[action] A Comprehensive Study of Deep Video Action Recognition
论文赏析
A Comprehensive Study of Deep Video Action Recognition [Submitted on 11 Dec 2020]
读后感
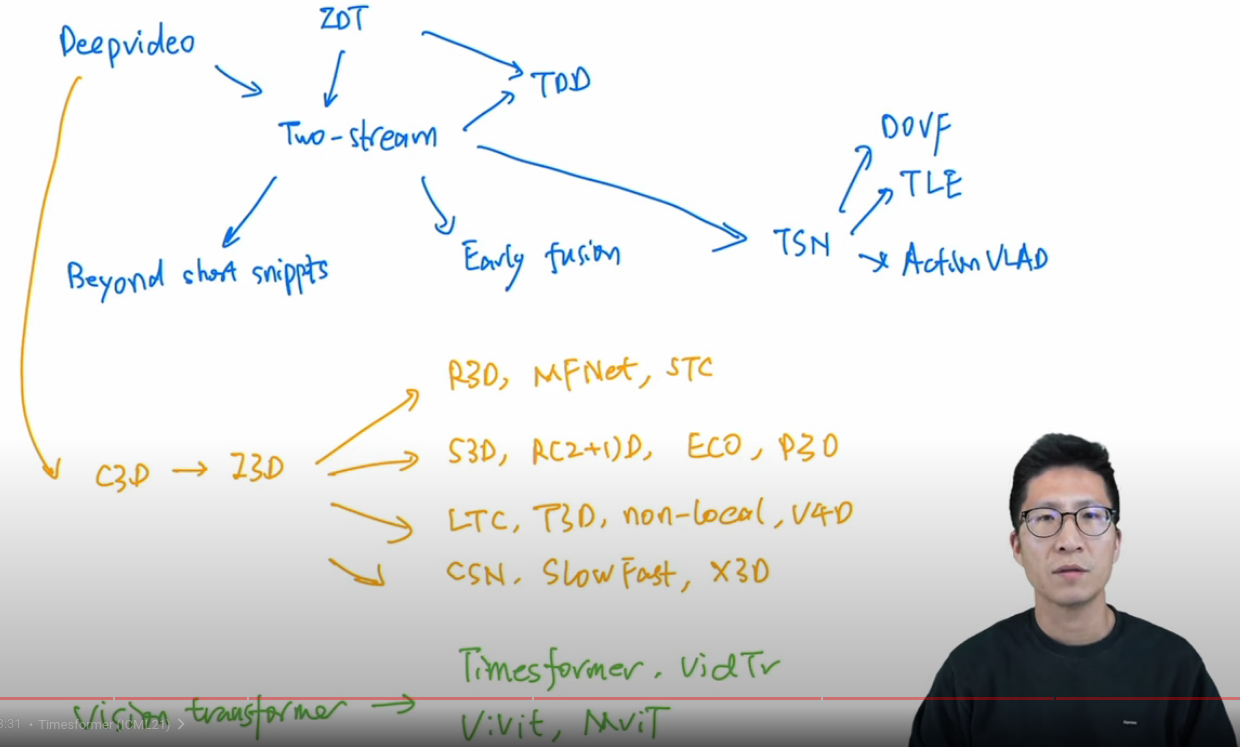
- Hand-crafted --> CNN
- Two-stream
- 3D CNN
- Video transformer
3D CNN
Ref: 基于opencv,使用python提取视频帧以及提取TVL1光流,计算代价较大。
-
3D卷积
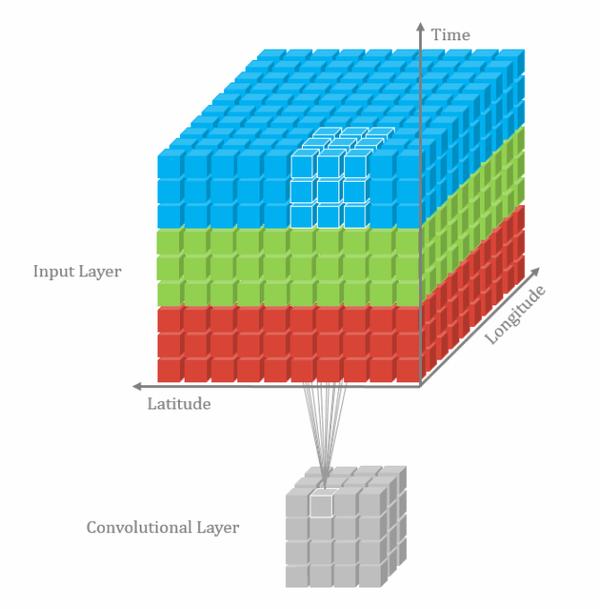
C3D提倡了特征提取这样的概念。
-
I3D
I3D 论文精读【论文精读】,一己之力,双流到3D网络,刷爆了原来的数据集。
-
Non-local Neural Networks
时序建模
自注意力 --> vision transformer
自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。
Origin from Non-local means.
不用光流,也可以达到不错的效果。
-
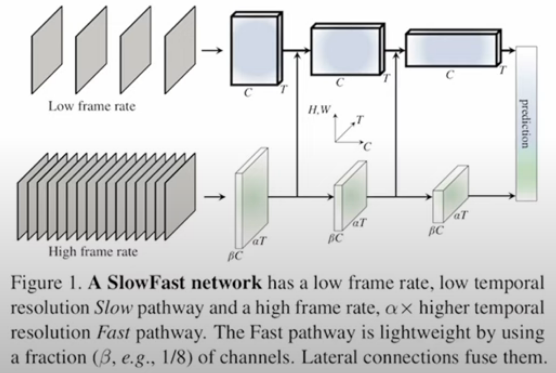
Slow-fast
模拟人眼两类细胞原理。
总览总结
其他资源
作者单位:亚马逊( @李沐等人)
论文:https://arxiv.org/abs/2012.06567
模型库介绍链接:https://cv.gluon.ai/model_zoo/action_recognition.html
Slowfast Model
Ref: 【唐宇迪】一行代码调用预训练模型!行为识别模型Slowfast算法通俗解读 人工智能入门教程
获取动作?获取环境?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号