[LLM] Attention to Transformer
本篇来自如下。不同的人对transformer的讲解角度不同,多听听,在多角度认知的前提下,方能真正理解transformer。
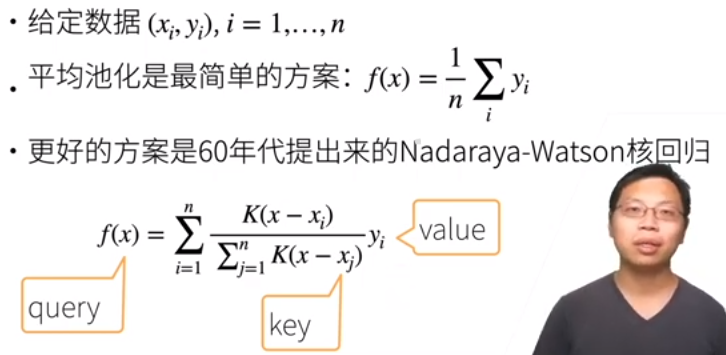
Nadaraya-Watson 核回归
非参化
不用学参数。
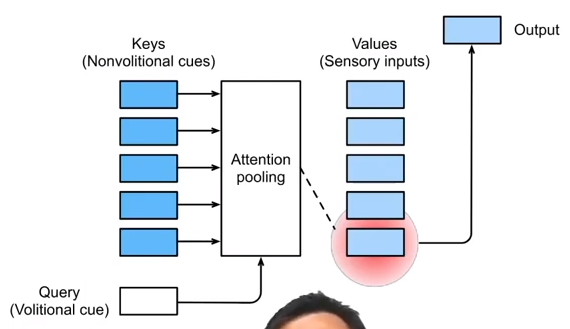
Nadaraya-Watson核回归的注意力汇聚:对训练数据的输出加权平均。
在 (10.2.6) 中, 可以理解为:x于xi越接近,那么 as a role of weight for yi,就应当越大。
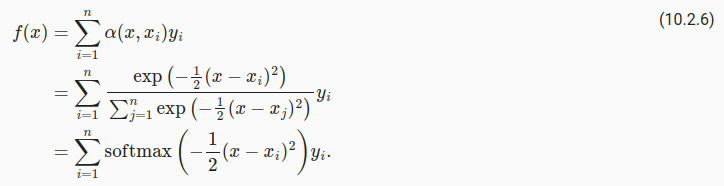
Output的计算步骤如下。
注意力分数:query与key的相似度;
注意力权重:对以上分数做softmax之后的结果。
