[SageMaker] DNN with Amazon SageMaker
进化过程
训练图像分类的课程:https://www.udemy.com/course/practical-aws-sagemaker-6-real-world-case-studies/
一、Keras 传统例子
-
构建与训练
import tensorflow as tf from tensorflow import keras from tensorflow.keras.layers import Dense, Activation, Dropout, BatchNormalization from tensorflow.keras.optimizers import Adam # optimizer = Adam() ANN_model = keras.Sequential() ANN_model.add(Dense(50, input_dim = 8)) ANN_model.add(Activation('relu')) ANN_model.add(Dense(150)) ANN_model.add(Activation('relu')) ANN_model.add(Dropout(0.5)) ANN_model.add(Dense(150)) ANN_model.add(Activation('relu')) ANN_model.add(Dropout(0.5)) ANN_model.add(Dense(50)) ANN_model.add(Activation('linear')) ANN_model.add(Dense(1)) ANN_model.compile(loss = 'mse', optimizer = 'adam') ANN_model.summary() ANN_model.compile(optimizer='Adam', loss='mean_squared_error') epochs_hist = ANN_model.fit(X_train, y_train, epochs = 100, batch_size = 20, validation_split = 0.2)
-
度量一
result = ANN_model.evaluate(X_test, y_test) accuracy_ANN = 1 - result print("Accuracy : {}".format(accuracy_ANN))
-
度量二
epochs_hist.history.keys() # dict_keys(['loss', 'val_loss']),可以查看这两个指标 plt.plot(epochs_hist.history['loss']) plt.plot(epochs_hist.history['val_loss']) plt.title('Model Loss Progress During Training') plt.xlabel('Epoch') plt.ylabel('Training and Validation Loss') plt.legend(['Training Loss', 'Validation Loss'])
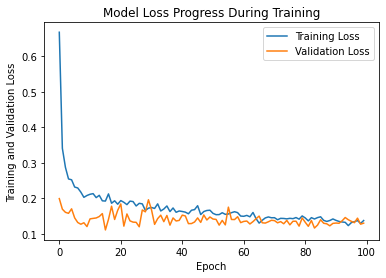
-
度量三
y_predict = ANN_model.predict(X_test) plt.plot(y_test, y_predict, "^", color = 'r') plt.xlabel('Model Predictions') plt.ylabel('True Values')
# 反 “去中心化” 后再可视化 y_predict_orig = scaler_y.inverse_transform(y_predict) y_test_orig = scaler_y.inverse_transform(y_test) plt.plot(y_test_orig, y_predict_orig, "^", color = 'r') plt.xlabel('Model Predictions') plt.ylabel('True Values')
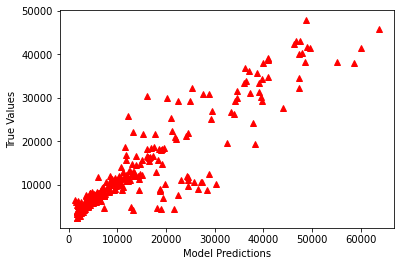
-
度量四
k = X_test.shape[1] n = len(X_test) n from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error from math import sqrt RMSE = float(format(np.sqrt(mean_squared_error(y_test_orig, y_predict_orig)),'.3f')) MSE = mean_squared_error(y_test_orig, y_predict_orig) MAE = mean_absolute_error(y_test_orig, y_predict_orig) r2 = r2_score(y_test_orig, y_predict_orig) adj_r2 = 1-(1-r2)*(n-1)/(n-k-1) print('RMSE =',RMSE, '\nMSE =',MSE, '\nMAE =',MAE, '\nR2 =', r2, '\nAdjusted R2 =', adj_r2)
二、SageMaker: 间接调用一个训练代码
[AWS 通用的识别接口]
Ref: AWS Innovate | Intro to Deep Learning: Building an Image Classifier on Amazon SageMaker
Ref: https://us-west-2.console.aws.amazon.com/rekognition/home?region=us-west-2#/video-analysis
先瞧瞧 改为 SageMaker 的套路是怎么回事?
