
[diffusion] Video Diffusion
Video Diffusion 的发展脉络学习。
资源一
hu-po channel: Video Diffusion
Video Generation 也出现的比较早,紧跟着 Image Generation 的步伐~
-
Video Diffusion
Video Diffusion Models
如下,video diffusion 比 image diffusion 晚大概四个月。
-
Image Diffusion
Ref: High-Resolution Image Synthesis with Latent Diffusion Models
High-Resolution Image Synthesis with Latent Diffusion Models
资源二
Ref: 视频生成-Animater diffusion和 A Survey on Video Diffusion Models的研究分享 [B站]
论文追踪:https://github.com/ChenHsing/Awesome-Video-Diffusion-Models
阅读笔记,1小时56分钟。
-
General Text-to-video Generation
第一步,希望只学到 高质量的 feature。所以先训练一个 domain adapter。
第二步,才利用video 训练 motion module(运动建模模块)。
第三步,可选,在 motion module 上加 adapter layer 快速得到新的pattern 上。
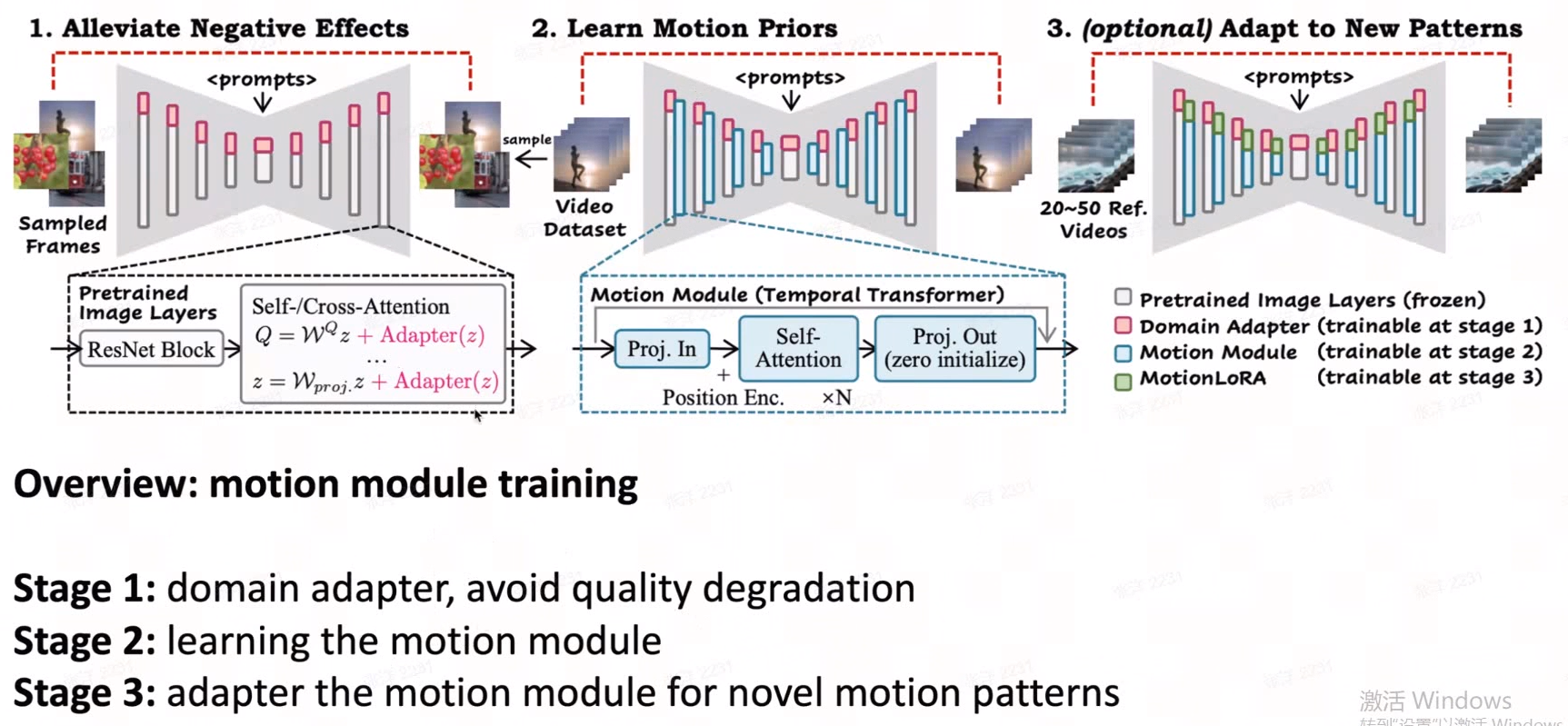
39:30开始
A Survey on Video Diffusion Models.