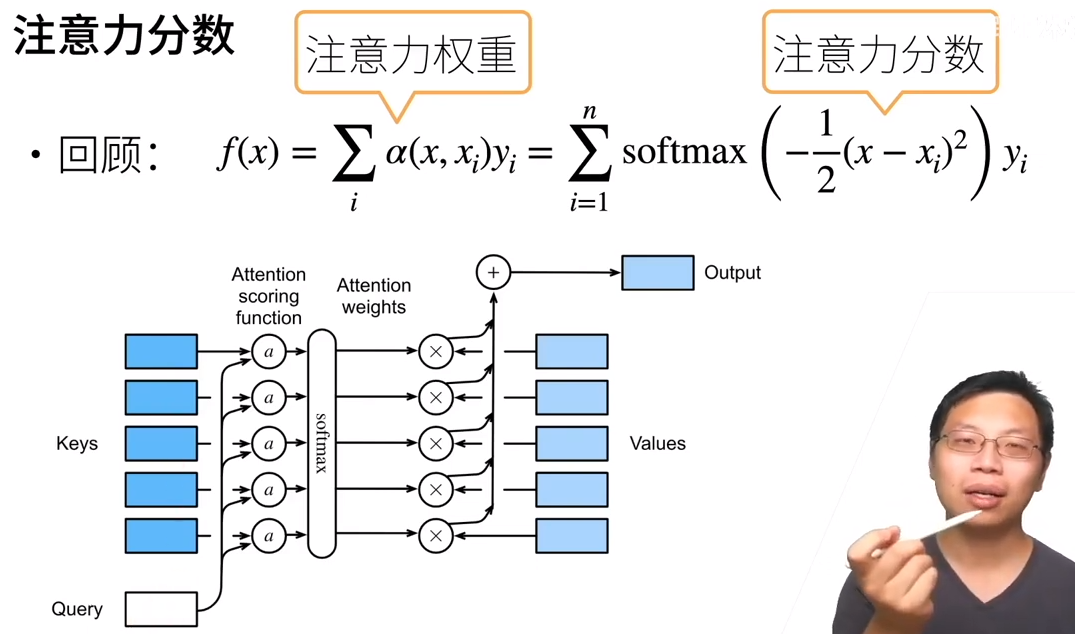
将变量拓展到高维向量,便得到了 注意力池化层。
参数化
参数化的注意力机制,例如增加一个 可学习的 w。在上图中,也就是“如何设计a函数(Attention scoring function)的问题”。

现在我们通过引入W来加 一个单隐藏层。

从机器翻译说起
Seq2Seq句子翻译
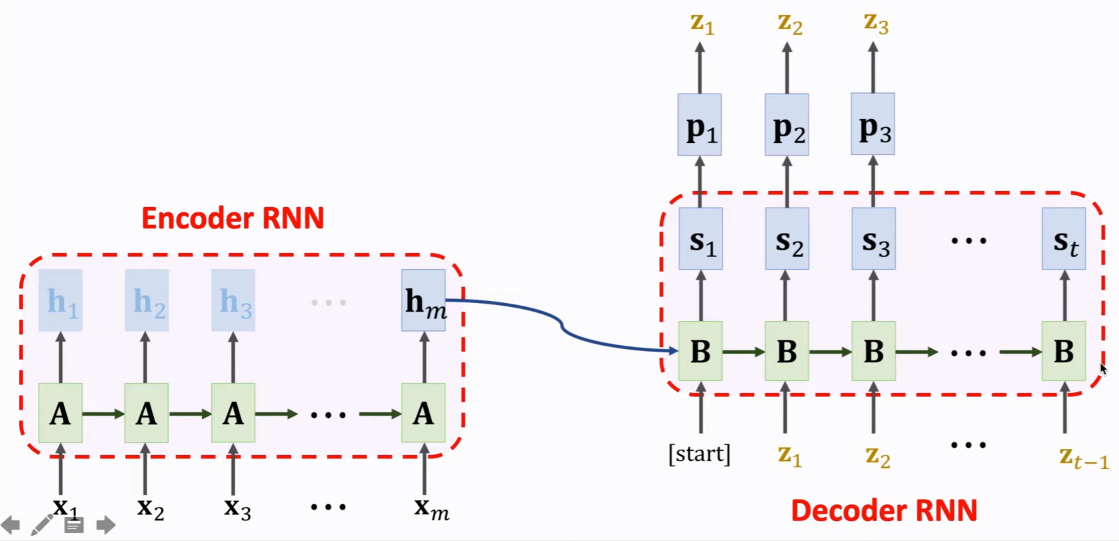
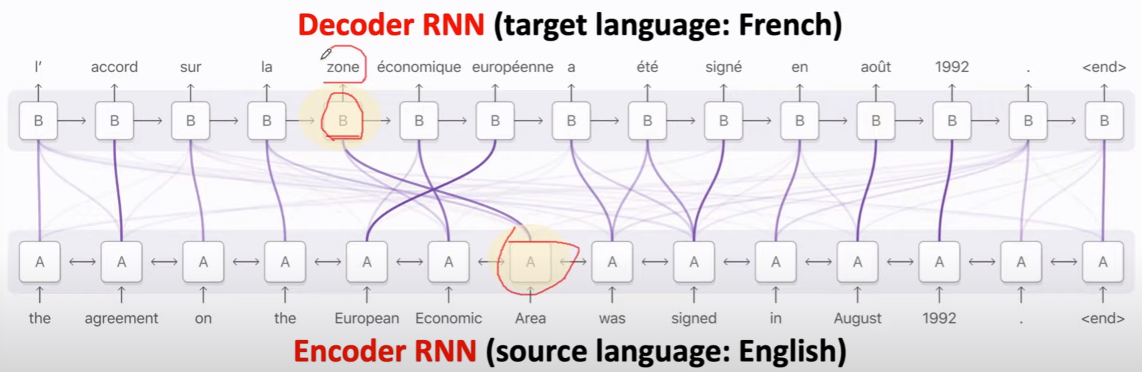
我们希望在左边的 encoder 中的“我”的权重或相关的隐变量等 能更多地贡献于右边 decoder 中的 “I”。
所以,
通过 “上一个词” as query 来推断下一个词。
左边,只有最后一个hm有价值,前面的则放弃。(但会导致遗忘问题)
右边,获得hm作为输入后,先得到 更新后的状态s1,得到概率p1,抽样得到z1。
