[CV] Training Data Collections Of Kaggle
收集一些有意思的比赛项目,评估当前选手们的大致水准。
检测
布匹缺陷检测
https://tianchi.aliyun.com/competition/entrance/531864/information
CVPR 2021 AliProducts Challenge: Large-scale Product Recognition
https://tianchi.aliyun.com/competition/entrance/531884/rankingList
淘宝直播商品识别大赛
https://tianchi.aliyun.com/competition/entrance/231772/forum
Underwater
2020年全国水下机器人(湛江)大赛——水下光学图像目标检测 Rank3 方案分享
-
16th Simple Solution - Only Yolov5
Posted in tensorflow-great-barrier-reef
Congratulate for taking the 16th and thanks for sharing your solution. I wonder why you trained the yolov5s with large sizes when the yolov5m trained with smaller one.
Great to know about ensemble with multi-scale images. Thanks and congrats on silver medal!
-
10th place solution — 2xYOLOv5 + tracking
Our solution is an ensemble of two differently trained yolov5 models + tracking.
What did’t work:
-
- Manual reannotations of data - some COTS were not labeled because they appeared in frames later than updated annotation. (my assumption). Adding these COTS slightly improved CV, but significantly worsened LB.
- TTA. Slightly impoved LB and CV, but takes much longer to run.
- Blend of different yolo architectures
- Blend one stage and two stage detectors. I spent the last week completely devoted to the models on mmdetection, hoping to improve the ensemble score. However, my cascade rcnn showed much worse results on both CV and LB.
homography + norfair match much better than just norfair.
-
5th place solution, poisson blending,detection and tracking
https://www.kaggle.com/c/tensorflow-great-barrier-reef/discussion/308007
The following ideas and methods helped me survive from this challenging competition.
1.Copy COTS box and paste into background image, apply poisson blending.
2.Several detection models training and inference with different image sizes.
3.Appending boxes to detection results by finding homography matrix.
4.Trust Local CV.

-
3rd place solution - Team Hydrogen
Our solution is a blend of five different object detection model types with tracking.
Our final solution is a blend of five different model types. All our models are trained on a resolution of 1152x2048 and only using images with boxes. For augmentations we employ a mix of random flips, scale, shift, rotate, brightness, contrats, cutout, cutmix.
Blending & Tracking
For blending, we employ average WBF blending which is particularly useful here as it automatically incorporates a voting mechanism of boxes to downweight boxes that are not present in all models.
加权框融合 WBF(Weighted Boxes Fusion: combining boxes for object detection models)
-
2nd Solution - YOLOv5
公开了代码:https://github.com/louis-she/reef-solution
In the early of this competition, we saw that there is a very solid way to split the dataset called "subsequence". After some submissions, the LB is not stable enough, so in the end we use video_id 3 fold split, because in that time, we guess that the LB and private maybe totally different video sequences, besides, score of the CV is now almost positive correlation with the LB.
做了至少十次实验,然后ensembly。
-
Trust CV -- 1st Place Solution
Thanks to the organizers and congrats to all the winners and my wonderful teammates @nvnnghia and @steamedsheep
This is really very unexpected for us. Because we don't have any NEW THING, we just keep optimizing cross validation F2 of our pipeline locally from the beginning till the end.
Summary
We designed a 2-stage pipeline. object detection -> classification re-score. Then a post-processing method follows.
Validation strategy: 3-fold cross validation split by video_id.
Object detection
-
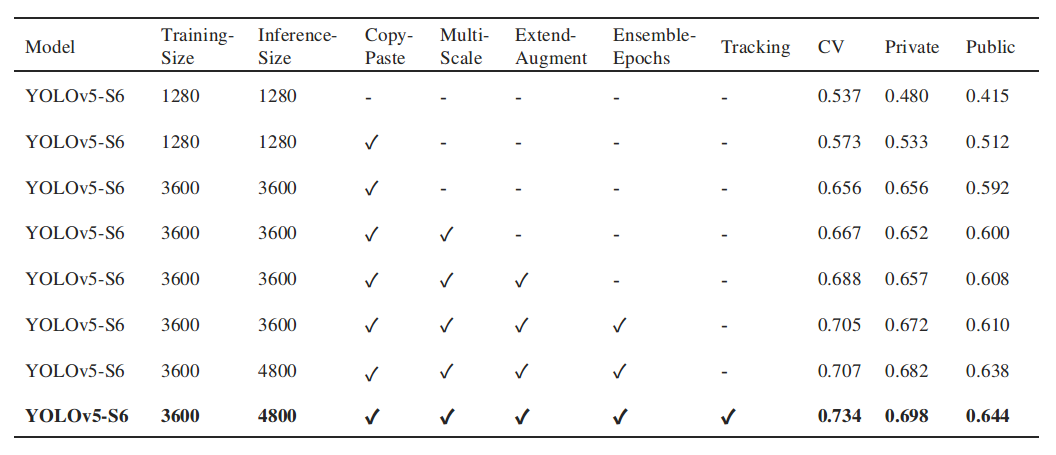
- 6 yolov5 models, 3 trained on 3648 images and 3 trained on 1536 image patches (described below)
- image patches: we cut original image (1280x720) into many patches (512x320), removed boxes near boundary, then only train yolov5 on those patches with cots.
