[action] Action Recognition by Skeleton
Ref: OpenMMTalk #1| Skeleton based action recognition _PoseC3D
Ref: 行为识别(action recognition)目前的难点在哪?
行为识别综述
Ref: https://zhuanlan.zhihu.com/p/88945361
-
2. 行为识别方法
2.1 时空关键点(space-time interest points)
2.2 密集轨迹(dense-trajectories)
2.3 表观和光流并举(two-stream)
2.4 3D卷积网络(C3D)
2.5 LSTM
2.6 图卷积网络(GCN)
-
多模态

-
Why Skeleton?

-
足够秦轻量?
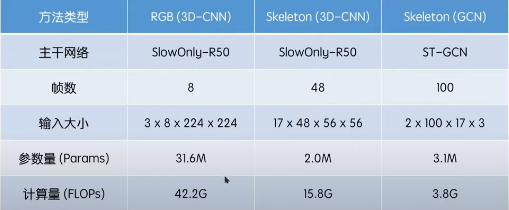
PySlowFast进展
Ref: https://github.com/facebookresearch/SlowFast
The goal of PySlowFast is to provide a high-performance, light-weight pytorch codebase provides state-of-the-art video backbones for video understanding research on different tasks (classification, detection, and etc). It is designed in order to support rapid implementation and evaluation of novel video research ideas. PySlowFast includes implementations of the following backbone network architectures:
- SlowFast
- Slow
- C2D
- I3D
- Non-local Network
- X3D
- MViTv1 and MViTv2
- Rev-ViT and Rev-MViT
Open-mmlab的进展