注意力机制

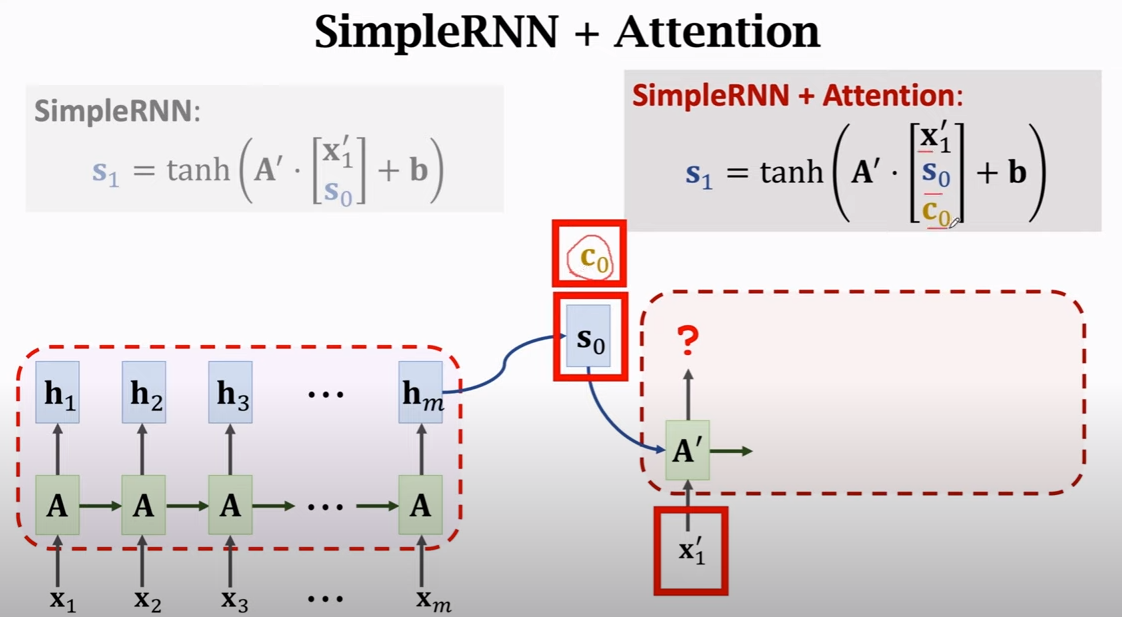
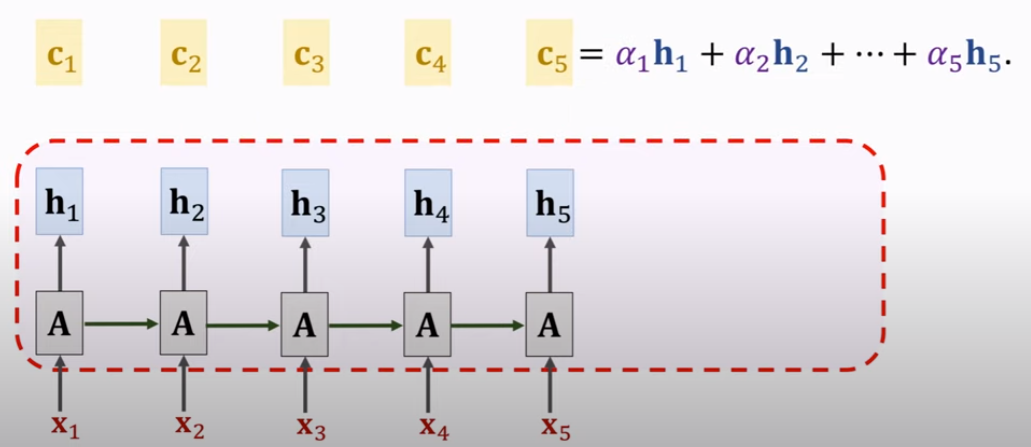
课间思考:c 有点类似 f(x),是个output。hi 则有点类比xi,能与s0做比较得到相似度;同时也是yi。

预测s1
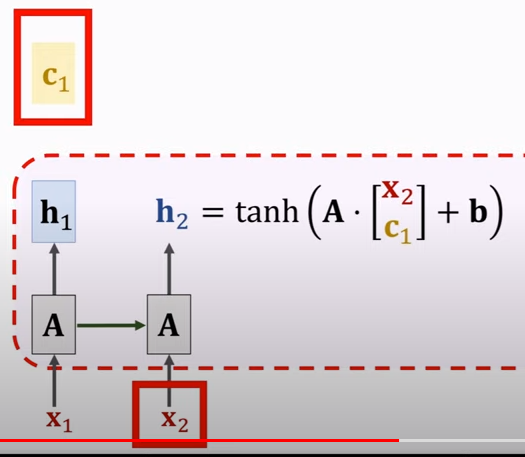
可见,有了c1后,也有了新的计算s1的方式。
下图中,之前没有c0,也就是s1不会有所有序列的信息,但引入c0后,新的 s1就会考虑序列所有项的信息!(注意理解)
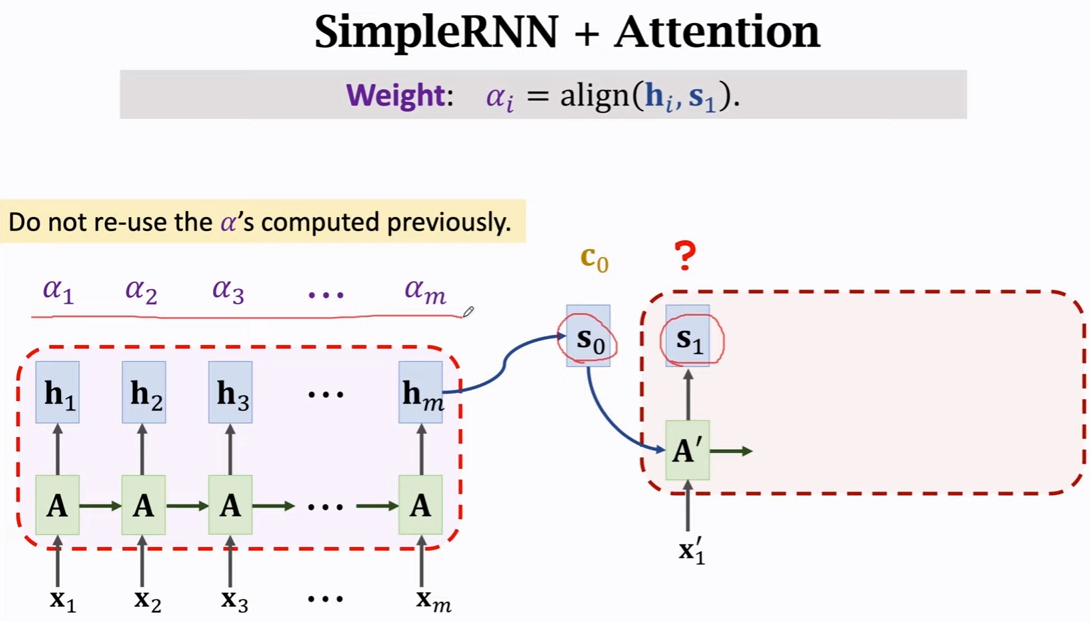
之后便是 “这一轮” 最后的c1的计算。在计算前先通过s1以及相关性计算得到 alpha。
[paper] Neural Machine Translation by Jointly Learning to Align and Translate, 2015
