[Sklearn] Linear regression models to fit noisy data
Ref: [Link] sklearn各种回归和预测【各线性模型对噪声的反应】
Ref: Linear Regression 实战【循序渐进思考过程】
Ref: simple linear regression详解【涉及到假设检验】
引申问题,如何拟合sin数据呢?
如果不引入sin这样周期函数,可以使用:scikit learn 高斯过程回归【有官方例子】
参考:[Bayesian] “我是bayesian我怕谁”系列 - Gaussian Process
牛津讲义:An Introduction to Fitting Gaussian Processes to Data
博客:Fitting Gaussian Process Models in Python
####3.1 决策树回归#### from sklearn import tree model_DecisionTreeRegressor = tree.DecisionTreeRegressor()
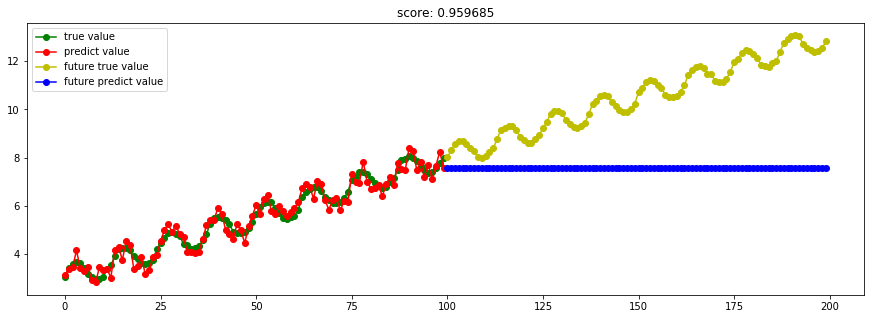
Ref: [ML] Decision Tree & Ensembling Metholds
参见链接中:构造决策树算法的理解。
####3.2 线性回归#### from sklearn import linear_model model_LinearRegression = linear_model.LinearRegression()

Ref: ML Glossary - Linear Regression【帮助理解原理】
Ref: [Scikit-learn] 1.1 Generalized Linear Models - from Linear Regression to L1&L2【有示例代码,模型参数理解】
####3.3 SVM回归#### from sklearn import svm model_SVR = svm.SVR()
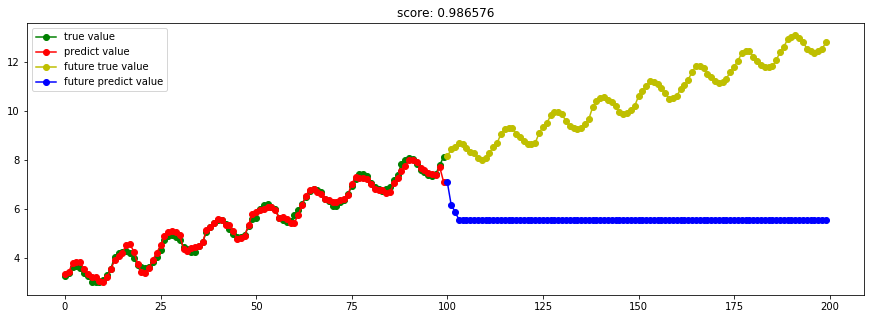
[Scikit-learn] 1.4 Support Vector Regression【依据最外边距】
SVM回归结果出现问题,这是为什么?调参后可以么?是否取决于”核“的选取?
kernel='rbf' 出现上述状况;kernel='linear",则恢复正常。
Ref: Parameter Selection for Linear Support Vector Regression【一篇paper】
####3.4 KNN回归#### from sklearn import neighbors model_KNeighborsRegressor = neighbors.KNeighborsRegressor()

聚类回归也能做线性拟合?