人体模型识别:https://github.com/open-mmlab/mmhuman3d/blob/main/README_CN.md


Ref: https://github.com/open-mmlab/mmpose
如何编辑 Skeleton


动作识别:https://github.com/open-mmlab/mmaction2/blob/master/README_zh-CN.md
Supported Methods.
| Action Recognition | ||||
| C3D (CVPR'2014) | TSN (ECCV'2016) | I3D (CVPR'2017) | I3D Non-Local (CVPR'2018) | R(2+1)D (CVPR'2018) |
| TRN (ECCV'2018) | TSM (ICCV'2019) | TSM Non-Local (ICCV'2019) | SlowOnly (ICCV'2019) | SlowFast (ICCV'2019) |
| CSN (ICCV'2019) | TIN (AAAI'2020) | TPN (CVPR'2020) | X3D (CVPR'2020) | OmniSource (ECCV'2020) |
| MultiModality: Audio (ArXiv'2020) | TANet (ArXiv'2020) | TimeSformer (ICML'2021) | ||
| Action Localization | ||||
| SSN (ICCV'2017) | BSN (ECCV'2018) | BMN (ICCV'2019) | ||
| Spatio-Temporal Action Detection | ||||
| ACRN (ECCV'2018) | SlowOnly+Fast R-CNN (ICCV'2019) | SlowFast+Fast R-CNN (ICCV'2019) | LFB (CVPR'2019) | |
| Skeleton-based Action Recognition | ||||
| ST-GCN (AAAI'2018) | 2s-AGCN (CVPR'2019) | PoseC3D (ArXiv'2021) | ||
Results and models are available in the README.md of each method's config directory. A summary can be found on the model zoo page.
基于骨架原理(GCN系列)
Ref: 行为识别综述
2.5 基于骨架原理
本方法是由港中文-商汤科技联合实验室所提出的一种时空图卷积网络(ST-GCN)
ST-GCN这篇论文算是GCN在骨骼行为识别里面的开山之作了,虽然他只是2018年发表的。这篇论文还给了很详细的代码,2019年发表在CVPR上的AS-GCN和2s-AGCN都是在该代码的基础上改进的。
基于RGB,则巨大的计算成本:对于101类别的2D网络参数为5M,而对于相同的3D网络需要33M。在UCF101 上训练3D ConNet需要3到4天,在Sports-1M上训练大约需要两个月,这使得广泛的框架搜索变得困难,并且容易发生过拟合。
kinetics-skeleton格式
Ref: https://jsonformatter.curiousconcept.com/#
Ref: https://drive.google.com/drive/folders/1SPQ6FmFsjGg3f59uCWfdUWI-5HJM_YhZ
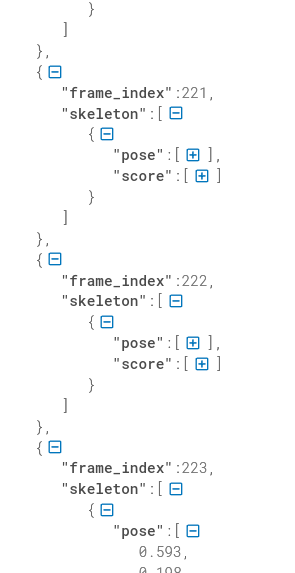
Ref: st-gcn训练自建行为识别数据集
之后还要再转换一次格式:
stgcn训练代码中自带了数据转换代码tools/kinetics_gendata.py,使用该脚本将kinetics-skleton数据集转换为训练使用的npy与pkl文件。
Ref: ST-GCN : A Machine Learning Model for Detecting Human Actions from Skeletons
(Spatial-Temporal Graph Convolutional Networks)
60 labeled actions.
Training on your own dataset
The kinetics_train folder contains json data containing the pose keypoints. If you want to train on your own data set, create a file equivalent to this json file according to the following format.
{“data”: [{“frame_index”: 1, “skeleton”: [{“pose”: [0.518, 0.139, 0.442, 0.272, 0.399, 0.288, 0.315, 0.400, 0.350, 0.549, 0.487, 0.264, 0.507, 0.356, 0.548, 0.408, 0.413, 0.584, 0.401, 0.785, 0.383, 0.943, 0.497, 0.582, 0.485, 0.750, 0.479, 0.908, 0.514, 0.119, 0.000, 0.000, 0.483, 0.128, 0.000, 0.000], “score”: [0.305, 0.645, 0.647, 0.865, 0.841, 0.505, 0.361, 0.726, 0.487, 0.708, 0.546, 0.575, 0.695, 0.713, 0.343, 0.000, 0.395, 0.000]}]}, {“frame_index”: 2, “skeleton”: [{“pose”: [0.516, 0.155, 0.438, 0.272, 0.395, 0.288, 0.315, 0.405, 0.352, 0.552, 0.483, 0.261, 0.505, 0.351, 0.548, 0.416, 0.413, 0.590, 0.401, 0.791, 0.383, 0.946, 0.499, 0.587, 0.487, 0.750, 0.481, 0.910, 0.516, 0.136, 0.000, 0.000, 0.495, 0.141, 0.000, 0.000], “score”: [0.249, 0.678, 0.624, 0.838, 0.858, 0.506, 0.293, 0.706, 0.471, 0.728, 0.567, 0.566, 0.665, 0.719, 0.367, 0.000, 0.593, 0.000]}]}, …, “label”: “jumping into pool”, “label_index”: 172}
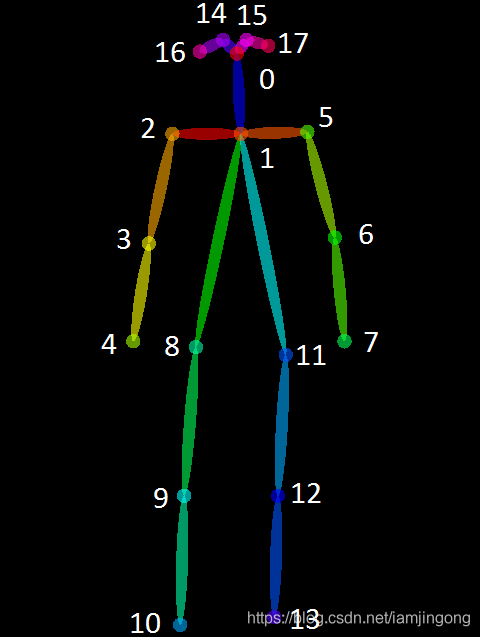
The pose of the skeleton contains 18 keypoints in xyxy order. score contains the confidence values. skeleton is an array to handle the case where the video contains several people. frame_index should start from 1. Note that data must be less than 300 frames.
The label information can be found in kinetics_train_label.json, in the format described below. The key is the file name from where it will read the pose information as described above. label_index starts from 0.
How to consider the “background”?
Cannot!
考虑下多模态融合?
裁剪 Subject-centered cropping
减少噪音。
可视化

合成数据
ElderSim:用于老年人护理应用中人类行为识别的合成数据生成平台
arXiv - CS - Artificial Intelligence Pub Date : 2020-10-28 , DOI: arxiv-2010.14742
Hochul Hwang, Cheongjae Jang, Geonwoo Park, Junghyun Cho, Ig-Jae Kim
Ref: Synthetic Humans for Action Recognition from Unseen Viewpoints
实现方法是什么?
Todo List.
骨架与rgb融合
VPN: Learning Video-Pose Embedding for Activities of Daily Living (ECCV 2020)
Contintue ...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号