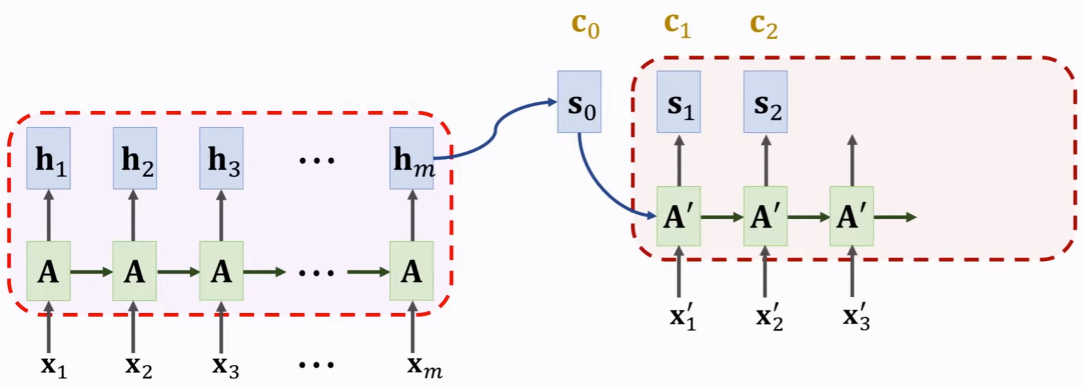
神奇的C0保留了encoder的全部状态,这是关键。
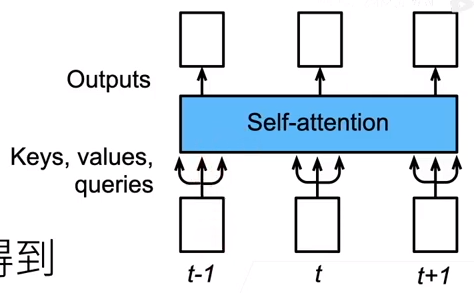
自注意力机制
计算alpha。如下的h2 会与自己也比较一次得到 alpha2。

c 作为 output的结算过程如下。
[paper] Long Short-Term Memory-Networks for Machine Reading, 2016
Self-Attention则利用了Attention机制,计算每个单词与其他所有单词之间的关联,
如下图,序列中包含了 key, value, and query。
位置编码
设计为了sin cos的形式,支持了位置信息。
变形金刚 - Transformer

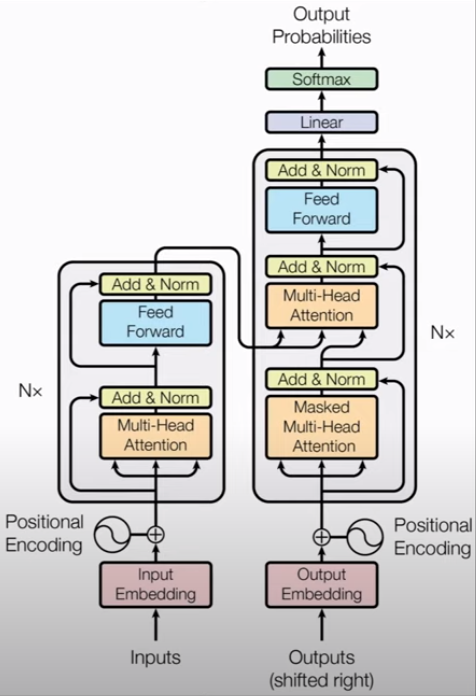
