[ML] LIBSVM Data: Classification, Regression, and Multi-label
数据库下载:LIBSVM Data: Classification, Regression, and Multi-label
一、机器学习模型的参数
模型所需的参数格式,有些为:LabeledPoint。
# $example on$ def parse(lp): label = float(lp[lp.find('(') + 1: lp.find(',')]) vec = Vectors.dense(lp[lp.find('[') + 1: lp.find(']')].split(',')) return LabeledPoint(label, vec) trainingData = ssc.textFileStream(sys.argv[1]).map(parse).cache() testData = ssc.textFileStream(sys.argv[2]).map(parse)
官方示例:https://spark.apache.org/docs/2.4.4/mllib-data-types.html#data-types-rdd-based-api
(a) 手动设置
from pyspark.mllib.linalg import SparseVector from pyspark.mllib.regression import LabeledPoint # Create a labeled point with a positive label and a dense feature vector. pos = LabeledPoint(1.0, [1.0, 0.0, 3.0]) # Create a labeled point with a negative label and a sparse feature vector. neg = LabeledPoint(0.0, SparseVector(3, [0, 2], [1.0, 3.0]))
(b) 读取设置
from pyspark.mllib.util import MLUtils examples = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
二、二分类训练
单机sklearn
采用传统单机sklearn, 设置iteration=10000的话,需要跑的时间太长了不想等,只能被迫人工中断了。
from joblib import Memory from sklearn.datasets import load_svmlight_file import time mem = Memory("./mycache") @mem.cache def get_data(): data = load_svmlight_file("/home/hadoop/covtype.libsvm.binary") return data[0], data[1] X, y = get_data() # Build the model time_start=time.time() from sklearn.linear_model import LogisticRegression clf = LogisticRegression(random_state=0, solver='lbfgs', max_iter=200).fit(X, y) time_end=time.time() print('totally cost {} sec'.format(time_end-time_start)) print(clf.score(X, y))
集群Spark.ml
节省训练时间:1-192/325 = 1-59% = 41%
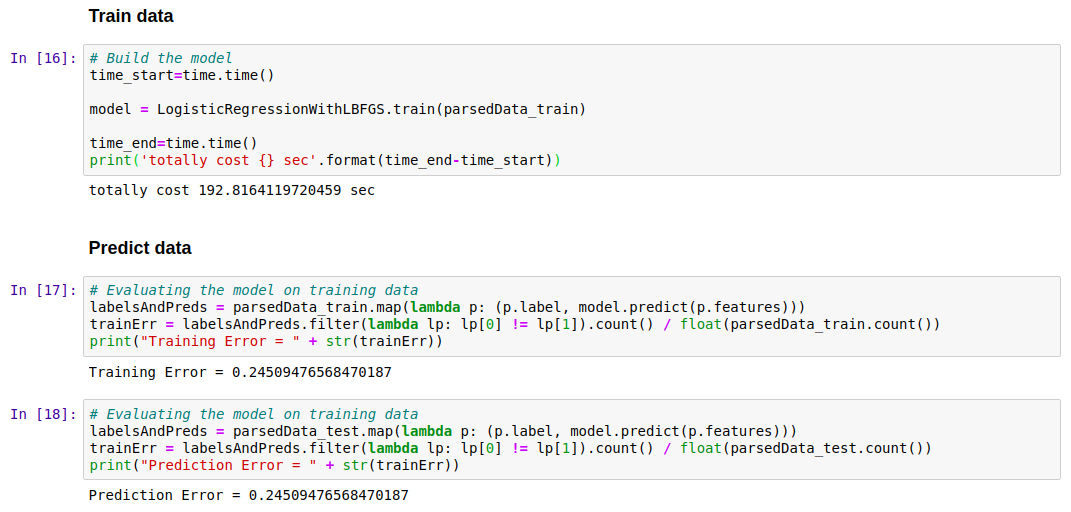
Figure 01, cluster 三节点的训练耗时
Init¶
In [1]:
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
from pyspark.streaming import StreamingContext
import datetime
import time
In [2]:
def fnGetAppName():
currentSecond=datetime.datetime.now().second
currentMinute=datetime.datetime.now().minute
currentHour=datetime.datetime.now().hour
currentDay=datetime.datetime.now().day
currentMonth=datetime.datetime.now().month
currentYear=datetime.datetime.now().year
return "{}-{}-{}_{}-{}-{}".format(currentYear, currentMonth, currentDay, currentHour, currentMinute, currentSecond)
In [3]:
def fn_timer(a_func):
def wrapTheFunction():
time_start=time.time()
a_func()
time_end=time.time()
print('totally cost {} sec'.format(time_end-time_start))
return wrapTheFunction
In [4]:
appName = fnGetAppName()
print("appName: {}".format(appName))
# conf = SparkConf().setMaster("spark://node-master:7077").setAppName(appName)
conf = SparkConf().setMaster("local").setAppName(appName)
Spark Context¶
In [5]:
sc = SparkContext(conf = conf)
