
[AWS] 08 - SageMaker Architecture
典型的应用架构:aws-modern-application-workshop/images/module-7/sagemaker-architecture.png
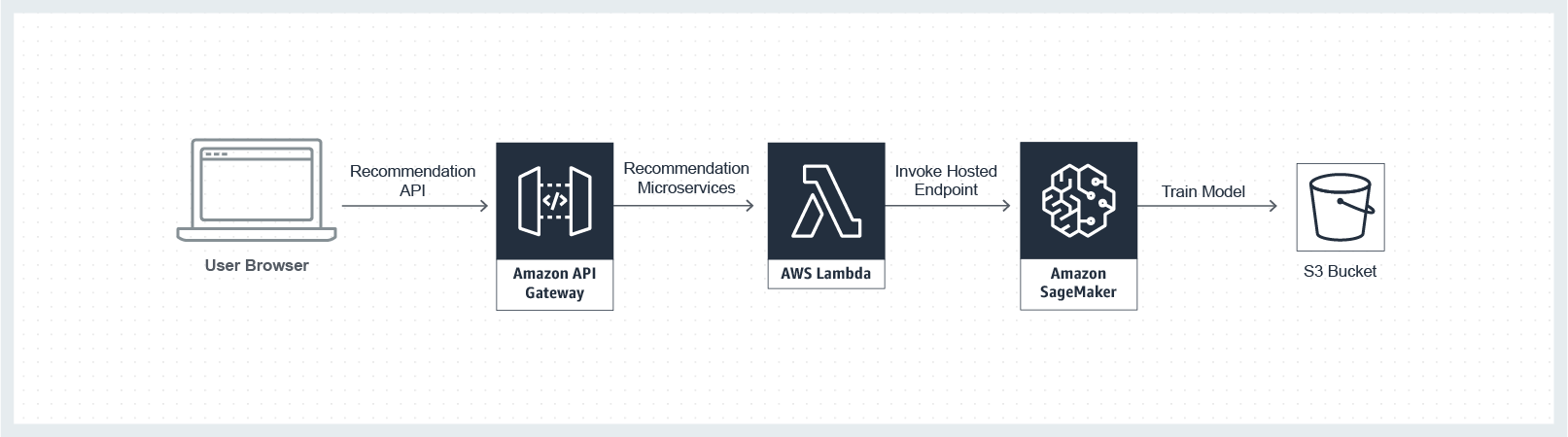
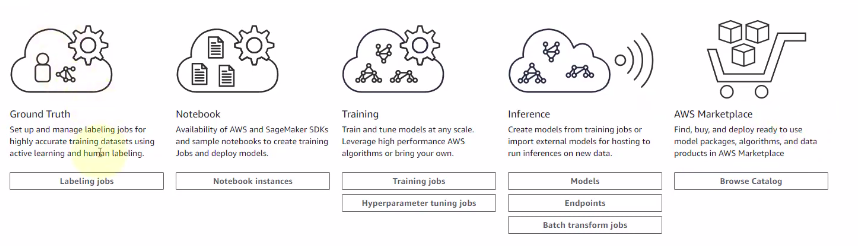
宏观介绍
Ref: AWS SageMaker in 10 Minutes! (Artificial Intelligence & Machine Learning with Amazon Web Services)
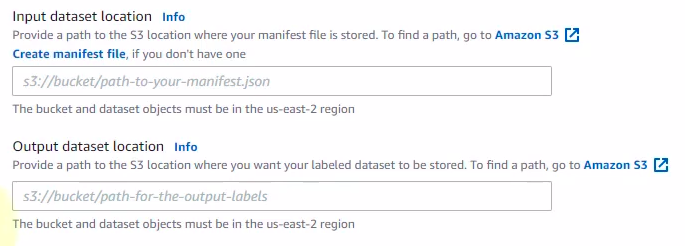
1. Labeling jobs
输入和输出都是s3 path。
2. Notebook
代码示范:https://github.com/data-science-on-aws/workshop 【她的示范代码】
AI and Machine Learning with Kubeflow, Amazon EKS, and SageMaker.