2022年只有14篇,开山之年。
CogVideo 基于自回归方案:https://github.com/THUDM/CogVideo,但效果不满意。
之后是基于Diffusion 的方案,例如 VDM,没有基于 “隐藏变量”,改为用 3D convolution。
Nvidia 的基于 “隐空间” 的 LDM方案:Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models(效果开始不错,但太模糊)
【黎明】
AnimateDiff: AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning, 2023.7
简单来说,就是在冻结的文生图模型中附加一个新初始化的 "运动建模模块",
然后用视频片段数据集对 "运动建模模块" 进行训练,以提炼出合理的运动先验。
训练完成后,只需往文生图模型中插入该 "运动建模模块",文生图模型就能轻松成为文本驱动的视频生成模型,生成多样化和个性化的动画图像。
【曙光】
Diffusion-based T2V Methods (LLM guided) 文本的理解能力受限,论文链接,2023.8(证明了text质量的重要性)
【日出】
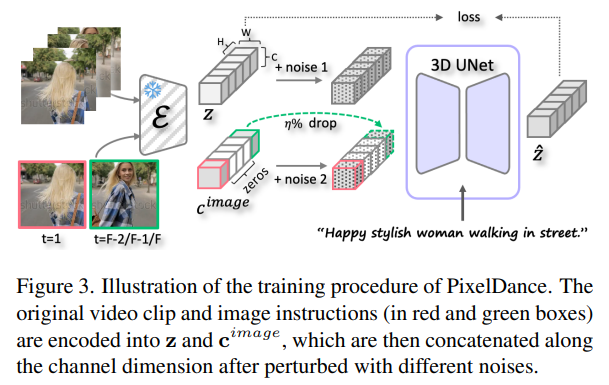
Make Pixels Dance 首尾帧作为 condition,再继续根据文字生成中间的部分。生成质量有很大的改善。Submitted on 18 Nov 2023 [看好,但不开源]
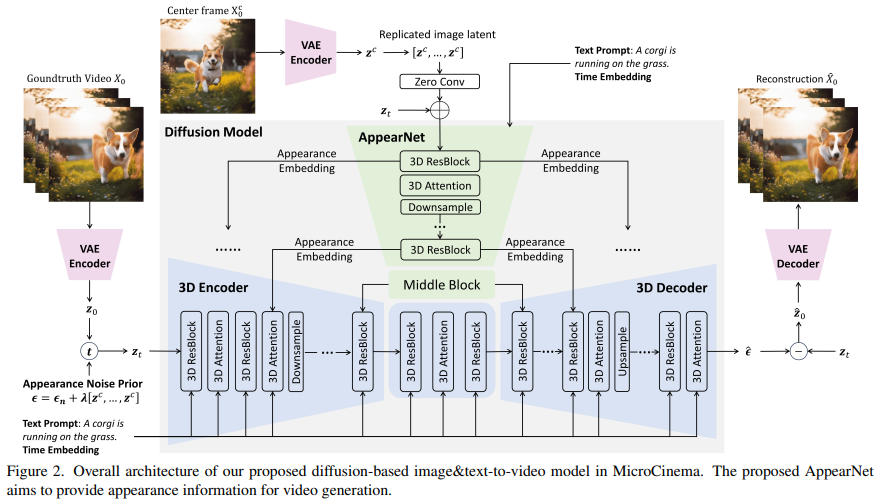
MicroCinema: A Divide-and-Conquer Approach for Text-to-Video Generation, Submitted on 30 Nov 2023
我们介绍了MicroCinema,这是一个简单而有效的框架,用于生成高质量和连贯的文本到视频。与直接将文本提示与视频对齐的现有方法不同,MicroCinema引入了一种分而治之的策略,将文本到视频分为两个阶段的过程:文本到图像生成 和 图像&文本到视频生成。
这种策略提供了两个重要的优点。
a)它使我们能够充分利用文本到图像模型的最新进展,例如Stable Diffusion,Midjourney和DALLE,以生成逼真且高度详细的图像。
b)利用生成的图像,模型可以将更少的注意力集中在细粒度的外观细节上,优先考虑运动动力学的高效学习。
为了有效实施这种策略,我们引入了两个核心设计。首先,我们提出了Appearance Injection Network,增强了给定图像外观的保留。其次,我们引入了Appearance Noise Prior,这是一种旨在保持预训练2D扩散模型能力的新颖机制。这些设计元素使MicroCinema能够生成具有精确运动的高质量视频,由提供的文本提示指导。广泛的实验证明了所提出框架的优越性。具体而言,MicroCinema在UCF-101上实现了342.86的SOTA zero-shot FVD,在MSR-VTT上实现了377.401。
两个可考虑的开源方案
Stable Video Diffusion (SVD), 21 Nov
分析:Stable Video Diffusion — Convert Text and Images to Videos
HiGen: Hierarchical Spatio-temporal Decoupling for Text-to-Video Generation,[Submitted on 7 Dec 2023] # 看上去可以对标 Pika
Todo
For more, please check: Awesome Video Diffusion
Video Editing 更可能是商业化的方向。
-
FlowVid: Taming Imperfect Optical Flows for Consistent Video-to-Video Synthesis (Jan., 2024)
-
Fairy: Fast Parallelized Instruction-Guided Video-to-Video Synthesis (Dec., 2023)
-
RealCraft: Attention Control as A Solution for Zero-shot Long Video Editing (Dec., 2023)
-
VidToMe: Video Token Merging for Zero-Shot Video Editing (Dec., 2023)
- 变身为雕像,有点意思
- 变身为雕像,有点意思
-