[1]
RNN 有个 h 作为 xi的角色。下图是直接由 x 导出了k and v。


[2]
q 与 k的 意义比较得到权重,如下。
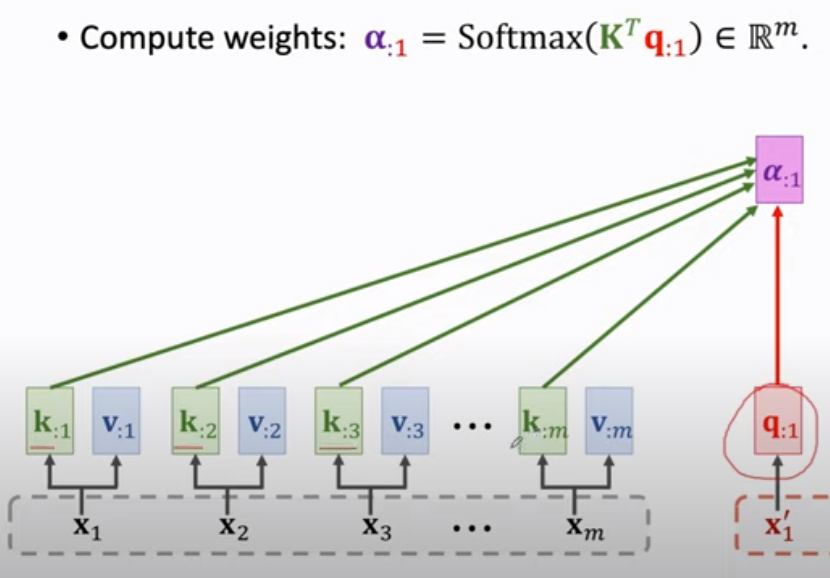
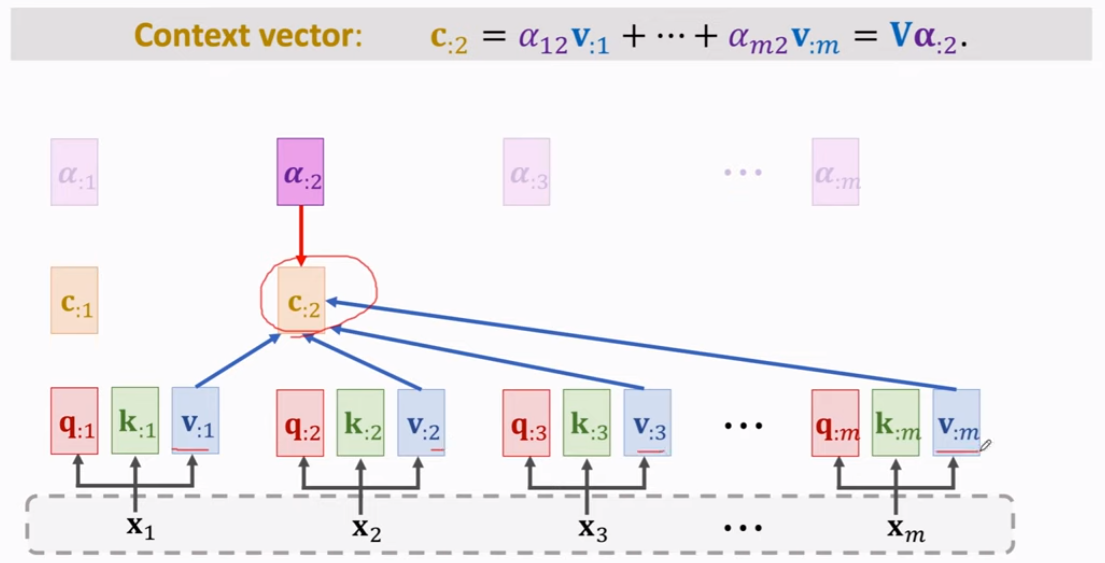
Output: c 通过 与v相乘 再加 得到。
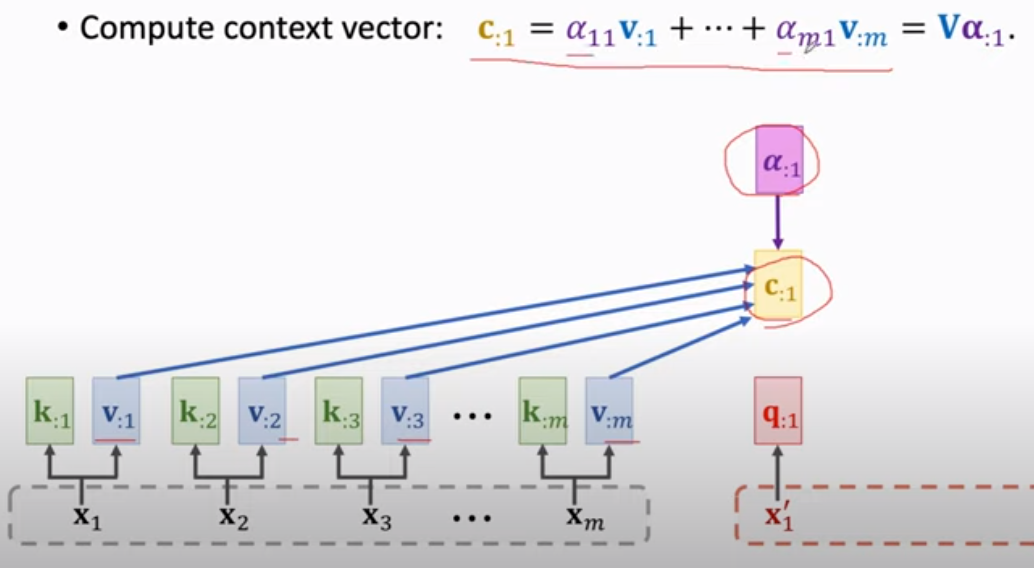
可见,此时已没有了RNN的痕迹!貌似需要加入 "位置编码"。
最终的 Output 是个 C = [c1, c2, ...] 如下图。也就是 “一层” attention layer的 output。
右边的c 得到一个抽样的x',类似RNN 一个一个字的翻译出来。

[3]
再聊聊 "自注意力机制"。
可见,因为没有 decoder,q也挤到了“左边”。当前的q要与所有的k计算得到 权重 alpha。
