[Hadoop] Yarn & k8s
写在前面
一、大数据全栈
头两节讲完HDFS & MapReduce,这一部分聊一聊它们之间的“人物关系”。
其中也讨论下k8s的学习必要性。
Ref: [Distributed ML] Yi WANG's talk

二、知识点
容器技术与Kubernetes
Goto: 3 万容器,知乎基于Kubernetes容器平台实践
Goto: 如何学习、了解kubernetes?
Goto: 选K8S是对的,但是用不好就是你的不对了
Yarn资源管理
一、重要概念
- ResouceManager
- ApplicationMaster
- NodeManager
- Container
- JobHistoryServer
- Timeline Server
JobHistoryServer
所有node启动如下命令,能记录mapreduce应用程序的记录。(对作业信息进行记录)
mr-jobhistory-daemon.sh start historyserver
Timeline Server
写与第三方结合的日志服务数据(比如spark等),是更细粒度的信息记录。。
任务在哪个队列中运行;
运行任务时设置的用户是哪个用户;
二、启动流程
Ref: 实战案例玩转Hadoop系列11--运行Map Reduce程序
在真实的生产环境中,MAP REDUCE程序应该提交到Yarn集群上分布式运行,这样才能发挥出MAP REDUCE分布式并行计算的效果。
MAP REDUCE程序提交给Yarn执行的过程如下:
1、客户端代码中设置好MAP REDUCE程序运行时所要使用的Mapper类、Reducer类、程序Jar包所在路径、Job名称、Job输入数据的切片信息、Configuration所配置的参数等资源,统一提交给Yarn所指定的位于HDFS上的Job资源提交路径;
2、客户端向Yarn中的Resource Manager请求运行Jar包中MRAppMaster进程的资源容器Container;
分配application id、输出是否存在、输入 --> split(一个分片对应一个map task)
3、Yarn将提供Container的任务指派给某个拥有空闲资源的 Node Manager节点,Node Manager接受任务后创建资源容器(即所谓的Container);
容器所需分配的“资源描述信息” ---> 某个空闲的Node Manager节点 ---> 启动一个contrainer
4、客户端向创建好容器的Node Manager发送启动MRAppMaster进程的shell脚本命令,启动MRAppMaster;
5、MRAppMaster启动后,读取 job相关配置及程序资源,向Resource Manager请求N个资源容器来启动若干个Map Task进程和若干个Reduce Task进程,并监控这些Map Task进程和Reduce Task进程的运行状态;
6、当整个Job的所有Map Task进程和Reduce Task进程任务处理完成后,整个Job的所有进程全部注销,Yarn则销毁Container,回收运算资源。

三、Yarn调度器
FIFO Scheduler
Capacity Scheduler
Fair Scheduler
新建一个capacity-scheduler.xml,也要同步拷贝到其他node中。
<configuration> <property> <name>yarn.scheduler.capacity.root.queues</name> <value>prod,dev</value> </property> <property> <name>yarn.scheduler.capacity.root.dev.queues</name> <value>hdp,spark</value> </property> <property> <name>yarn.scheduler.capacity.root.prod.capacity</name> <value>40</value> </property> <property> <name>yarn.scheduler.capacity.root.dev.capacity</name> <value>60</value> </property> <property> <name>yarn.scheduler.capacity.root.dev.maximum-capacity</name> <value>75</value> </property> <property> <name>yarn.scheduler.capacity.root.dev.hdp.capacity</name> <value>50</value> </property> <property> <name>yarn.scheduler.capacity.root.dev.spark.capacity</name> <value>50</value> </property> </configuration>
MR程序中添加代码:
Configuration configuration = new Configuration(); configuration.set("mapreduce.job.queuename", "hdp")
Job job = Job.getInstance(configuration, WordCountMain.class.getSimpleName());
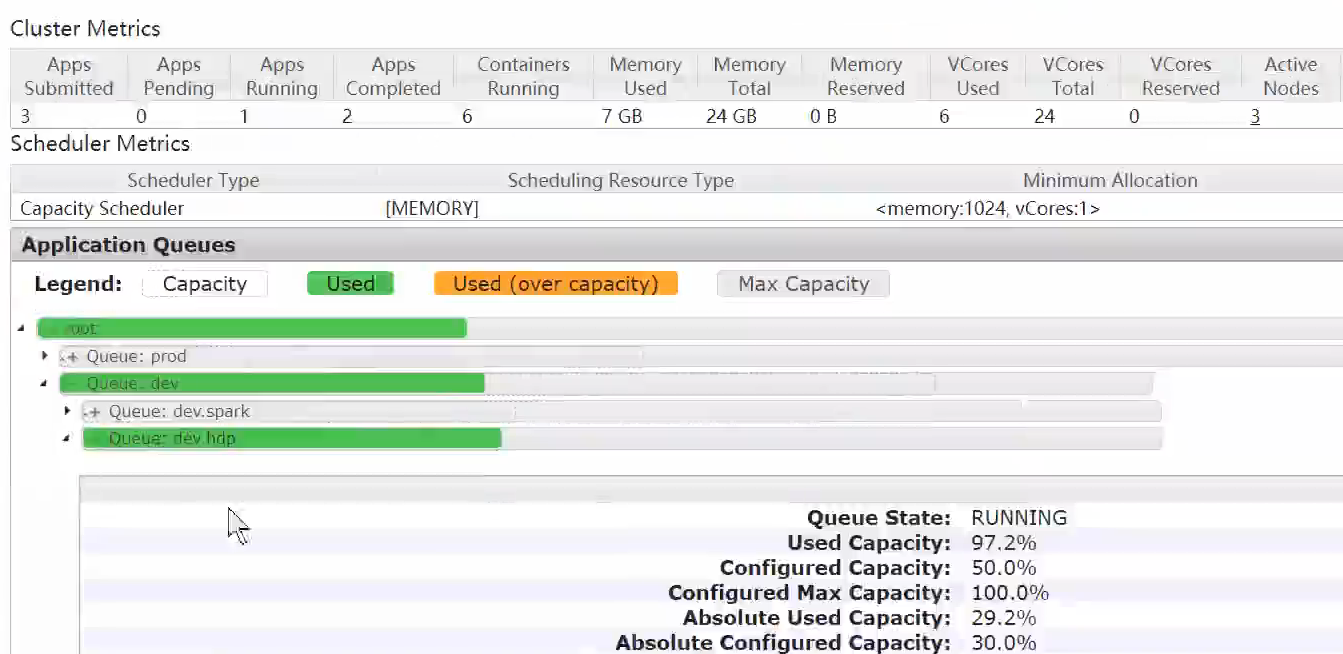
Cluster UI在运行的MR查看:
Kubernetes
Ref:Big Data: Google Replaces YARN with Kubernetes to Schedule Apache Spark
Ref: Running Spark on Kubernetes
The Kubernetes scheduler is currently experimental. In future versions, there may be behavioral changes around configuration, container images and entrypoints. - 2019/10/28
既然这样,暂时不提。
End.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号