-
传参
[Reminder] tf_estimator.fit 可不是boto3的接口哦。
from sagemaker.tensorflow import TensorFlow tf_estimator = TensorFlow(entry_point='train-cnn.py', role=role, train_instance_count=1, train_instance_type='ml.c4.2xlarge', framework_version='1.12', py_version='py3', script_mode=True, hyperparameters={ 'epochs': 2 , 'batch-size': 32, 'learning-rate': 0.001,
'gpu-count': 1} )
# 这里,是不是还可以顺便把 gpu-count, model-dir 带上? tf_estimator.fit({'training': training_input_path, 'validation': validation_input_path})
-
训练
单独的 TF training 文件,注意,该文件如何接收上面提供的超参数:hyperparameters。
import argparse, os import numpy as np import tensorflow from tensorflow.keras import backend as K from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Dropout, Activation, Flatten, BatchNormalization, Conv2D, MaxPooling2D, AveragePooling2D from tensorflow.keras.optimizers import Adam from tensorflow.keras.utils import multi_gpu_model # The training code will be contained in a main gaurd (if __name__ == '__main__') so SageMaker will execute the code found in the main. # argparse: if __name__ == '__main__': # Parser to get the arguments parser = argparse.ArgumentParser() # Model hyperparameters are being sent as command-line arguments. parser.add_argument('--epochs', type=int, default=1) parser.add_argument('--learning-rate', type=float, default=0.001) parser.add_argument('--batch-size', type=int, default=32) # The script receives environment variables in the training container instance. # SM_NUM_GPUS: how many GPUs are available for trianing. # SM_MODEL_DIR: A string indicating output path where model artifcats will be sent out to. # SM_CHANNEL_TRAIN: path for the training channel # SM_CHANNEL_VALIDATION: path for the validation channel parser.add_argument('--gpu-count', type=int, default=os.environ['SM_NUM_GPUS']) parser.add_argument('--model-dir', type=str, default=os.environ['SM_MODEL_DIR']) parser.add_argument('--training', type=str, default=os.environ['SM_CHANNEL_TRAINING']) parser.add_argument('--validation', type=str, default=os.environ['SM_CHANNEL_VALIDATION']) args, _ = parser.parse_known_args() # Hyperparameters epochs = args.epochs lr = args.learning_rate batch_size = args.batch_size gpu_count= args.gpu_count model_dir = args.model_dir training_dir = args.training validation_dir = args.validation # Loading the training and validation data from s3 bucket train_images = np.load(os.path.join(training_dir, 'training.npz' ))['image'] train_labels = np.load(os.path.join(training_dir, 'training.npz' ))['label'] test_images = np.load(os.path.join(validation_dir, 'validation.npz'))['image'] test_labels = np.load(os.path.join(validation_dir, 'validation.npz'))['label'] K.set_image_data_format('channels_last') # Adding batch dimension to the input train_images = train_images.reshape(train_images.shape[0], 32, 32, 3) test_images = test_images.reshape(test_images.shape[0], 32, 32, 3) input_shape = (32, 32, 3) # Normalizing the data train_images = train_images.astype('float32') test_images = test_images.astype('float32') train_images /= 255 test_images /= 255 train_labels = tensorflow.keras.utils.to_categorical(train_labels, 43) test_labels = tensorflow.keras.utils.to_categorical(test_labels, 43) #LeNet Network Architecture model = Sequential() model.add(Conv2D(filters=6, kernel_size=(5, 5), activation='relu', input_shape= input_shape)) model.add(AveragePooling2D()) model.add(Conv2D(filters=16, kernel_size=(5, 5), activation='relu')) model.add(AveragePooling2D()) model.add(Flatten()) model.add(Dense(units=120, activation='relu')) model.add(Dense(units=84, activation='relu')) model.add(Dense(units=43, activation = 'softmax')) print(model.summary()) # If more than one GPU is available, convert the model to multi-gpu model if gpu_count > 1: model = multi_gpu_model(model, gpus=gpu_count) # Compile and train the model model.compile(loss=tensorflow.keras.losses.categorical_crossentropy, optimizer=Adam(lr=lr), metrics=['accuracy']) model.fit(train_images, train_labels, batch_size=batch_size, validation_data=(test_images, test_labels), epochs=epochs, verbose=2) # Evaluating the model score = model.evaluate(test_images, test_labels, verbose=0) print('Validation loss :', score[0]) print('Validation accuracy:', score[1]) # save trained CNN Keras model to "model_dir" (path specificied earlier) sess = K.get_session() tensorflow.saved_model.simple_save( sess, os.path.join(model_dir, 'model/1'), inputs={'inputs': model.input}, outputs={t.name: t for t in model.outputs})
一个遗留的奇怪问题,gpu变多了,为了 training duration 并未减小?