- modified some yolo hyper-parameters based on default:
box=0.2,iou_t=0.3 - augmentations: based on yolov5 default augmentations, we added: rotation, mixup and albumentations.Transpose, then removed HSV.
- after the optimization was completed by cross validation, we trained the final models with all the data.
- all models are inferred using the same image size as trained.
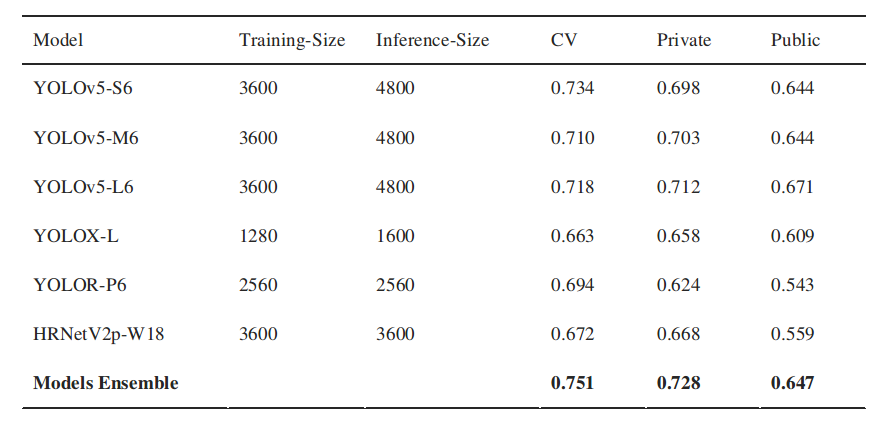
- ensemble these 6 yolov5 models gives us CV0.716, in addition the best one is CV0.676.
Classification re-score:
-
- crop out all predicted boxes (3-fold OOF) into squares with conf > 0.01. The side length of the square is
max(length, width)of the predicted boxes, then extended by 20%. - we calculate the iou as the maximum of the iou values of each predicted box and GT boxes of this image.
- classification target of each cropped box: iou>0.3, iou>0.4, iou>0.5, iou>0.6, iou>0.7, iou>0.8 and iou>0.9 Simply put, the iou is divided into 7 bins. e.g.:
[1,1,1,0,0,0,0]indicates the iou is between 0.5 and 0.6. - during inference we average 7 bin outputs as classification score.
- then we use BCELoss to train those cropped boxes by size 256x256 or 224x224.
- a very high dropout_rate or drop_path_rate can help a lot to improve the performance of the classification model. We use
dropout_rate=0.7anddrop_path_rate=0.5 - augmentations: hflip, vflip, transpose, 45° rotation and cutout.
The best classification model can boost out CV to 0.727 - after ensemble some classification models, our CV comes to 0.73+
- crop out all predicted boxes (3-fold OOF) into squares with conf > 0.01. The side length of the square is
Post-processing
Finally, we use a simple post-processing to further boost our CV to 0.74+.
For example, the model has predicted some boxes B at #N frame, select the boxes from B which has a high confidence, these boxes are marked as "attention area".
in the #N+1, #N+2, #N+3 frame, for the predicted boxes with conf > 0.01, if it has an IoU with the "attention area" larger than 0, boost the score of these boxes with score += confidence * IOU
We also tried the tracking method, which gives us a CV of +0.002. However, it introduces two additional hyperparameters. We therefore chose not to use it.
Little story
At the beginning of the competition, we used different F2 algorithms for each of the three members of our team, and later we found that for the same oof, we did not calculate the same score.
For example, nvnn shared an OOF file with F2=0.62, and sheep calculated F2=0.66, while I calculated F2=0.68.
We finally chose to use the F2 algorithm with the lowest score from nvnn to evaluate all our models.
https://www.kaggle.com/haqishen/f2-evaluation/script
Here's our final F2 algorithm, if you are interested you can use this algorithm to compare your CV with ours!