Spark Session¶
In [6]:
spark = SparkSession.builder.config(conf=SparkConf()).getOrCreate()
Spark Stream¶
In [7]:
ssc = StreamingContext(sc, 1)
Let's Go!¶
Load data¶
In [8]:
from __future__ import print_function
import sys
from pyspark.mllib.linalg import Vectors
from pyspark.mllib.regression import LabeledPoint
from pyspark.mllib.classification import LogisticRegressionWithLBFGS, LogisticRegressionModel
from pyspark.mllib.util import MLUtils
##################################################
# Load and parse the data
##################################################
def parsePoint(line):
values = [float(x) for x in line.split(' ')]
return LabeledPoint(values[0], values[1:])
##################################################
# Change the label to [0,1]
##################################################
def sparsePoint(lp):
new_label = 0;
if lp.label == 1.0:
new_label=1.0
else:
new_label=0.0
return LabeledPoint(new_label, features=lp.features)
Load train data.¶
In [9]:
# (1) small dense data
# data_train = sc.textFile("/test/sample_svm_data.txt")
# parsedData_train = data_train.map(parsePoint)
# (2) large sparse data
# data_train = MLUtils.loadLibSVMFile(sc, "/dataset/a9a.txt")
data_train = MLUtils.loadLibSVMFile(sc, "/dataset/covtype.libsvm.binary")
data_train.take(10)
Out[9]:
In [10]:
parsedData_train = data_train.map(sparsePoint)
print(parsedData_train.count())
parsedData_train.take(10)
Out[10]:
Load test data.¶
In [11]:
# (1) small dense data
# data = sc.textFile("/test/sample_svm_data.txt")
# parsedData_test = data.map(parsePoint)
# (2) large sparse data
# data_test = MLUtils.loadLibSVMFile(sc, "/dataset/a9a.t")
data_test = MLUtils.loadLibSVMFile(sc, "/dataset/covtype.libsvm.binary")
data_test.take(10)
Out[11]:
In [12]:
parsedData_test = data_test.map(sparsePoint)
print(parsedData_test.count())
parsedData_test.take(10)
Out[12]:
Train data¶
In [16]:
# Build the model
time_start=time.time()
model = LogisticRegressionWithLBFGS.train(parsedData_train)
time_end=time.time()
print('totally cost {} sec'.format(time_end-time_start))
Predict data¶
In [17]:
# Evaluating the model on training data
labelsAndPreds = parsedData_train.map(lambda p: (p.label, model.predict(p.features)))
trainErr = labelsAndPreds.filter(lambda lp: lp[0] != lp[1]).count() / float(parsedData_train.count())
print("Training Error = " + str(trainErr))
In [18]:
# Evaluating the model on training data
labelsAndPreds = parsedData_test.map(lambda p: (p.label, model.predict(p.features)))
trainErr = labelsAndPreds.filter(lambda lp: lp[0] != lp[1]).count() / float(parsedData_test.count())
print("Prediction Error = " + str(trainErr))
End.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号