Ref: Nearest Neighbors regression
Ref: https://coding.m.imooc.com/questiondetail.html?qid=84216
貌似是利用”最近的五个点“,自然就不合适了。
####3.5 随机森林回归#### from sklearn import ensemble model_RandomForestRegressor = ensemble.RandomForestRegressor(n_estimators=20) #这里使用20个决策树
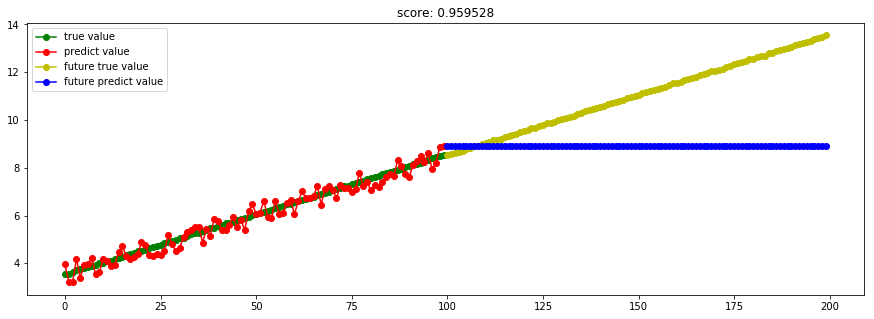
一棵树不行,多棵树自然也不行。
不得不说的是:随机森林是集成学习中可以和梯度提升树GBDT分庭抗礼的算法,尤其是它可以很方便的并行训练,在如今大数据大样本的的时代很有诱惑力。
####3.6 Adaboost回归#### from sklearn import ensemble model_AdaBoostRegressor = ensemble.AdaBoostRegressor(n_estimators=50) #这里使用50个决策树
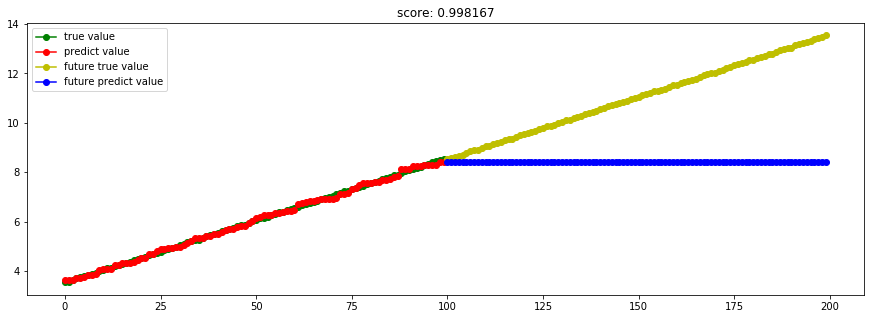
这里取消了sin的噪声,但还是"树"本身的问题。
Ref: https://blog.csdn.net/sunflower_sara/article/details/81214290【bagging, boosting的区别】
并行计算:
Bagging:各个预测函数可以并行生成。
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
偏差和方差:
bagging是减少variance,而boosting是减少bias。
bias度量模型预测结果和真实结果的偏离程度,刻画模型算法本身的拟合能力。
variance度量同样大小的训练集的变动导致的学习能力的变化,刻画数据的分布情况造成的影响。