Acknowledge
As usual, I trained many models in this competition using Z by HP Z8G4 Workstation with dual A6000 GPU. The large memory of 48G for a single GPU allowed me to train large resolution images with ease. Thanks to Z by HP for sponsoring!
分类
Products-10K, Large-scale Product Recognition Challenge @ ICPR 2020
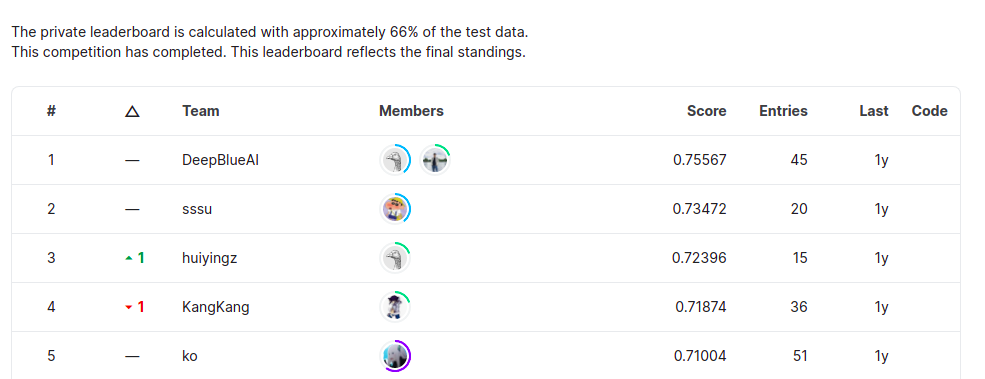
Leaderboard: https://www.kaggle.com/c/products-10k/discussion/188005
共有9690个类别。
- 第五名方案
NAS
神经网络结构搜索(Neural Architecture Search,NAS)是自动机器学习(Auto-ML)领域热点之一。
RegNet-y
- 第三名方案
https://blog.floydhub.com/ten-techniques-from-fast-ai/
https://www.fast.ai/
- 第二名方案
较充分地使用了各种预处理技巧,其实就是充分利用了imgaug这个库的内容,能达到类似效果。
https://imgaug.readthedocs.io/en/latest/source/overview_of_augmenters.html
In our solution, we first train four backbones in the original dataset, which are , ResNet101, ResNet200-vd, Res2Net200-vd, efficient - net-b5,efficient - net-b6,SENet154 and so on.
Some Settings are as follows:
Image size:
RandomResizedCrop images 512x512 for training.
enlarge the image size to 585x585 during test, the reason behind this is neural network tends to achieve good performance when the object scale is the same between training and testing. 224*224 for test
Augmentation:
RandomResizedCrop,RandomBrightnessContrast,HorizontalFlip,ColorJitter and so on.
Optimizer:
Adam
Loss function:
focal loss + crossentropyloss
Ensemble:
We can get multiple classification result for different models, so we need to merge the result to achieve the best performances.We merge the result of different models based on their performance on the test dataset, the better model has higher weight.we assign 5 weight to the top5 label and sum the classification result of different models to get the final prediction;then we use the classification model as the backbone to extract the features of the train and test dataset,we merge the result of top5 retrieval result with 5 weights for a single model;finally we merge the retrieval result of different models with different weight,achieving 0.70538/0.73472
- 第一名方案
Overview
Validation set : Random sample from the class with more than 20
Augmentation : left-right flip; Random Erase; ColorJitter; RandomCrop; Augmix
Pooling: GEM pooling
Classifier: Cosface, Arcface, CircleSoftmax
Loss : Focal loss and CrossEntropy Loss
Optimizer : Adam(3e-4, momentum=0.9, decay=1e-5)
Backbone: resnest101(bs=192) , resnest200(bs=128) , resnest269(bs=96)
Scale: 448, 512(best scale in our exps), 640
Hardware : 8x32G GPUs
Furthermore, we find that a bn layer applied between pooling and classifier layer is helpful for the task.
Ensemble:
We achieve 0.70918/0.73618 with single model which also the top1 rank in both pulic and private leadborad (resnest101+512+flip+erase+randomcrop+augmix+circlesoftmax+gem+focal)
For the last submission we ensemble 11 models with different augmentation or scale or backbone.
Unhelpful tricks (performance in single model):
Larger Backbone and larger Scale
EfficientNet
AutoAug
BNN-Style Mixup
If you have any questions, feel free to ask.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号