[CUDA] MobileNet Classification, faster and faster
深度加速
一、模型实测
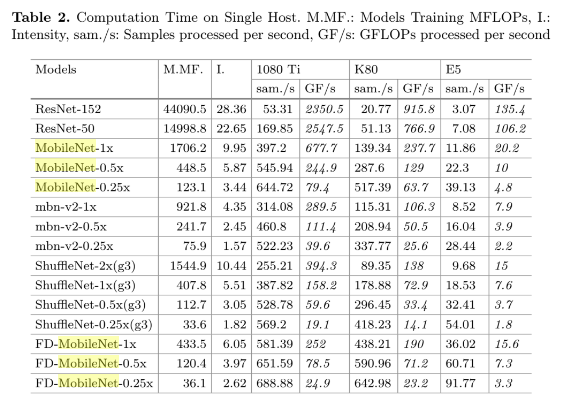
如何将MobileNet的性能发挥到极致?这是个工程问题。
-
GPU版本 depth 1.0
================================================================================ reload the pre-trained model: ./OUTPUT/my_model_2020-04-28_10-57-47.h5 Found 833 images belonging to 2 classes. Found 92 images belonging to 2 classes. ./DATA/negative_isSingleColor ave_duration per inference: 0.023604098076745027 sec ================================================================================ {'positive_isSingleColor': 290, 'negative_isSingleColor': 153} ./DATA/positive_isSingleColor ave_duration per inference: 0.022682341302578873 sec ================================================================================ {'positive_isSingleColor': 399, 'negative_isSingleColor': 83}
-
GPU版本 depth 0.25
================================================================================ reload the pre-trained model: ./OUTPUT/my_model.h5 Found 833 images belonging to 2 classes. Found 92 images belonging to 2 classes. ./INPUT/negative_isSingleColor ave_duration per inference: 0.009260934846934023 sec ================================================================================ {'positive_isSingleColor': 421, 'negative_isSingleColor': 22} ./INPUT/positive_isSingleColor ave_duration per inference: 0.00779257424144824 sec ================================================================================ {'positive_isSingleColor': 482}
二、CPU 加速
-
TF CPU加速
TensorFlow binaries supporting AVX, FMA, SSE

偶尔会遇到的问题:
2020-05-17 13:42:36.193954: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA
ubuntu16.04解决tensorflow提示未编译使用SSE3、SSE4.1、SSE4.2、AVX、AVX2、FMA的问题
TensorFlow在安装的时候采用的pip install指令,这种安装方式会存在这种问题。主要有两种解决方法,一种是修改警告信息的显示级别,使这种信息不再出现,另外一种就是自己重新编译安装tensorflow,在编译的时候使用这些指令集。这里我尝试第二种解决方法。并且由于我的机器上没有高效的GPU,所以我尝试安装的是CPU版本。
如此编译后,确实会快一些。
相关参考链接:How to compile Tensorflow with SSE4.2 and AVX instructions?
bazel build -c opt --copt=-msse3 --copt=-msse4.1 --copt=-msse4.2 --copt=-mavx --copt=-mavx2 --copt=-mfma //tensorflow/tools/pip_package:build_pip_package
三、OpenCV 加速
-
OpenCV CPU加速
性能优化,自然地,OpenCV也有类似的功能:CPU optimizations build options
OpenCV中的几百个基本内核已经使用“广泛通用内在函数(intrinsics)”进行了重写。这些内在函数映射到SSE2,SSE4,AVX2,NEON或VSX内在函数,具体取决于目标平台和编译标志。它应该转化为明显更好的性能,即使对于一些已经优化的功能也是如此。例如,如果使用CPU_BASELINE = AVX2 CMake标志配置和编译OpenCV,则可以为某些图像处理操作提供额外15-30%的速度提升。通过OpenCV 4.0 gold,我们计划将更多内核转换为此类内在函数,并采用我们的动态调度机制,因此在x64平台上,AVX2优化内核始终内置,如果实际硬件支持此类指令,则可以在运行中进行选择(无需更改CPU_BASELINE)。
随着IPPICV组件升级,增加了对IPP 2019的支持
-
OpenCV 4.0 GAPI
这部分的优化应该算是相互借鉴学习吧,OpenCV 也像 tensorflow 一样提供 lazy 的 API 了。我们可以把操作添加到计算图中,构建完整的计算图之后再同意执行(原来是立刻执行)。这样做的好处和 tensorflow 中的静态图也是一样的:图只需要编译一次就可以做重用或者并行优化。比如,原来我们这么写:
#include <opencv2/core.hpp> #include <opencv2/imgproc.hpp> #include <opencv2/highgui.hpp> int main(int argc, char *argv[]) { using namespace cv; if (argc != 3) return 1; Mat in_mat = imread(argv[1]); Mat gx, gy; Sobel(in_mat, gx, CV_32F, 1, 0); Sobel(in_mat, gy, CV_32F, 0, 1); Mat mag, out_mat; sqrt(gx.mul(gx) + gy.mul(gy), mag); mag.convertTo(out_mat, CV_8U); imwrite(argv[2], out_mat); return 0; }
现在,我们可以把原来的 Sobel 操作变成 lazy 的 Sobel 操作,也就是 gapi::Sobel。在调用 gapi::Sobel 的时候,Sobel 不会立刻执行,直到 GComputation 才会整张计算图一起执行。
#include <opencv2/gapi.hpp> #include <opencv2/gapi/core.hpp> #include <opencv2/gapi/imgproc.hpp> #include <opencv2/highgui.hpp> int main(int argc, char *argv[]) { using namespace cv; if (argc != 3) return 1; GMat in; GMat gx = gapi::Sobel(in, CV_32F, 1, 0); GMat gy = gapi::Sobel(in, CV_32F, 0, 1); GMat mag = gapi::sqrt(gapi::mul(gx, gx) + gapi::mul(gy, gy)); GMat out = gapi::convertTo(mag, CV_8U); GComputation sobel(in, out); Mat in_mat = imread(argv[1]), out_mat; sobel.apply(in_mat, out_mat); imwrite(argv[2], out_mat); return 0; }
四、AI and Efficiency
Ref: https://openai.com/blog/ai-and-efficiency/

-
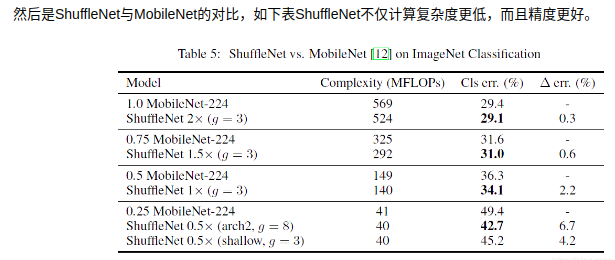
ShuffleNet_v1
-
EfficientNet
官方指标:https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
代码实现:Implementation of EfficientNet model. Keras and TensorFlow Keras. https://arxiv.org/abs/1905.11946
已验证代码:https://github.com/qubvel/efficientnet
CPU 情况下:28-30 fps
Predict duration is 0.034783363342285156 Predict duration is 0.03601837158203125 Predict duration is 0.035718441009521484 Predict duration is 0.0376276969909668
时间出真知
-
TensorFlow 源码自定义编译
/* implement */

 浙公网安备 33010602011771号
浙公网安备 33010602011771号