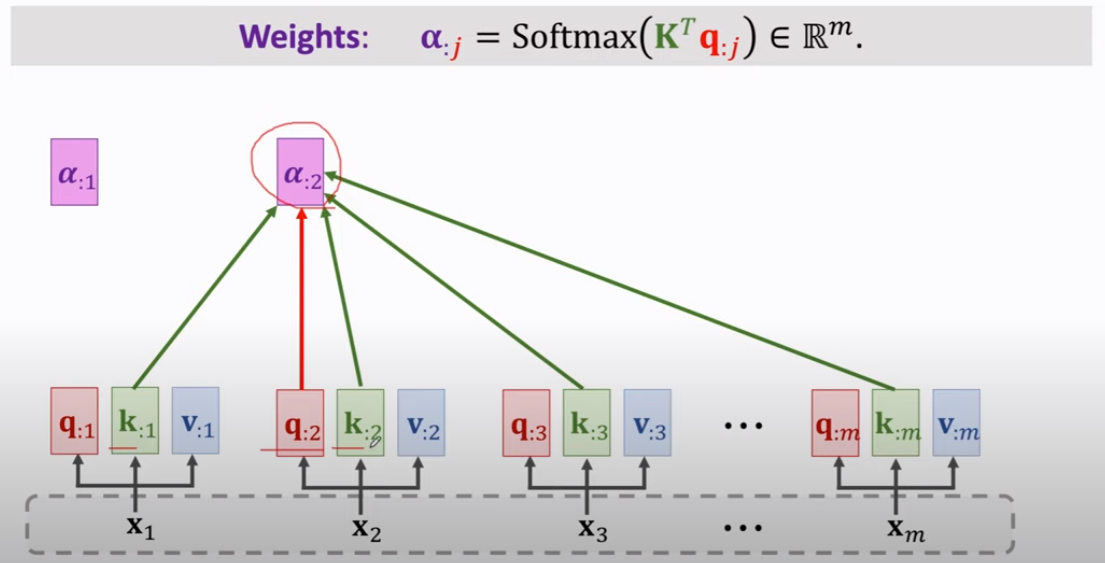
然后,alpha 与 v 计算得到 output c。
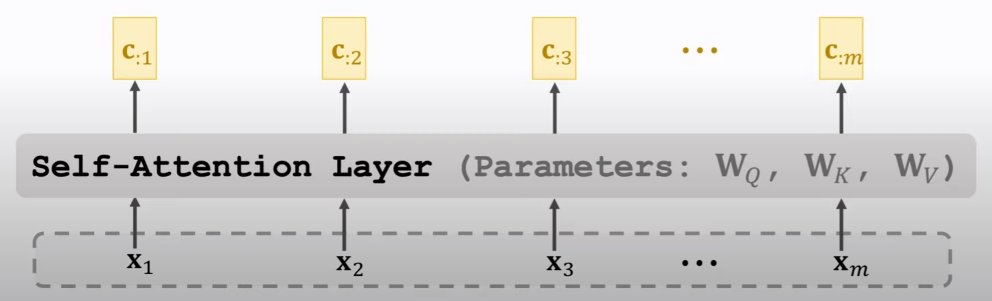
2017年,发现 attention 足以,而 RNN 是没有必要的。于是就出了这篇论文: Attention is All You Need.
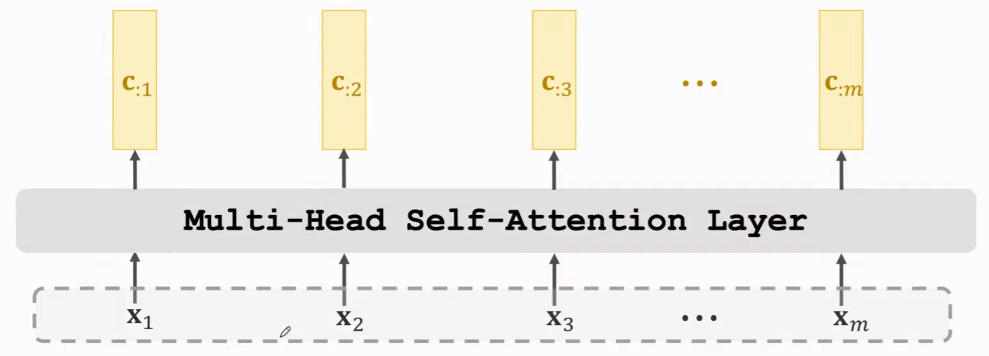
变为多头,各头参数不共享,如下。
为何多头?13 Transformer的多头注意力,Multi-Head Self-Attention(从空间角度解释为什么做多头)【作者声音听起来,比较通透】
具有了更好的 “特征表示”。下图的输出例如叫做 Z。是对X的新的表征(词向量),拥有了句法特征和语义特征。
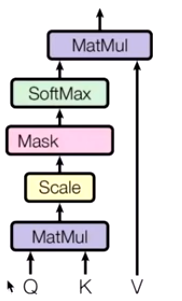
为何用多头?