A Video is Worth 256 Bases: Spatial-Temporal Expectation-Maximization Inversion for Zero-Shot Video Editing (Dec., 2023)
-
Neutral Editing Framework for Diffusion-based Video Editing (Dec., 2023)
-
DiffusionAtlas: High-Fidelity Consistent Diffusion Video Editing (Dec., 2023)
-
RAVE: Randomized Noise Shuffling for Fast and Consistent Video Editing with Diffusion Models (Dec., 2023)
- 效果看上不错的样子,适合主播
-
SAVE: Protagonist Diversification with Structure Agnostic Video Editing (Dec., 2023)
-
MagicStick: Controllable Video Editing via Control Handle Transformations (Dec., 2023)
-
VideoSwap: Customized Video Subject Swapping with Interactive Semantic Point Correspondence (Dec., 2023)
-
DragVideo: Interactive Drag-style Video Editing (Dec., 2023)
-
Drag-A-Video: Non-rigid Video Editing with Point-based Interaction (Dec., 2023)
- 光流作为labeling策略
-
BIVDiff: A Training-Free Framework for General-Purpose Video Synthesis via Bridging Image and Video Diffusion Models (Dec., 2023)
-
VMC: Video Motion Customization using Temporal Attention Adaption for Text-to-Video Diffusion Models (Dec., 2023)
- style transfer, controlnet这种思路貌似也是不错的电影制作方案。
-
MotionEditor: Editing Video Motion via Content-Aware Diffusion (Nov., 2023)
- 有点类似 Animate Anyone
-
Motion-Conditioned Image Animation for Video Editing (Nov., 2023)
-
Space-Time Diffusion Features for Zero-Shot Text-Driven Motion Transfer (Nov., 2023)
-
Cut-and-Paste: Subject-Driven Video Editing with Attention Control (Nov., 2023)
- 有点Anydoor的意思~
-
LatentWarp: Consistent Diffusion Latents for Zero-Shot Video-to-Video Translation (Nov., 2023)
-
Fuse Your Latents: Video Editing with Multi-source Latent Diffusion Models (Oct., 2023)
-
DynVideo-E: Harnessing Dynamic NeRF for Large-Scale Motion- and View-Change Human-Centric Video Editing (Oct., 2023)
-
Ground-A-Video: Zero-shot Grounded Video Editing using Text-to-image Diffusion Models (Oct., 2023)
-
CCEdit: Creative and Controllable Video Editing via Diffusion Models (Sep., 2023)
-
MagicProp: Diffusion-based Video Editing via Motion-aware Appearance Propagation (Sep., 2023)
