[Distributed ML] Horovod on Ray
Distributed Deep Learning Training with Horovod on Kubernetes【based on AWS】
Sagemaker Distributed Training with Parameter Server and Horovod【Sagemaker与Horovod 和 Ray 的关系】
Horovod for Deep Learning on a GPU Cluster
Distributed Deep Learning with Horovod on Ray - Travis Addair, Uber【内容之后转移到这里】
Running distributed TensorFlow training with Amazon SageMaker
要点总结
distributed TensorFlow training for the Mask R-CNN model on the Common Object in Context (COCO) 2017 dataset.
要使同步减少算法变得高效,存在三个主要挑战:
该算法需要随着分布式训练集群中节点和GPU数量的增加而扩展。
该算法需要利用单个节点内的高速GPU到GPU互连的拓扑。
该算法需要通过有效地批处理与其他GPU的通信来有效地交错GPU上的计算与与其他GPU的通信。
一、课前阅读
Scaling TensorFlow 2 models to multi-worker GPUs (TF Dev Summit '20)
讲解了TF 2.2的一些优化feature。
Distributed TensorFlow training (Google I/O '18)【讲的比较详细】
同步 or 异步 参数服务器
-
一机多卡 - 同步更新
以参数 为同步基础,我们可以采用 master-slave 的同步模式:将 node 分成两种角色:parameter server(ps) 负责维护一份最新的参数 ,worker 负责利用从 ps 读到的最新参数计算出梯度(forward 和 backprop),并对 ps 发送梯度和参数更新请求。这被称为 parameter server 的模式,tensorflow 就是围绕这个思路设计的。
Deep learning 之前的大规模模型通常体现在特征量上,模型仍旧是浅层的线性模型。特征量增大(百万到千万级别的特征量)带来的是特征的稀疏,所以每个 worker 平均只需要很少一部分变量就可以完成计算,和 ps 间的数据传输量不会很大。早期每个 host 的算力和资源量不大,所以增大计算规模往往意味着增大主机的数量,这带来的是 host 故障率的提高。 master-slave 的模式可以让系统拥有较好的容错能力。
但是现在随着模型的加深,参数之间的相互依赖增大,需要传输的参数量增大,使得 ps 的传输带宽逐渐成为瓶颈。而随着 host 计算能力的增强,我们需要的 host 数越来越少,故障率变低,容错的需求也越来越少。现在主流的做法更是变成了单机多卡。这使得 parameter server 的设计变得不适用于深度学习的计算。
-
异步更新
谷歌是最早使用 parameter server + 异步更新方案进行深度网络训练的。
异步更新是 parameter server 模式的标配,其收敛性已经有证明。
与同步更新不同,异步更新中 ps 在收到 worker 的梯度以及更新请求的时候,会立即对参数发起更新,而不等待其他 worker。在完成梯度的计算后,worker 会立刻从 ps 上读取参数,进行下一步的迭代。
Remind: 2018年的文章
但是异步更新的方案会引入两个不稳定性来源:
- 参数和更新用的梯度并不来自同一个迭代。用来更新的梯度可能是几步更新前的参数算出来的。
- 参数的读取并没有加锁。这导致 worker 可能会读到更新一半的参数。
对于落后于当前迭代的梯度(staled gradients),上述实现采取的做法是直接丢掉。这造成了不同 worker racing 的情况,对计算资源和数据的利用效率不高。
上述两个不稳定性来源要求模型采用更小的学习率(learning rate)。而小学习率加上上述的不稳定性会带来收敛速度的显著降低,同时训练发散(divergence)的风险也增大了,这两者抵消了异步训练带来的吞吐量的提高。实际使用中经常会看到 loss 有时候会突然变得很高(overshoot)。所以异步更新目前已经不是主流优化方向了。
-
一机多卡 - Allreduce 同步模式
在 Allreduce 模式中,所有 node 同时充当 ps 和 worker 的角色。
在目前简单的 ring-allreduce 的实现下,各个 node 需要发送和接受一份梯度。
parameter server + 异步更新会因为 node 数目的增加而使得 worker 平均可以使用的 PCIe 带宽减少。
Allreduce 模式则没有这个问题:由于使用了 ring-allreduce,传输耗时在一定规模内基本不随 node 数目的增加而变化,计算提速和 node 数目可以大致做到线性关系(linear scaling)。但集群规模变大的时候,由于卡间直连的成本变高,通常会设置多个中间通信节点(switch),从而产生网络阻塞,此时线性关系也不再成立。
同步更新也让我们可以使用比异步更新更大的学习率(learning rate),且训练发散(divergence)的风险和单卡训练一致。但当系统中存在异构的 worker 的时候,更新仍然会被最慢的 worker 阻塞住。所幸随着 host 的计算能力增强,计算需要的 host 数量减少,worker 同构的要求比较容易实现。
Allreduce 模式由于可扩展性强,现在已经渐渐成为主流的多卡/分布式训练方案。
-
Ring-Allreduce
ring-allreduce 假设各个 node 以一个环排列,这种假设可以适用于很多种拓扑结构,有其工程实现上的方便性。
可以理解为allreduce的进一步拓扑优化。
-
FP16 的提速
在带宽受限的场景下(通常是大规模集群),利用 FP32 计算完梯度后,可以将梯度转化成 FP16 (先将数值转换到 FP16 的有效范围) 再进行卡间同步。即使没有支持 FP16 计算单元的 GPU,这种提速也是很可观的。
但在带宽较大且 GPU 硬件受限的时候 (单机多卡 1080ti ), FP16 带来的提速仅限一小部分通信的提速,不值得浪费精力。
二、Kubernetes and distributed TF
/* implement */
三、SageMaker Solution
-
Define SageMaker Training Job
[计算选型]
We recommned using 32 GPUs, so we set instance_count=4 and instance_type='ml.p3.16xlarge', because there are 8 Tesla V100 GPUs per ml.p3.16xlarge instance. We recommend using 100 GB Amazon EBS storage volume with each training instance, so we set volume_size = 100.