Train on 34799 samples, validate on 12630 samples Epoch 1/2 2021-01-08 11:12:20 Training - Training image download completed. Training in progress. - 18s - loss: 1.2888 - acc: 0.6346 - val_loss: 0.8079 - val_acc: 0.7871 Epoch 2/2 - 4s - loss: 0.3251 - acc: 0.9054 - val_loss: 0.6253 - val_acc: 0.8528 Validation loss : 0.6252862956253952 Validation accuracy: 0.8528107680221069 WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/saved_model/simple_save.py:85: calling SavedModelBuilder.add_meta_graph_and_variables (from tensorflow.python.saved_model.builder_impl) with legacy_init_op is deprecated and will be removed in a future version. Instructions for updating: Pass your op to the equivalent parameter main_op instead. 2021-01-08 11:12:28,434 sagemaker-containers INFO Reporting training SUCCESS 2021-01-08 11:12:40 Uploading - Uploading generated training model 2021-01-08 11:12:40 Completed - Training job completed Training seconds: 68 Billable seconds: 68 Duration is 252.96774005889893
Train on 34799 samples, validate on 12630 samples Epoch 1/2 2021-01-08 11:12:20 Training - Training image download completed. Training in progress. - 18s - loss: 1.2888 - acc: 0.6346 - val_loss: 0.8079 - val_acc: 0.7871 Epoch 2/2 - 4s - loss: 0.3251 - acc: 0.9054 - val_loss: 0.6253 - val_acc: 0.8528 Validation loss : 0.6252862956253952 Validation accuracy: 0.8528107680221069 WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/saved_model/simple_save.py:85: calling SavedModelBuilder.add_meta_graph_and_variables (from tensorflow.python.saved_model.builder_impl) with legacy_init_op is deprecated and will be removed in a future version. Instructions for updating: Pass your op to the equivalent parameter main_op instead. 2021-01-08 11:12:28,434 sagemaker-containers INFO Reporting training SUCCESS 2021-01-08 11:12:40 Uploading - Uploading generated training model 2021-01-08 11:12:40 Completed - Training job completed Training seconds: 68 Billable seconds: 68 Duration is 252.96774005889893
-
部署
tf_predictor = tf_estimator.deploy(initial_instance_count = 1, instance_type = 'ml.t2.medium', endpoint_name = tf_endpoint_name)
######################################################### %matplotlib inline import random import matplotlib.pyplot as plt #Pre-processing the images num_samples = 5 indices = random.sample(range(X_test.shape[0] - 1), num_samples) # 这里虽然归一化了,但不影响imshow的图片显示 images = X_test[indices]/255 labels = y_test[indices] for i in range(num_samples): plt.subplot(1,num_samples,i+1) plt.imshow(images[i]) plt.title(labels[i]) plt.axis('off') # Making predictions prediction = tf_predictor.predict(images.reshape(num_samples, 32, 32, 3))['predictions'] prediction = np.array(prediction) predicted_label = prediction.argmax(axis=1) print('Predicted labels are: {}'.format(predicted_label))
######################################################### # Deleting the end-point tf_predictor.delete_endpoint()
三、SageMaker: 内置算法
Goto: https://github.com/PacktPublishing/Learn-Amazon-SageMaker/tree/master/sdkv2/ch5
[此人 Julien Simon 很dier,也是作者]

(1) Using Script Mode with Amazon SageMaker
(2) End to end demo with Keras and Amazon SageMaker
制定了图像分类的 container,设置对应的超参数即可;相比而言,这里省略了 训练代码部分。
