
[AWS] Mount EFS on your own custom docker image by Sagemaker API
Ref: boto3 sagemaker api - https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker.html
Input 的种类要多一些?Output 却只有 S3。Input提供了写权限了吗?
create_training_job(**kwargs)
Starts a model training job. After training completes, SageMaker saves the resulting model artifacts to an Amazon S3 location that you specify.
If you choose to host your model using SageMaker hosting services, you can use the resulting model artifacts as part of the model. You can also use the artifacts in a machine learning service other than SageMaker, provided that you know how to use them for inference.
In the request body, you provide the following:
AlgorithmSpecification - Identifies the training algorithm to use.
HyperParameters - Specify these algorithm-specific parameters to enable the estimation of model parameters during training. Hyperparameters can be tuned to optimize this learning process. For a list of hyperparameters for each training algorithm provided by SageMaker, see Algorithms .
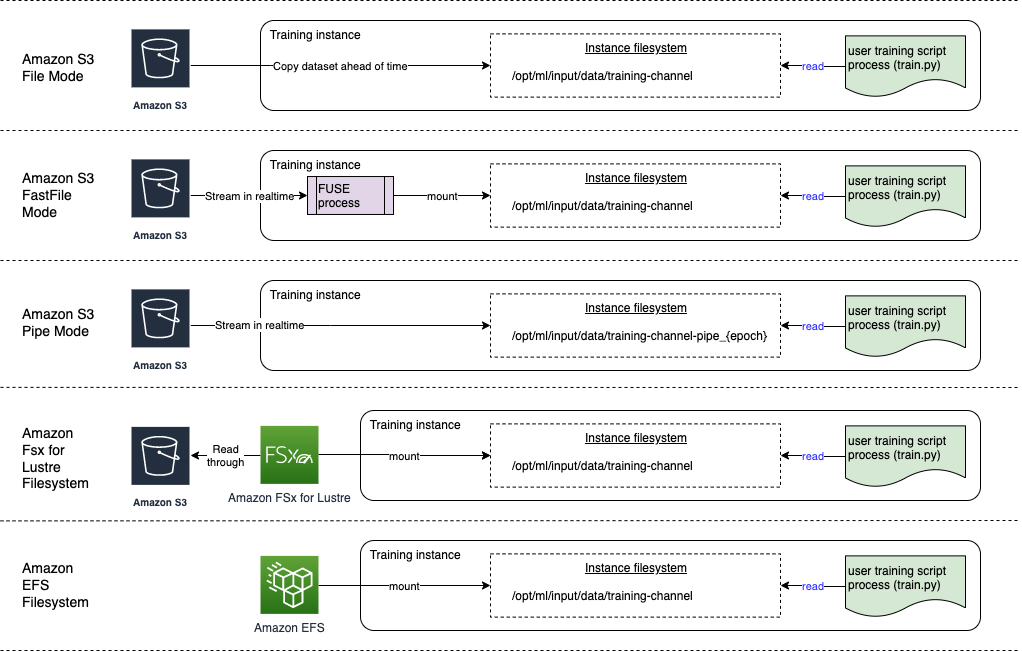
InputDataConfig - Describes the training dataset and the Amazon S3, EFS, or FSx location where it is stored.
OutputDataConfig - Identifies the Amazon S3 bucket where you want SageMaker to save the results of model training.
ResourceConfig - Identifies the resources, ML compute instances, and ML storage volumes to deploy for model training. In distributed training, you specify more than one instance.
EnableManagedSpotTraining - Optimize the cost of training machine learning models by up to 80% by using Amazon EC2 Spot instances. For more information, see Managed Spot Training .
RoleArn - The Amazon Resource Name (ARN) that SageMaker assumes to perform tasks on your behalf during model training. You must grant this role the necessary permissions so that SageMaker can successfully complete model training.
StoppingCondition - To help cap training costs, use MaxRuntimeInSeconds to set a time limit for training. Use MaxWaitTimeInSeconds to specify how long a managed spot training job has to complete.
Environment - The environment variables to set in the Docker container.
RetryStrategy - The number of times to retry the job when the job fails due to an InternalServerError .
InputDataConfig=[
{
'ChannelName': 'string',
'DataSource': {
'S3DataSource': {
'S3DataType': 'ManifestFile'|'S3Prefix'|'AugmentedManifestFile',
'S3Uri': 'string',
'S3DataDistributionType': 'FullyReplicated'|'ShardedByS3Key',
'AttributeNames': [
'string',
]
},
'FileSystemDataSource': {
'FileSystemId': 'string',
'FileSystemAccessMode': 'rw'|'ro',
'FileSystemType': 'EFS'|'FSxLustre',
'DirectoryPath': 'string'
}
},
'ContentType': 'string',
'CompressionType': 'None'|'Gzip',
'RecordWrapperType': 'None'|'RecordIO',
'InputMode': 'Pipe'|'File'|'FastFile',
'ShuffleConfig': {
'Seed': 123
}
},
],
Ref: Speed up training on Amazon SageMaker using Amazon FSx for Lustre and Amazon EFS file systems
Choose the best data source for your Amazon SageMaker training job
Your training job must connect to a VPC (see VPCConfig settings) to access Amazon EFS.
Ref: Using file systems in Amazon EFS
When you first create your file system, there is only one root directory at /. By default, only the root user (UID 0) has read-write-execute permissions.
专门设置EFS
Ref: https://sagemaker.readthedocs.io/en/stable/api/utility/inputs.html
这里讲解了细节,在超参数中,也有类似配置。
classsagemaker.inputs.FileSystemInput(file_system_id, file_system_type, directory_path, file_system_access_mode='ro', content_type=None) Bases: object Amazon SageMaker channel configurations for file system data sources. config A Sagemaker File System DataSource. Type dict[str, dict] Create a new file system input used by an SageMaker training job. Parameters file_system_id (str) – An Amazon file system ID starting with ‘fs-‘. file_system_type (str) – The type of file system used for the input. Valid values: ‘EFS’, ‘FSxLustre’. directory_path (str) – Absolute or normalized path to the root directory (mount point) in the file system. Reference: https://docs.aws.amazon.com/efs/latest/ug/mounting-fs.html and https://docs.aws.amazon.com/fsx/latest/LustreGuide/mount-fs-auto-mount-onreboot.html file_system_access_mode (str) – Permissions for read and write. Valid values: ‘ro’ or ‘rw’. Defaults to ‘ro’. The input configs for DatasetDefinition. DatasetDefinition supports the data sources like S3 which can be queried via Athena and Redshift. A mechanism has to be created for customers to generate datasets from Athena/Redshift queries and to retrieve the data, using Processing jobs so as to make it available for other downstream processes.
Ref: https://docs.aws.amazon.com/sagemaker/latest/dg/your-algorithms-training-algo-running-container.html
Training Data
The TrainingInputMode parameter in the AlgorithmSpecification of the CreateTrainingJob request specifies how the training dataset is made available. The following input modes are available:
-
-
Filemode-
TrainingInputModeparameter written toinputdataconfig.json: "File" -
Data channel directory in the Docker container:
/opt/ml/input/data/channel_name -
Supported data sources: Amazon Simple Storage Service (Amazon S3), Amazon Elastic File System (Amazon EFS), and Amazon FSx for Lustre
A directory is created for each channel. For example, if you have three channels named
training,validation, andtesting, SageMaker makes three directories in the Docker container:-
/opt/ml/input/data/training -
/opt/ml/input/data/validation -
/opt/ml/input/data/testing
-
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号