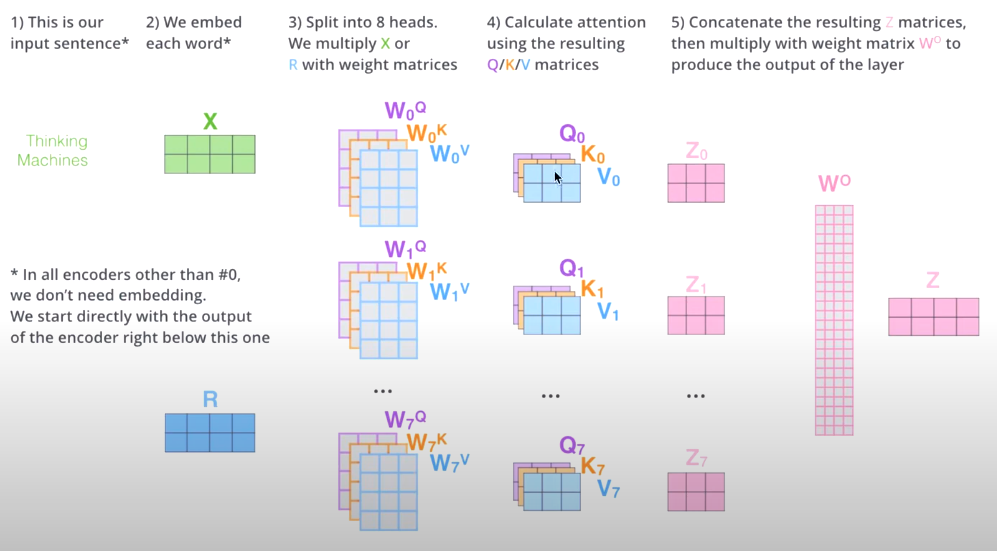
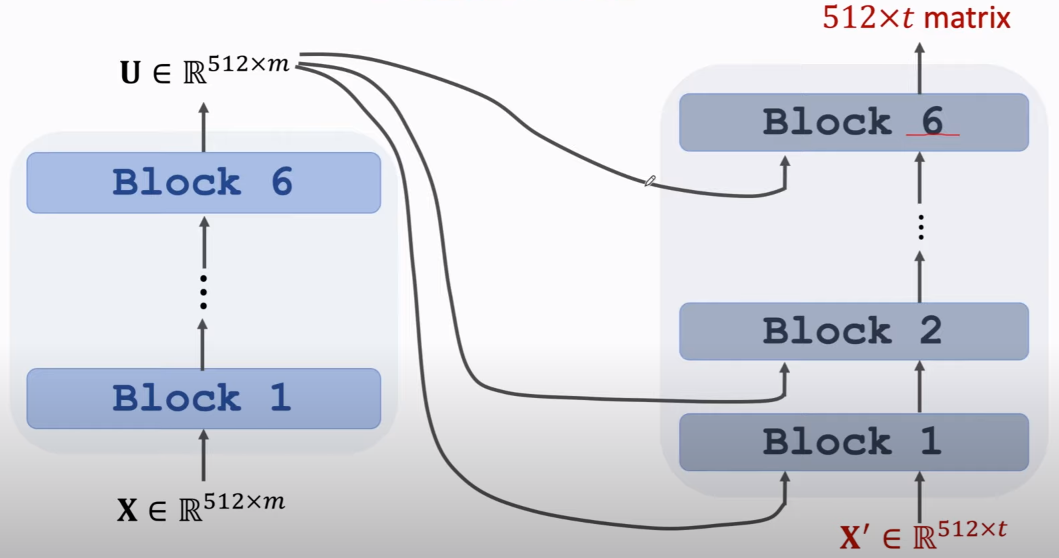
- 编码器的 Block
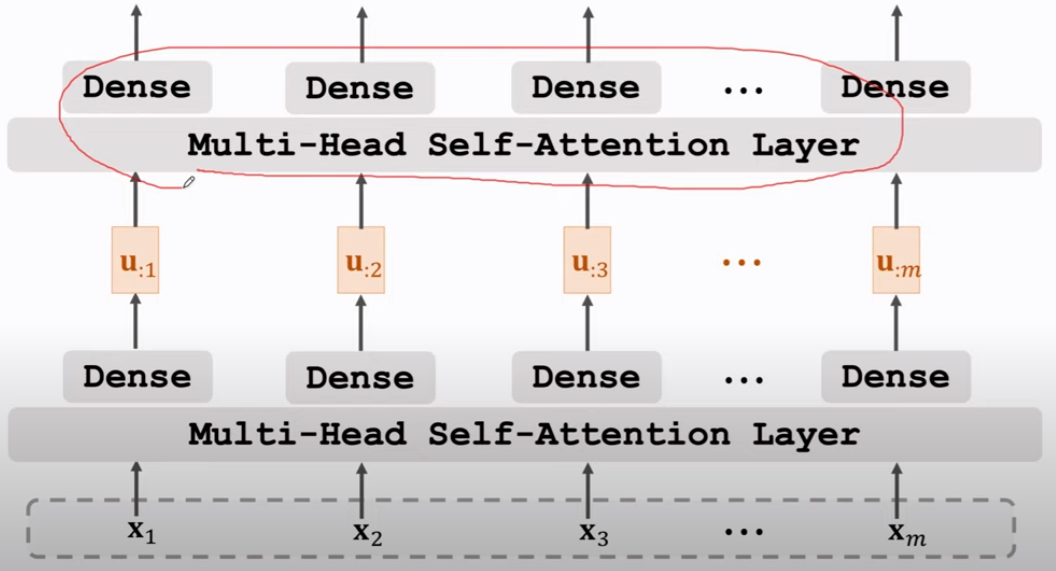
Goto: Stacked Self-Attention Layers
Stacked Self-Attention Layers,可以这么搭建(其中的Dense是一个,可理解为m次back-prop来更新这个dense)
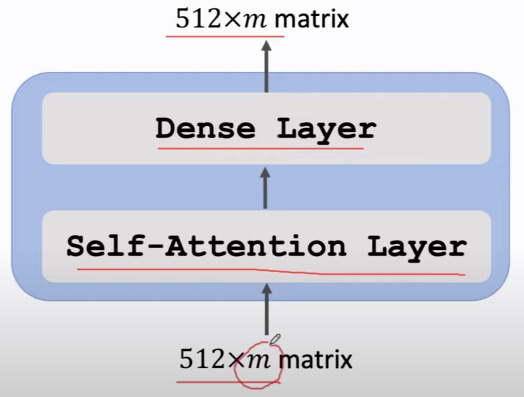
我们定义:Block 是 Self-Attention Layers + Dense
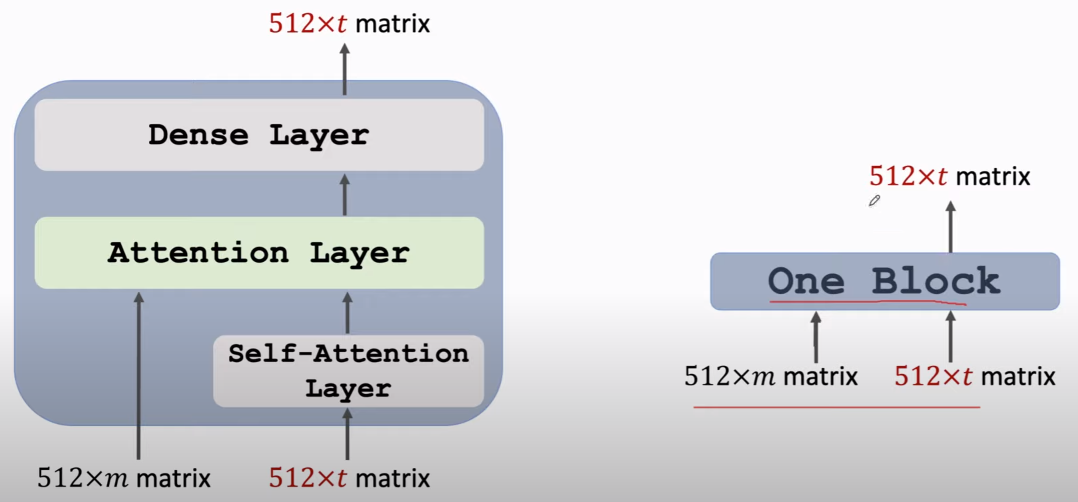
堆叠以构成一个深度网络 就可表示为如下:
Stacked Attention Layer,左边的部分可以接收 encoder's output,形成一次“交互”。
更多资料:
Transformers Explained Visually (Part 3): Multi-head Attention, deep dive [高赞文章]
Here’s a quick summary of the previous and following articles in the series. My goal throughout will be to understand not just how something works but why it works that way.