####3.7 GBRT回归#### from sklearn import ensemble model_GradientBoostingRegressor = ensemble.GradientBoostingRegressor(n_estimators=100) #这里使用100个决策树
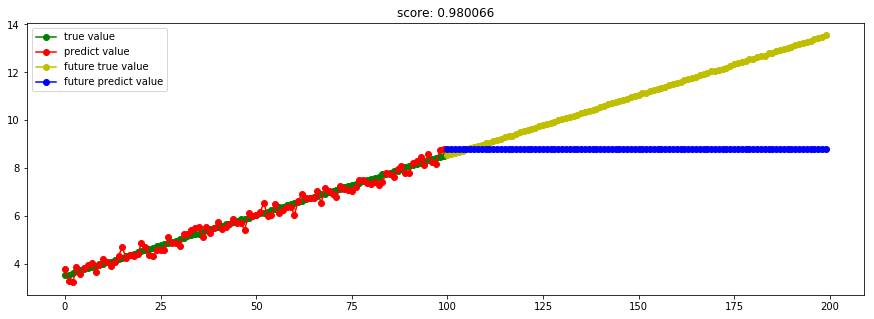
在Boosting算法中,
当采取平方误差损失函数时,损失函数刚好表达的是当前模型的拟合残差,最优化比较方便;当采取指数损失函数时,也很方便;
但对于一般函数时,最优化十分困难。因此,利用最速下降的近似法,即利用损失函数的负梯度在当前模型的值,作为回归问题中Boosting算法的残差的近似值。
在回归问题中,
-
- 这称为梯度提升回归树(GBRT);
- 分类问题则称为梯度提升决策树(GBDT);
[Boosting ----> GBDT ----> XGBoost]
GBDT的性能相对于Boosting有一定的提升,它和AdaBoost都是Boosting族方法的一种。
XGBoost的性能在GBDT上又有一步提升。
对XGBoost最大的认知在于其能够自动地运用CPU的多线程进行并行计算,同时在算法精度上也进行了精度的提高。 由于GBDT在合理的参数设置下,往往要生成一定数量的树才能达到令人满意的准确率,在数据集较复杂时,模型可能需要几千次迭代运算,但是XGBoost利用并行的CPU更好的解决了这个问题。
传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。
####3.8 Bagging回归#### from sklearn.ensemble import BaggingRegressor model_BaggingRegressor = BaggingRegressor()
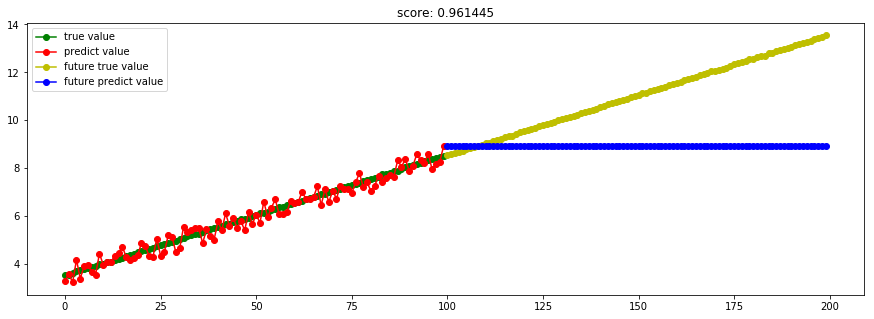
Ref: Bagging与随机森林算法原理小结【博客不错】
对于这部分大约36.8%的没有被采样到的数据(因为是无放回采样),我们常常称之为袋外数据(Out Of Bag, 简称OOB)。这些数据没有参与训练集模型的拟合,因此可以用来检测模型的泛化能力。
bagging对于弱学习器没有限制,这和Adaboost一样。但是最常用的一般也是决策树和神经网络。