她的频道:PipelineAI
配置好后,点击 Open Jupyter
如何 在第三方 trigger "training, inference"?
她的书,2021年发行。

Following the Bezos API Mandate, we will deploy our model as a REST API using SageMaker Endpoints.
3. 训练 Training (SM Python SDK)
参考:Create and Run a Training Job (Amazon SageMaker Python SDK)
先创建好工程,也就是 notebook instance,然后就是:步骤 5: 训练模型
step 1, 获取特定内置算法的容器: XGBoost。
import sagemaker from sagemaker.amazon.amazon_estimator import get_image_uri container = get_image_uri(boto3.Session().region_name, 'xgboost')
step 2, 准备好s3上的数据。
train_data = 's3://{}/{}/{}'.format(bucket, prefix, 'train') validation_data = 's3://{}/{}/{}'.format(bucket, prefix, 'validation') s3_output_location = 's3://{}/{}/{}'.format(bucket, prefix, 'xgboost_model_sdk')
step 3, 训练时的instance。
xgb_model = sagemaker.estimator.Estimator(container, role, train_instance_count=1, train_instance_type='ml.m4.xlarge', train_volume_size = 5, output_path=s3_output_location, sagemaker_session=sagemaker.Session())
step 4, 设置超参数。
xgb_model.set_hyperparameters(max_depth = 5, eta = .2, gamma = 4, min_child_weight = 6, silent = 0, objective = "multi:softmax", num_class = 10, num_round = 10)
step 5, 创建用于训练作业的训练通道。
train_channel = sagemaker.session.s3_input(train_data, content_type='text/csv') valid_channel = sagemaker.session.s3_input(validation_data, content_type='text/csv') data_channels = {'train': train_channel, 'validation': valid_channel}
step 6, 启动模型训练,调用评估程序的 fit 方法
xgb_model.fit(inputs=data_channels, logs=True)
4. 训练 Training (Boto3 SDK)
Ref: 1. calling a SageMaker model endpoint using API Gateway and Lambda function in AWS【小姑娘的】
Ref: 2. Call an Amazon SageMaker model endpoint using Amazon API Gateway and AWS Lambda【小姑娘的】
Ref: 3. Call an Amazon SageMaker model endpoint using Amazon API Gateway and AWS Lambda【官方的】
工作流程: API Gateway + Lambda + Endpoint
-
创建实例
instance type, repo, ...
选择模板:Breast Cancer dataset
2:16 / 14:11开始讲解代码。
-
定义一个 training job
[64] - [108]
linear_training_params 做什么的呢?
参考:Create and Run a Training Job (AWS SDK for Python (Boto3))
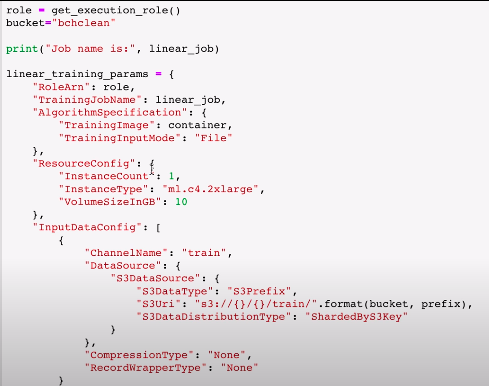
region = boto3.Session().region_name sm = boto3.client('sagemaker') sm.create_training_job(**linear_training_params) status = sm.describe_training_job(TrainingJobName=linear_job) print(status) sm.get_waiter('training_job_completed_or_stopped').wait(TrainingJobName=linear_job) if status == 'Failed': message = sm.describe_training_job(TrainingJobName=linear_job)['FailureReason'] print('Training failed with the following error:{}'.format(message)) raise Exception('Training job failed')
5. 推断 Inference
-
setup 一个模型
linear_hosting_container = { 'Image': container, 'ModelDataUrl': sm.describe_training_job(TrainingJobMame=linear_job)['ModelArtifacts']['S3ModelArtifacts'] } create_model_response = sm.create_model( ModelName = linear_job, ExecutionRoleArn = role, PrimaryContainer = linear_hosting_container )
-
配置 endpoint
sm.create_endpoint_config(...)

sm.create_endpoint(...)
sm.describe_endpoint(...)