# Get the name of the image classification algorithm in our region from sagemaker import image_uris region = boto3.Session().region_name container = image_uris.retrieve('image-classification', region) print(container)
# Configure the training job role = sagemaker.get_execution_role() ic = sagemaker.estimator.Estimator(container, role, instance_count=1, instance_type='ml.p2.xlarge', output_path=s3_output)
# Set algorithm parameters ic.set_hyperparameters(num_layers=18, # Train a Resnet-18 model use_pretrained_model=0, # Train from scratch num_classes=2, # Dogs and cats num_training_samples=22500, # Number of training samples mini_batch_size=128, resize=224, epochs=10) # Learn the training samples 10 times
# Set dataset parameters train_data = sagemaker.TrainingInput(s3_train_path, distribution='FullyReplicated', content_type='application/x-image', s3_data_type='S3Prefix') val_data = sagemaker.TrainingInput(s3_val_path, distribution='FullyReplicated', content_type='application/x-image', s3_data_type='S3Prefix') train_lst_data = sagemaker.TrainingInput(s3_train_lst_path, distribution='FullyReplicated', content_type='application/x-image', s3_data_type='S3Prefix') val_lst_data = sagemaker.TrainingInput(s3_val_lst_path, distribution='FullyReplicated', content_type='application/x-image', s3_data_type='S3Prefix') s3_channels = {'train': train_data, 'validation': val_data, 'train_lst': train_lst_data, 'validation_lst': val_lst_data}
# Train the model %%time ic.fit(inputs=s3_channels)
[Reminder] ic.fit 可不是boto3的接口哦。
四、Boto3 接口方案
-
要点
[Reminder] 上述可见,built-in和tf接口都是用了SageMaker提供的接口,下面我们使用 boto3的接口来做一次训练。
说白了,就是 fit() 没了,替代为 create_training_job()。
因为是在第三方运行,例如 Lambda,而不是在 Notebook,所以,boto3。
获取 image-classification 的 docker image。
containers = {'us-west-2': '433757028032.dkr.ecr.us-west-2.amazonaws.com/image-classification:latest',
'us-east-1': '811284229777.dkr.ecr.us-east-1.amazonaws.com/image-classification:latest',
'us-east-2': '825641698319.dkr.ecr.us-east-2.amazonaws.com/image-classification:latest',
'eu-west-1': '685385470294.dkr.ecr.eu-west-1.amazonaws.com/image-classification:latest'}
training_image = containers[boto3.Session().region_name]
可以是 自定义的 镜像么?
Ref: Unable to use this library in AWS Lambda due to package size exceeded max limit #1200
配套视频:Image classification with Amazon SageMaker【本节参考】
貌似不可以,但如果 use Sagemaker Python SDK in Lambda 就还行,链接中野路子可以使用。
-
超参数
(1) TF接口,默认TF image时的 log的一部分。
Training Env: { "additional_framework_parameters": {}, "channel_input_dirs": { "training": "/opt/ml/input/data/training", "validation": "/opt/ml/input/data/validation" }, "current_host": "algo-1", "framework_module": "sagemaker_tensorflow_container.training:main", "hosts": [ "algo-1" ], "hyperparameters": { "batch-size": 32, "learning-rate": 0.001, "gpu-count": 4, "model_dir": "s3://sagemaker-us-east-1-006635943311/sagemaker-tensorflow-scriptmode-2021-01-08-10-57-25-977/model", "epochs": 2 }, "input_config_dir": "/opt/ml/input/config", "input_data_config": { "training": { "TrainingInputMode": "File", "S3DistributionType": "FullyReplicated", "RecordWrapperType": "None" }, "validation": { "TrainingInputMode": "File", "S3DistributionType": "FullyReplicated", "RecordWrapperType": "None" } }, "input_dir": "/opt/ml/input", "is_master": true, "job_name": "sagemaker-tensorflow-scriptmode-2021-01-08-11-03-39-505", "log_level": 20, "master_hostname": "algo-1", "model_dir": "/opt/ml/model", "module_dir": "s3://sagemaker-us-east-1-006635943311/sagemaker-tensorflow-scriptmode-2021-01-08-11-03-39-505/source/sourcedir.tar.gz", "module_name": "train-cnn", "network_interface_name": "eth0", "num_cpus": 32, "num_gpus": 4, "output_data_dir": "/opt/ml/output/data", "output_dir": "/opt/ml/output", "output_intermediate_dir": "/opt/ml/output/intermediate", "resource_config": { "current_host": "algo-1", "hosts": [ "algo-1" ], "network_interface_name": "eth0" }, "user_entry_point": "train-cnn.py" }