"随机森林” 是 Bagging算法 的进化版,也就是说,它的思想仍然是bagging,但是进行了独有的改进。
-
- bagging只是针对“样本的采样过程”,对“特征”没有处理;
- 随机森林对“特征”也进行了筛选。
####3.9 ExtraTree极端随机树回归#### from sklearn.tree import ExtraTreeRegressor model_ExtraTreeRegressor = ExtraTreeRegressor()
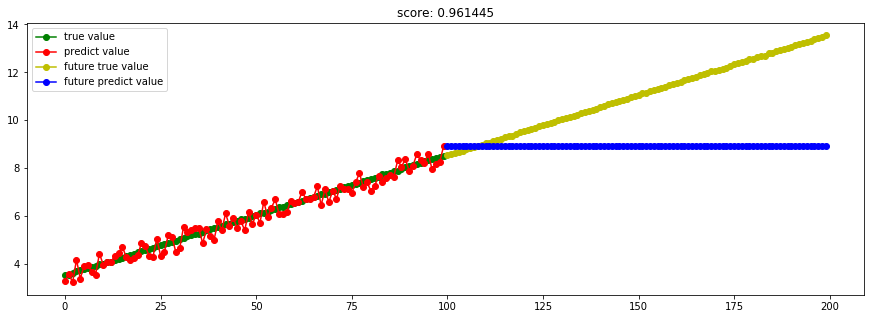
Ref: 极端随机树(ET)--Bagging
极端随机树与随机森林有两点主要区别:
(1)ET中每棵树采用所有训练样本,即每棵树的样本集相同。
(2)RF在特征子集中选择最优分叉特征,而ET直接随机选择分叉特征。
优缺点:基本与随即森林类似。由于ET采用所有训练样本使得计算量相对RF增大,而采用随机特征,减少了信息增益(比)或基尼指数的计算过程,计算量又相对RF减少。
####3.10 ARD贝叶斯ARD回归 model_ARDRegression = linear_model.ARDRegression()
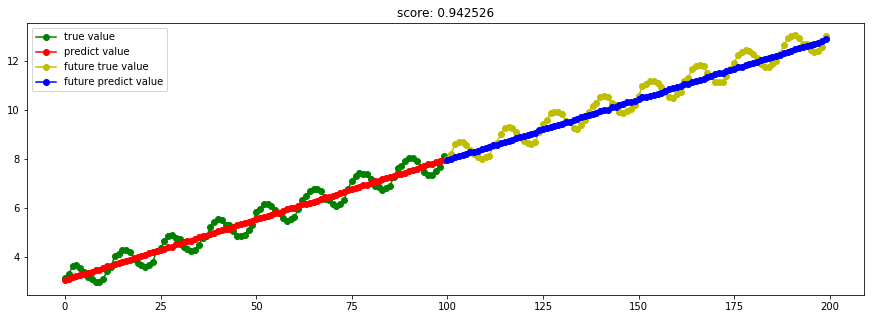
Ref: [ML] Bayesian Linear Regression【ARD详见链接】
####3.11 BayesianRidge贝叶斯岭回归 model_BayesianRidge = linear_model.BayesianRidge()
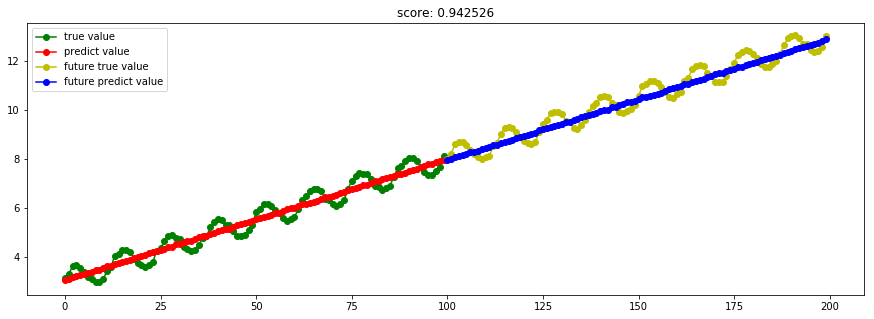
Ref: [ML] Bayesian Linear Regression
####3.12 TheilSen泰尔森估算 model_TheilSenRegressor = linear_model.TheilSenRegressor()
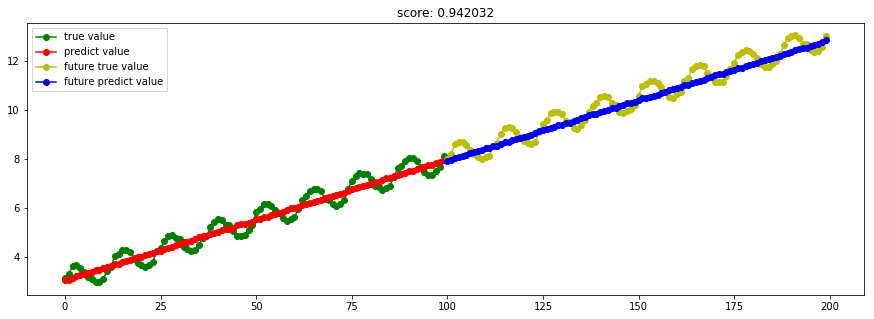
Ref: 稳健回归(Robustness regression)