-
Predict
runtime.invoke_endpoint(...)

================= 这里开始是 lambda 的配置 =====================
-
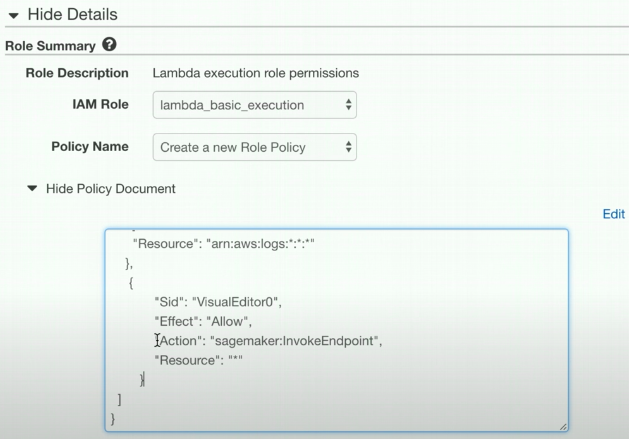
Create a custom role [Lambda configure]
首先,创建Lambda过程中,设置role for 操作 sagemaker,能invoke endpoint。

然后,加入到lambda的policy中,有了invoke endpoint的能力。
-
Invoke Sagemaker Endpoint [Lambda content]
Lambda 如何触发endpoint? 通过:runtime.invoke_endpoint()
触发完成后,还紧接着接收了inference结果。
import os import io import boto3 import json import csv # grab environment variables ENDPOINT_NAME = os.environ['ENDPOINT_NAME'] runtime = boto3.client('runtime.sagemaker') def lambda_handler(event, context): print("Received event: " + json.dumps(event, indent=2)) data = json.loads(json.dumps(event)) payload = data['data'] print(payload) response = runtime.invoke_endpoint(EndpointName=ENDPOINT_NAME, ContentType='text/csv', Body=payload) print(response) result = json.loads(response['Body'].read().decode()) print(result) pred = int(result['predictions'][0]['score']) predicted_label = 'M' if pred == 1 else 'B' return predicted_label
Environment Variables,在上述的“配置endpoint”中create_endpoint(...) 提及了 endpoint的 name,然后填写如下。
Key: ENDPOINT_NAME Value: DEMO-linear-endpoint-201812102219

更多内容,请见:Amazon SageMaker 开发人员指南
性能 Scaling
Ref: Scale up Training of Your ML Models with Distributed Training on Amazon SageMaker
三种方式扩展 node,链接中视频 1:47 / 15:18 开始提及。

一、基本概念
-
Horovod
Horovod 是Uber开源的又一个深度学习工具,它的发展吸取了Facebook "Training ImageNet In 1 Hour" 与百度 "Ring Allreduce" 的优点,可为用户实现分布式训练提供帮助。