(2) boto3 接口的 超参数设置。
training_params = \ { # specify the training docker image "AlgorithmSpecification": { "TrainingImage": training_image, "TrainingInputMode": "File" }, "RoleArn": role, "OutputDataConfig": { "S3OutputPath": 's3://{}/{}/output'.format(bucket, job_name_prefix) }, "ResourceConfig": { "InstanceCount": 1, "InstanceType": "ml.p2.8xlarge", "VolumeSizeInGB": 50 }, "TrainingJobName": job_name, "HyperParameters": { "image_shape": image_shape, "num_layers": str(num_layers), "num_training_samples": str(num_training_samples), "num_classes": str(num_classes), "mini_batch_size": str(mini_batch_size), "epochs": str(epochs), "learning_rate": str(learning_rate), "use_pretrained_model": str(use_pretrained_model) }, "StoppingCondition": { "MaxRuntimeInSeconds": 360000 }, # Training data should be inside a subdirectory called "train" # Validation data should be inside a subdirectory called "validation" # The algorithm currently only supports fullyreplicated model (where data is copied onto each machine) "InputDataConfig": [ { "ChannelName": "train", "DataSource": { "S3DataSource": { "S3DataType": "S3Prefix", "S3Uri": 's3://{}/train/cifar10'.format(bucket), "S3DataDistributionType": "FullyReplicated" } }, "ContentType": "application/x-recordio", "CompressionType": "None" }, { "ChannelName": "validation", "DataSource": { "S3DataSource": { "S3DataType": "S3Prefix", "S3Uri": 's3://{}/validation/cifar10'.format(bucket), "S3DataDistributionType": "FullyReplicated" } }, "ContentType": "application/x-recordio", "CompressionType": "None" } ] }
-
开始训练
# (1) create the Amazon SageMaker training job sagemaker = boto3.client(service_name='sagemaker') sagemaker.create_training_job(**training_params)
get_waiter 监控模式:
# (1.1) confirm that the training job has started status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus'] print('Training job current status: {}'.format(status)) try: # wait for the job to finish and report the ending status sagemaker.get_waiter('training_job_completed_or_stopped').wait(TrainingJobName=job_name) training_info = sagemaker.describe_training_job(TrainingJobName=job_name) status = training_info['TrainingJobStatus'] print("Training job ended with status: " + status) except: print('Training failed to start') # if exception is raised, that means it has failed message = sagemaker.describe_training_job(TrainingJobName=job_name)['FailureReason'] print('Training failed with the following error: {}'.format(message))
[对比] client可以通过sagemaker的原生API获得,并有自己的一个套路。
client = estimator.sagemaker_session.sagemaker_client
while 监控模式:
import time # 实时监控 training 过程 description = client.describe_training_job(TrainingJobName=job_name) if description['TrainingJobStatus'] != 'Completed': while description['SecondaryStatus'] not in {'Training', 'Completed'}: description = client.describe_training_job(TrainingJobName=job_name) primary_status = description['TrainingJobStatus'] secondary_status = description['SecondaryStatus'] print('Current job status: [PrimaryStatus: {}, SecondaryStatus: {}]'.format(primary_status, secondary_status)) time.sleep(15)
部署与触发
Create Endpoint
一、在 SageMaker Notebook 中
上述的部署方式,涉及到以下三个关键方法。
tf_predictor = tf_estimator.deploy(initial_instance_count = 1, instance_type = 'ml.t2.medium', endpoint_name = tf_endpoint_name) prediction = tf_predictor.predict(images.reshape(num_samples, 32, 32, 3))['predictions'] # Deleting the end-point tf_predictor.delete_endpoint()
二、Boto3 创建 Endpoint
-
Create Model
链接 SageMaker 服务,准备 container 环境,也就是软体信息。