-
MagicEdit: High-Fidelity and Temporally Coherent Video Editing (Aug., 2023)
- 芭比娃娃的效果,可能有点意思。
-
StableVideo: Text-driven Consistency-aware Diffusion Video Editing (ICCV 2023)
- 更高级的style transfer
-
CoDeF: Content Deformation Fields for Temporally Consistent Video Processing (Aug., 2023)
- 开始部分解决了“生成一致性问题”,阿里的作品。
- FastBlend,是Ali的另一篇,但不是蚂蚁的。
-
TokenFlow: Consistent Diffusion Features for Consistent Video Editing (Jul., 2023)
- 目标风格化后,有点意思。
-
INVE: Interactive Neural Video Editing (Jul., 2023)
- Pika 视频编辑的出处。比较tricky,目标被“剪切”,像是generate的。类似 实时精确分割再粘贴。
-
VidEdit: Zero-Shot and Spatially Aware Text-Driven Video Editing (Jun., 2023)
- 分割目标的style generation效果不错。例如可改为客户的产品。
-
Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation (SIGGRAPH Asia 2023)
-
ControlVideo: Adding Conditional Control for One Shot Text-to-Video Editing (May, 2023)
-
Make-A-Protagonist: Generic Video Editing with An Ensemble of Experts (May, 2023)
-
Soundini: Sound-Guided Diffusion for Natural Video Editing (Apr., 2023)
-
Zero-Shot Video Editing Using Off-the-Shelf Image Diffusion Models (Mar., 2023)
-
Edit-A-Video: Single Video Editing with Object-Aware Consistency (Mar., 2023)
-
FateZero: Fusing Attentions for Zero-shot Text-based Video Editing (Mar., 2023)
- 想法很好,效果一般。
-
Pix2video: Video Editing Using Image Diffusion (Mar., 2023)
- 效果不好,但提到的2022年的 Text2Live 反而好一些,方案思路也有创意。
-
Video-P2P: Video Editing with Cross-attention Control (Mar., 2023)
- 看上去不错,具备编辑。
-
Dreamix: Video Diffusion Models Are General Video Editors (Feb., 2023)
- 用其模糊后作为基底,再生成与prompt相近的 video。
-
Shape-Aware Text-Driven Layered Video Editing (Jan., 2023)
- 整体风格转换。
-
Speech Driven Video Editing via an Audio-Conditioned Diffusion Model (Jan., 2023)
- 说话头。
-
- 给人物戴上眼镜等,是否可以添加一些火焰?
- 给人物戴上眼镜等,是否可以添加一些火焰?























Conditional Video Generation
-
- Pose Guided Video Generation
- Depth Guided Video Generation
- Multi-modal Video Generation
- Uni Audio-Video Generation
Video Editing
Future Work

 浙公网安备 33010602011771号
浙公网安备 33010602011771号