Theil-Sen回归是一个参数中值估计器,它适用泛化中值,对多维数据进行估计,因此其对多维的异常点(outliers 外点)有很强的稳健性。
在单变量回归问题中,Theil-Sen方法的Breakdown point为29.3%,也就是说,Theil-Sen方法可以容忍29.3%的数据是outliers。
####3.13 RANSAC随机抽样一致性算法 model_RANSACRegressor = linear_model.RANSACRegressor()
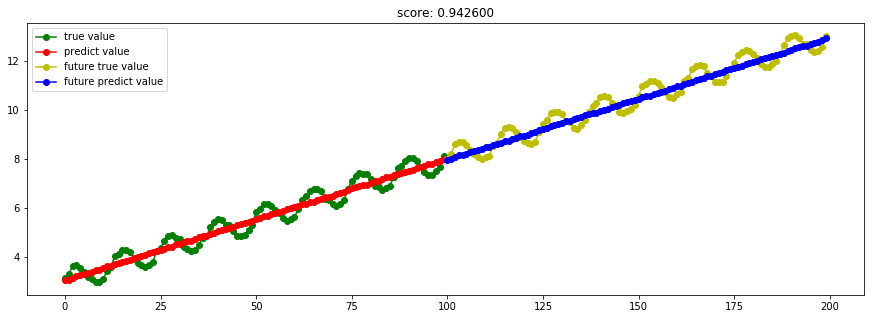
Ref: 稳健回归(Robustness regression)
RANSAC算法在线性和非线性回归中都得到了广泛的应用,而其最典型也是最成功的应用,莫过于在图像处理中处理图像拼接问题,这部分在Opencv中有相关的实现。
RANSAC算法将输入样本分成了两个大的子集:内点(inliers)和外点(outliers)。其中内点的数据分布会受到噪声的影响;而外点主要来自于错误的测量手段或者是对数据错误的假设。而RANSAC算法最终的结果是基于算法所确定的内点集合得到的。
from sklearn.gaussian_process import GaussianProcessRegressor from sklearn.gaussian_process.kernels import RBF, ConstantKernel as C # Instantiate a Gaussian Process model kernel = C(1.0, (1e-3, 1e3)) * RBF(10, (1e-2, 1e2)) gp = GaussianProcessRegressor(kernel=kernel, n_restarts_optimizer=9) try_different_method(gp)
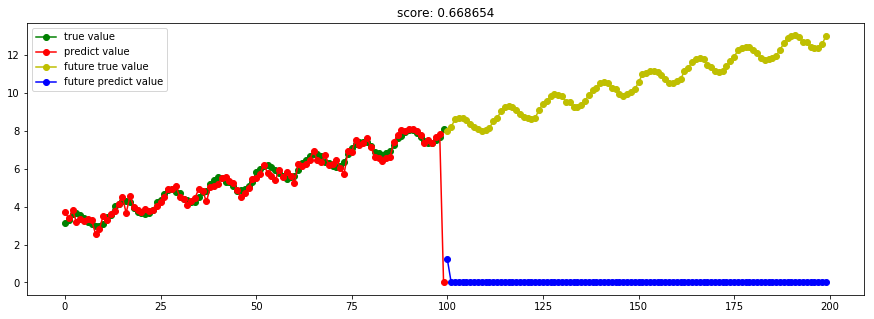
高斯回归看样子也不错,在predict(红色)表现良好。
End.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号