[LLM] GPT,GPT-2,GPT-3 to InstructGPT
GPT1: Improving Language Understanding by Generative Pre-Training
GPT2: language_models_are_unsupervised_multitask_learners
GPT3: language-models-are-few-shot-learners-Paper
(2021 Feb 发布的CLIP)
针对GPT-1的问题,GPT-2作了如下改进: 去掉了fine-tuning层;并尝试 Zero-shot Learning(更大的数据集)。
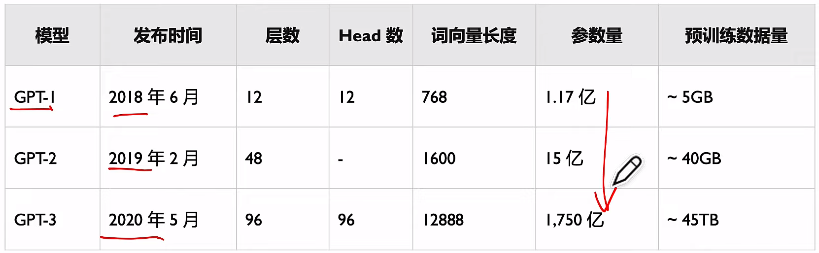
以下是GPT初代,只有Decoder + Fine-tuning。
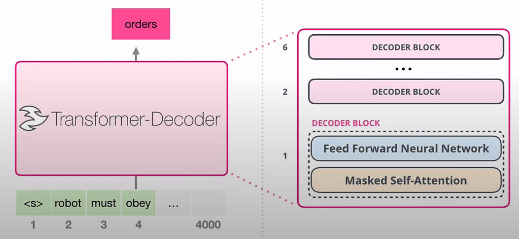
GPT3,引入新范式 prompt,有了“交互”的设计。(怎么感觉有了多模态的感觉)
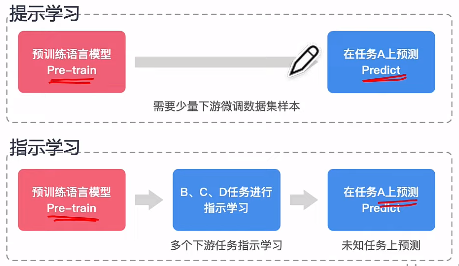
Instruct Learning 与 Prompt learning 有什么区别?
一个是 理解能力,一个是 补全能力。
前者的特点是什么?

- 强化学习 RLHF
通过强化学习微调神经网络?
有了以上的基础和背景知识,以下才好继续深入理解InstructGPT。
从 GPT3 到 SFT。

从 SFT 到 RM。

利用 RM 去评价,而非人工打分;然后更新模型 by PPO。

后来的开源模型也是Transformer's decoder + fine tuning的模式么?Yes!
开源多模态大模型哪家强?TOP12榜单来了,GitHub揽获2.2k+星
BLIP-2 貌似比较牛逼。
BLIP(Bootstrapping Language-Image Pretraining)是salesforce在2022年提出的多模态框架,是理解和生成的统一,引入了跨模态的编码器和解码器,实现了跨模态信息流动,在多项视觉和语言任务取得SOTA。
这应该是GPT4 与多模态分支相交后,再考虑。
Meta 发布大语言模型 LLaMA,它的来源和能力与 GPT 对比有什么特点?
- 模型结构和训练方法(总体类似gpt-3、PaLM架构,那就都是decoder架构, 作为AI系统工程师,这几个优化的工作倒是值得深入看看的)
- the modifications we made to the transformer architecture(模型结构微调主要把近期一些改进工作融合进来,但是论文没有讲这些参数的影响,没有做类似的对比实验,感觉模型结构方面的工作都还比较粗糙,赶紧追着去搞更大数据集去提高模型上限,刷性能)
- RMSNorm normalizing Pre-normalization, byGPT-3
- SwiGLU activation, by PaLM
- Rotary embedding, by GPTNeo
- 训练方法
- AdamW
- cosine learning rate schedule
- weight decay of 0.1 and gradient clipping of 1.0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号