- Overview of functionality (How Transformers are used, and why they are better than RNNs. Components of the architecture, and behavior during Training and Inference)
- How it works(Internal operation end-to-end. How data flows and what computations are performed, including matrix representations)
- Multi-head Attention — this article (Inner workings of the Attention module throughout the Transformer)
- Why Attention Boosts Performance(Not just what Attention does but why it works so well. How does Attention capture the relationships between words in a sentence)
实战派
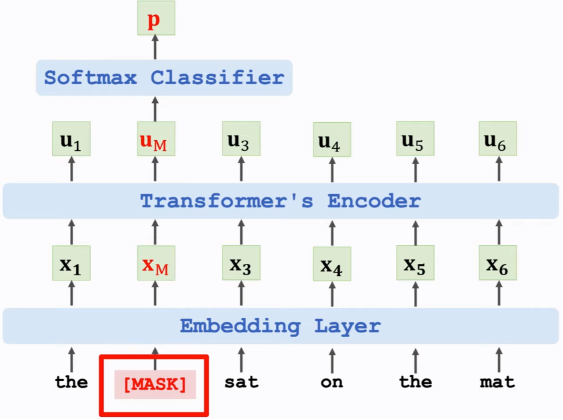
BERT就是两个任务的结合。
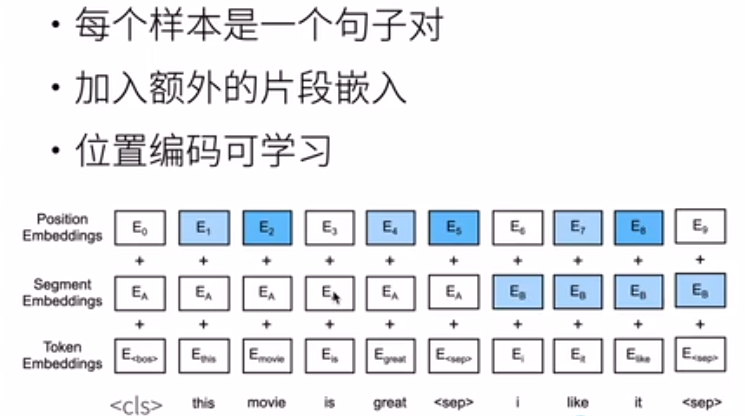
对于输入,有一些自己的特点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号