[VPC + Yaml]
We run the training job in your private VPC, so we need to set the subnets and security_group_ids prior to running the cell below. You may specify multiple subnet ids in the subnets list. The subnets included in the sunbets list must be part of the output of ./stack-sm.sh CloudFormation stack script used to create this notebook instance. Specify only one security group id in security_group_ids list. The security group id must be part of the output of ./stack-sm.sh script.
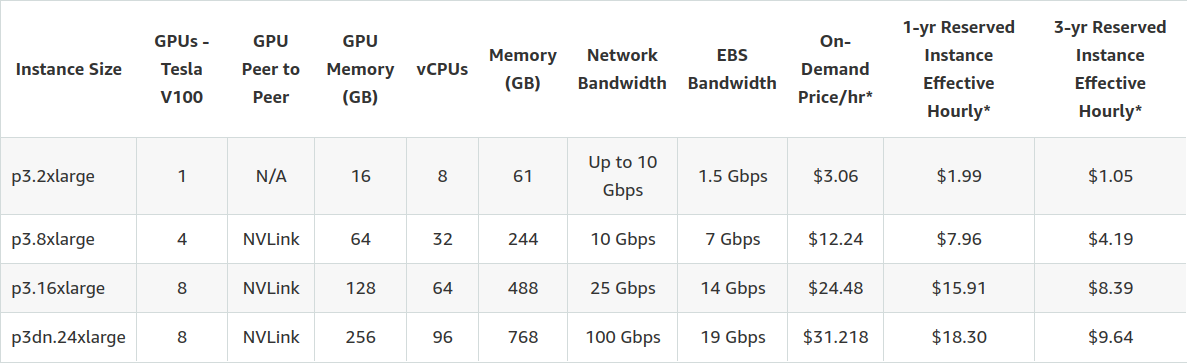
For instance_type below, you have the option to use ml.p3.16xlarge with 16 GB per-GPU memory and 25 Gbs network interconnectivity, or ml.p3dn.24xlarge with 32 GB per-GPU memory and 100 Gbs network interconnectivity. The ml.p3dn.24xlarge instance type offers significantly better performance than ml.p3.16xlarge for Mask R-CNN distributed TensorFlow training.
属于“一机多卡”。
security_group_ids = ['sg-043bfdabb0f3675fd'] # ['sg-xxxxxxxx'] subnets = ['subnet-0f9b8cc9c33f79763','subnet-0cc8d9f0eb3bf5c93','subnet-0fe2a35b1c5495531'] # [ 'subnet-xxxxxxx'] sagemaker_session = sagemaker.session.Session(boto_session=session) mask_rcnn_estimator = Estimator(image_uri = training_image, role = role, instance_count = 1, instance_type = 'ml.p3.16xlarge', volume_size = 100, max_run = 400000, output_path = s3_output_location, sagemaker_session = sagemaker_session, hyperparameters = hyperparameters, metric_definitions = metric_definitions, subnets = subnets, security_group_ids = security_group_ids)
Multi-GPU and distributed training using Horovod in Amazon SageMaker Pipe mode
In this post, I explain how to run multi-GPU training on a single instance on Amazon SageMaker, and discuss efficient multi-GPU and multi-node distributed training on Amazon SageMaker.
SageMaker uses the all-reduce algorithm for fast distributed training rather than using a parameter server approach, and includes multiple optimization methods to make distributed training faster.
When you start a training job using Horovod, Horovod launches an independent process for each worker per one GPU in the Horovod cluster.
For example, four worker processes start when you run a Horovod training job with one training instance with four GPUs (one Amazon SageMaker ml.p3.8xlarge or Amazon Elastic Compute Cloud (Amazon EC2) p3.8xlarge instance). All four Horovod workers read their own dataset, which is already split into shards as data parallelism. If there are 40,000 training samples, each worker gets 10,000 training samples without duplication. If you use Horovod for distributed training or even multi-GPU training, you should do this data shard preparation beforehand and let the worker read its shard from the file system. (There are deep learning frameworks that do this automatically on the fly, such as PyTorch’s DataParallel and DistributedDataParallel.)
Ref: https://aws.amazon.com/ec2/instance-types/p3/
属于“一机多卡”。
End.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号