-
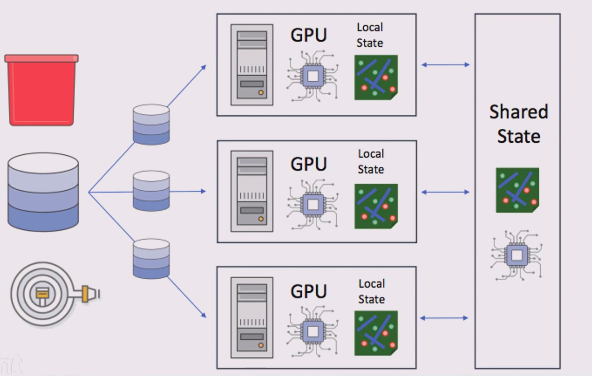
Parameter Server - Built-In Algorithms
-
Parameter Server - TensorFlow Script Mode
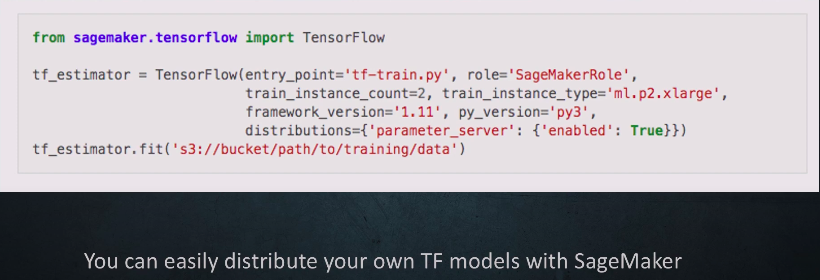
entry_point 怎么写?
Your python script should implement a few methods like train, model_fn, transform_fn, input_fn etc. SagaMaker would call appropriate method when needed.
https://docs.aws.amazon.com/sagemaker/latest/dg/mxnet-training-inference-code-template.html
分配了两个 gpu 的 instance。
| Instance Name | GPU Count | vCPU Count | Memory | Parallel Processing Cores | GPU Memory | Network Performance |
| p2.xlarge | 1 | 4 | 61 GiB | 2,496 | 12 GiB | High |
-
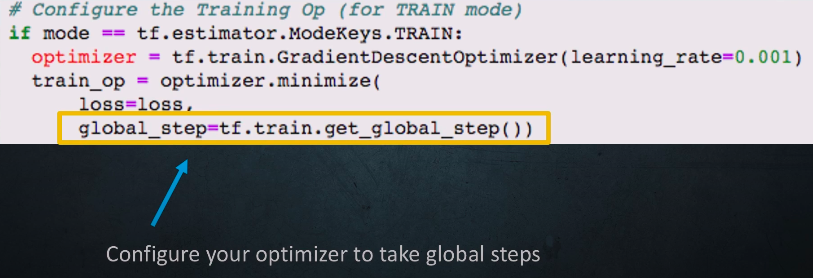
Distributed TensorFlow - Global Optimizers
-
增量训练 - Incremental Retraining
说到增量训练,其实和在线学习是一个意思,在线学习的典型代表是用SGD优化的logistics regress,先用数据初始化参数,线上来一个数据更新一次参数,虽然时间的推移,效果越来越好。这样就避免了离线更新模型的问题。
sklearn提供很多增量学习算法:


Classification sklearn.naive_bayes.MultinomialNB sklearn.naive_bayes.BernoulliNB sklearn.linear_model.Perceptron sklearn.linear_model.SGDClassifier sklearn.linear_model.PassiveAggressiveClassifier Regression sklearn.linear_model.SGDRegressor sklearn.linear_model.PassiveAggressiveRegressor Clustering sklearn.cluster.MiniBatchKMeans Decomposition / feature Extraction sklearn.decomposition.MiniBatchDictionaryLearning sklearn.decomposition.IncrementalPCA sklearn.decomposition.LatentDirichletAllocation sklearn.cluster.MiniBatchKMeans
def train(num_cpus, num_gpus, training_idr, model_dir, pretrained_model_dir, batch_size, epochs, learning_rate, weight_decay, momentum, log_interval): dataset_name = "101_ObjectCategories" # Location of the pre-traind model on local disk onnx_path = os.path.join(pretrained_model_dir, 'model.onnx') ... # Local the ONNX Model sym, arg_params, aux_params = onnx_mxnet.import_model(onnx_path) new_sym, new_arg_params, new_aux_params = get_layer_output(sym, arg_params, aux_params, 'flatten0')
二、代码演练
Developer Guide: Use TensorFlow with Amazon SageMaker
Ref: Amazon SageMaker Examples【Github 官方的 example code】
[Comment 阅读笔记]
-
TensorFlow Serving container
In addition, this notebook demonstrates how to perform real time inference with the SageMaker TensorFlow Serving container.
The TensorFlow Serving container is the default inference method for script mode.
For full documentation on the TensorFlow Serving container, please visit here.
This tutorial's training script was adapted from TensorFlow's official CNN MNIST example. We have modified it to handle the model_dir parameter passed in by SageMaker. This is an S3 path which can be used for data sharing during distributed training and checkpointing and/or model persistence. We have also added an argument-parsing function to handle processing training-related variables.
At the end of the training job we have added a step to export the trained model to the path stored in the environment variable SM_MODEL_DIR, which always points to /opt/ml/model. This is critical because SageMaker uploads all the model artifacts in this folder to S3 at end of training.
xgb_model.fit(inputs=data_channels, logs=True)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号