%%time import boto3 from time import gmtime, strftime sage= boto3.Session().client(service_name='sagemaker') ########################################################### model_name="image-classification-cifar-transfer" ########################################################### # 获取 retrained 模型 info = sage.describe_training_job(TrainingJobName=job_name) model_data = info['ModelArtifacts']['S3ModelArtifacts'] print(model_data) # --------------------------------------------------------- # 获取 镜像 containers = {'us-west-2': '433757028032.dkr.ecr.us-west-2.amazonaws.com/image-classification:latest', 'us-east-1': '811284229777.dkr.ecr.us-east-1.amazonaws.com/image-classification:latest', 'us-east-2': '825641698319.dkr.ecr.us-east-2.amazonaws.com/image-classification:latest', 'eu-west-1': '685385470294.dkr.ecr.eu-west-1.amazonaws.com/image-classification:latest'} hosting_image = containers[boto3.Session().region_name]
# ---------------------------------------------------------
# 构成了 推断 环境 primary_container = { 'Image': hosting_image, 'ModelDataUrl': model_data, }
于是,创建了 endpoint 基本环境: 也就是 model 的运行环境 primary container
create_model_response =sage.create_model( ModelName = model_name, ExecutionRoleArn = role, PrimaryContainer = primary_container) print(create_model_response['ModelArn'])
 有了 ModelArn
有了 ModelArn
-
Create Endpoint Configuration
何为配置?关于实例的硬件选择等信息。
from time import gmtime, strftime timestamp = time.strftime('-%Y-%m-%d-%H-%M-%S', time.gmtime()) endpoint_config_name = job_name_prefix + '-epc-' + timestamp endpoint_config_response =sage.create_endpoint_config( EndpointConfigName = endpoint_config_name, ProductionVariants = [{ 'InstanceType':'ml.m4.xlarge', 'InitialInstanceCount':1, 'ModelName':model_name, 'VariantName':'AllTraffic'}]) print('Endpoint configuration name: {}'.format(endpoint_config_name)) print('Endpoint configuration arn: {}'.format(endpoint_config_response['EndpointConfigArn']))
 有了 EndpointConfigArn
有了 EndpointConfigArn
-
Create Endpoint
可见,Endpoint 包含了 EndpointConfig,EndpointConfig 包含了 Model。
%%time import time timestamp = time.strftime('-%Y-%m-%d-%H-%M-%S', time.gmtime()) endpoint_name = job_name_prefix + '-ep-' + timestamp endpoint_params = { 'EndpointName': endpoint_name, 'EndpointConfigName': endpoint_config_name, } endpoint_response = sagemaker.create_endpoint(**endpoint_params)
print('EndpointArn = {}'.format(endpoint_response['EndpointArn']))
有了EndpointArn
三、部署一个现成的 模型
例如,模型已经在s3上备好。
来自于加:t81_558_deep_learning/t81_558_class_13_02_cloud.ipynb,老版本。
The entry_point file "train.py" can be an empty Python file. AWS currently requires this step; however, AWS will likely remove this requirement at a later date.
from sagemaker.tensorflow.model import TensorFlowModel
sagemaker_model = TensorFlowModel(model_data = 's3://' + sagemaker_session.default_bucket() + '/model/model.tar.gz', role = role, framework_version = '1.12', entry_point = 'train.py')
%%time predictor = sagemaker_model.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')
Endpoint for inference
链接 runtime 服务。
import boto3 runtime = boto3.Session().client(service_name='runtime.sagemaker')
通过名字进行定位endpoint服务,也就是“推断模型”。
import json import numpy as np with open(file_name, 'rb') as f: payload = f.read() payload = bytearray(payload) # # 上述 备好 input 数据,即开始 推断。 # response = runtime.invoke_endpoint(EndpointName=endpoint_name, # <---- 定位 endpoint ContentType='application/x-image', Body=payload) result = response['Body'].read() # result will be in json format and convert it to ndarray
End.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号