免了在参数更新过程中出现震荡的情况。 #optimizer = tfa.optimizers.SGDW( #learning_rate=lr, weight_decay=wd, momentum=0.9) #optimizer = tf.keras.optimizers.SGD(lr=0.001, momentum=0.0, nesterov=False) #optimizer = tfa.optimizers.SGDW(learning_rate=0.001, momentum=0.7, weight_decay=0.005) #Adam Optimizer with weight decay optimizer = tfa.optimizers.AdamW(learning_rate=1e-3, weight_decay=1e-5, clipnorm=1.0) #学习率为1e-3,权重衰减为1e-5,梯度裁剪阈值为1.0 # TopK Metrics metrics = [ tf.keras.metrics.SparseCategoricalAccuracy(name='acc'), tf.keras.metrics.SparseTopKCategoricalAccuracy(k=5, name='top_5_acc'), tf.keras.metrics.SparseTopKCategoricalAccuracy(k=10, name='top_10_acc'), ] model.compile(loss=loss, optimizer=optimizer, metrics=metrics) return model
优秀的方案
1st place solution - training [code]
1st place code with reproducibility [code]
1st place solution - 1DCNN combined with Transformer
-
1D CNN vs. Transformer? 融合
def get_model(max_len=64, dropout_step=0, dim=192): inp = tf.keras.Input((max_len,CHANNELS)) x = tf.keras.layers.Masking(mask_value=PAD,input_shape=(max_len,CHANNELS))(inp) ksize = 17 x = tf.keras.layers.Dense(dim, use_bias=False,name='stem_conv')(x) x = tf.keras.layers.BatchNormalization(momentum=0.95,name='stem_bn')(x) x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x) x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x) x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x) x = TransformerBlock(dim,expand=2)(x) x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x) x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x) x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x) x = TransformerBlock(dim,expand=2)(x) if dim == 384: # for the 4x sized model x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x) x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x) x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x) x = TransformerBlock(dim,expand=2)(x) x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x) x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x) x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x) x = TransformerBlock(dim,expand=2)(x) x = tf.keras.layers.Dense(dim*2,activation=None,name='top_conv')(x) x = tf.keras.layers.GlobalAveragePooling1D()(x) x = LateDropout(0.8, start_step=dropout_step)(x) x = tf.keras.layers.Dense(NUM_CLASSES,name='classifier')(x) return tf.keras.Model(inp, x)
-
Regularization
All three methods had a significant impact on both CV and leaderboard scores, and removing any one of them led to noticeable performance drops.
- Drop Path(stochastic depth, p=0.2)
- high rate of Dropout (p=0.8)
- AWP(Adversarial Weight Perturbation, with lambda = 0.2)
-
归一化
-
训练
Epoch = 400
| Cloud TPU type v2 Device | v2 cores | Chips | VMs | Total memory |
|---|---|---|---|---|
| v2-8 | 8 | 4 | 1 | 64 GiB |
ASLFR - Transformer Training + Inference
ASLFR - Transformer Training + Inference [中文注释]
Ref: https://github.com/jeffreyhaoau/aslfr/blob/main/aslfr-eda-preprocessing-dataset.ipynb
在此之前,使用的预处理数据,先分析“数据预处理”。
The processing is as follows:
-
Select the dominant hand based on the most number of non-empty hand frames
-
Filter out all frames with missing dominant hand coordinates
-
Resize video to 256 frames
File: ./asl-fingerspelling/character_to_prediction_index.json, 共59个字符。
自定义并添加了一个新列:phrase_type。
train['phrase_type'] = train['phrase'].apply(get_phrase_type)
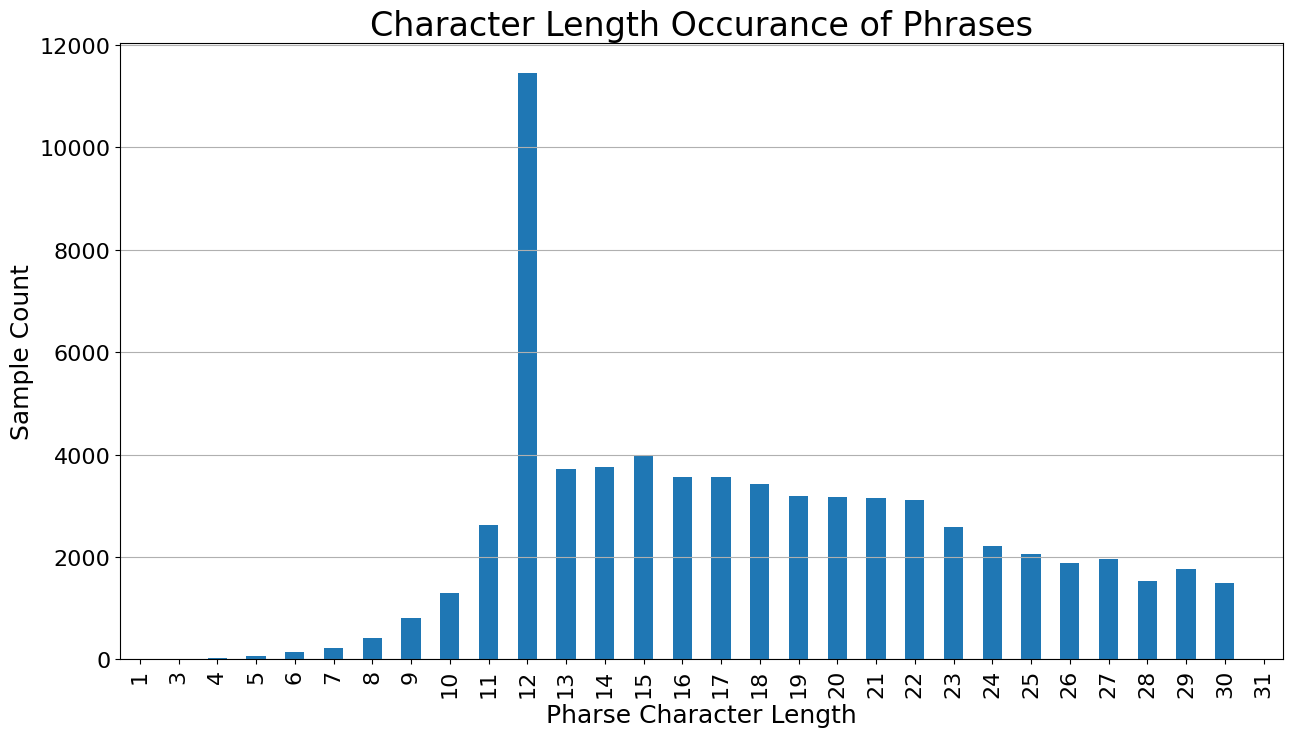
对 phrase 进行了一次统计如下。
| phrase_char_len | |
|---|---|
| count | 67208.0 |
| mean | 17.8 |
| std | 5.7 |
| min | 1.0 |
| 1% | 8.0 |
| 5% | 11.0 |
| 10% | 12.0 |
| 25% | 12.0 |
| 50% | 17.0 |
| 75% | 22.0 |
| 90% | 27.0 |
| 95% | 28.0 |
| 99% | 30.0 |
| 99.9% | 30.0 |
| max | 31.0 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号