[action] PoseConv3D
Ref: [action] Action Recognition by Skeleton
- 深兰科技|一文了解基于ST-GCN的人体动作识别与生成【过去】
- PoseC3D: 基于人体姿态的动作识别新范式【现在】
- [CVPR22 Oral] PoseConv3D: Processing Skeleton Data with 3D-CNN【现在】
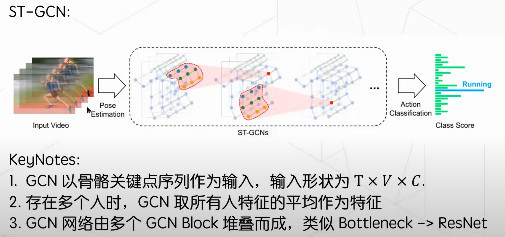
ST-GCN是香港中文大学提出一种时空图卷积网络,可以用它进行人类行为识别。这种算法基于人类关节位置的时间序列表示而对动态骨骼建模,并将图卷积扩展为时空图卷积网络而捕捉这种时空的变化关系。
不同于传统的基于人体 3 维骨架的 GCN 方法,PoseC3D 仅使用 2 维人体骨架热图堆叠作为输入,就能达到更好的识别效果。
大部分骨骼动作识别的工作采用 GCN 来提取骨骼的特征。尽管被广泛使用,但 GCN 方法依然在鲁棒性、兼容性和可扩展性上存在一定缺陷。
Let's: https://youtu.be/IWKY5PyF0LU?t=955
Heatmap Volumn
多个人,输入?如何处理?
17个关节,32 frames。

W的热图,其中K是关节数,H和W是帧的高度和宽度
- 基于提取好的 2D 姿态,我们需要堆叠 T 张形状为 K×H×W 的二维关键点热图以生成形状为 K×T×H×W 的 3D 热图堆叠作为输入。
- 我们根据视频中人的位置,寻找一个最紧的框以包含所有帧中的所有人。
- 我们基于骨骼模态和骨骼 + RGB 模态,分别设计了两种 3D-CNN: Pose-SlowOnly 与 RGBPose-SlowFast。
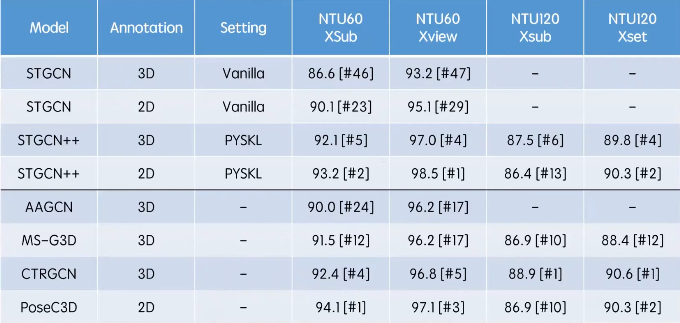
- Pose-SlowOnly 仅以骨骼模态作为输入,下表中 Pose Pathway 展示了它具体的结构。在实验中,Pose-SlowOnly 在多个数据集上的精度超越了当前基于 GCN 的 SOTA。由于使用了 3D-CNN 作为模型架构,Pose-SlowOnly 可与其他模态在前期就能进行特征的融合。
- RGBPose-SlowFast,它包含两个分支,分别处理 RGB 和骨骼两个模态。RGB 分支具有低帧率以及更大的网络宽度,骨骼分支具有高帧率和更小的网络宽度。两分支间存在双向连接,以促进模态间的特征融合。我们将两分支的预测结果融合,作为最终的预测。在训练时,我们用两个单独的损失函数分别训练两个分支,以避免过拟合。

动作识别:https://github.com/open-mmlab/mmaction2/blob/master/README_zh-CN.md
Supported Methods.
| Action Recognition | ||||
| C3D (CVPR'2014) | TSN (ECCV'2016) | I3D (CVPR'2017) | I3D Non-Local (CVPR'2018) | R(2+1)D (CVPR'2018) |
| TRN (ECCV'2018) | TSM (ICCV'2019) | TSM Non-Local (ICCV'2019) | SlowOnly (ICCV'2019) | SlowFast (ICCV'2019) |
| CSN (ICCV'2019) | TIN (AAAI'2020) | TPN (CVPR'2020) | X3D (CVPR'2020) | OmniSource (ECCV'2020) |
| MultiModality: Audio (ArXiv'2020) | TANet (ArXiv'2020) | TimeSformer (ICML'2021) | ||
| Action Localization | ||||
| SSN (ICCV'2017) | BSN (ECCV'2018) | BMN (ICCV'2019) | ||
| Spatio-Temporal Action Detection | ||||
| ACRN (ECCV'2018) | SlowOnly+Fast R-CNN (ICCV'2019) | SlowFast+Fast R-CNN (ICCV'2019) | LFB (CVPR'2019) | |
| Skeleton-based Action Recognition | ||||
| ST-GCN (AAAI'2018) | 2s-AGCN (CVPR'2019) | PoseC3D (ArXiv'2021) | ||
Results and models are available in the README.md of each method's config directory. A summary can be found on the model zoo page.
Where is RGBPose-Conv3D?
Regarding the implementation of poseC3D considering both RGB and pose input #1221
Jeba-create opened this issue on 12 Oct 2021 · 15 comments
Hi, Jeba-create, if you want to implement the RGBPoseSlowFast in the PoseC3D paper on ur own: - You need to create a new dataset, which provides samples consist of RGB videos and 2D skeletons (For example, video file path and skeleton in a single dictionary). (register it in DATASETS) - You need to create components in the data pipeline to process such samples. (register it in PIPELINES) - You need to create a two-stream backbone, which takes both RGB frames and heatmap volumes (maybe in a tuple) as input. (register it in BACKBONES) Implementing RGBPoseSlowFast requires some effort, if you just need RGB+Pose-based predictions, you can fuse predictions of two individual streams directly.
Hi, the rest part of the PoseC3D project (RGBPose-SlowFast & PoseC3D + Kinetics) will be released after the paper gets published.
Ref: https://github.com/kennymckormick/pyskl【dev版本】
Revisiting Skeleton-based Action Recognition
等待。。。
Continue ...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号