[Spark] 06 - Structured Streaming
基本了解
响应更快,对过去的架构进行了全新的设计和处理。
核心思想:将实时数据流视为一张正在不断添加数据的表,参见Spark SQL's DataFrame。
一、微批处理(默认)
写日志操作 保证一致性。
因为要写入日志操作,每次进行微批处理之前,都要先把当前批处理的数据的偏移量要先写到日志里面去。
如此,就带来了微小的延迟。
数据到达 和 得到处理 并输出结果 之间的延时超过100毫秒。
二、持续批处理
例如:"欺诈检测",在100ms之内判断盗刷行为,并给予制止。
因为 “异步” 写入日志,所以导致:至少处理一次,不能保证“仅被处理一次”。
Spark SQL 只能处理静态处理。
Structured Streaming 可以处理数据流。
三、与spark streaming的区别
过去的方式,如下。Structured Streaming则采用统一的 spark.readStream.format()。
lines = ssc.textFileStream('file:///usr/local/spark/mycode/streaming/logfile') # <---- 这是文件夹!
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
inputStream = ssc.queueStream(rddQueue)
Structured Streaming 编程
一、基本步骤
二、demo 示范
代码展示
统计每个单词出现的频率。
from pyspark.sql import SparkSession from pyspark.sql.functions import split from pyspark.sql.functions import explode if __name__ == "__main__":
spark = SparkSession.builder.appName("StructuredNetworkWordCount").getOrCreate() spark.sparkContext.setLogLevel('WARN')
# 创建一个输入数据源,类似"套接子流",只是“类似”。 lines = spark.readStream.format("socket").option("host”, “localhost").option("port", 9999).load()
# Explode得到一个DataFrame,一个单词变为一行; # 再给DataFrame这列的title设置为 "word"; # 根据word这一列进行分组词频统计,得到“每个单词到底出现了几次。
words = lines.select( explode( split( lines.value, " " ) ).alias("word") )
wordCounts = words.groupBy("word").count() # <--- 得到结果
# 启动流计算并输出结果 query = wordCounts.writeStream.outputMode("complete").format("console").trigger(processingTime="8 seconds").start() query.awaitTermination()
程序要依赖于Hadoop HDFS。
$ cd /usr/local/hadoop
$ sbin/start-dfs.sh
新建”数据源“终端
$ nc -lk 9999
新建”流计算“终端
$ /usr/local/spark/bin/spark-submit StructuredNetworkWordCount.py
输入源
一、File 输入源
(1) 创建程序生成JSON格式的File源测试数据
例如,对Json格式文件进行内容统计。目录下面有1000 json files,格式如下:
![]()
(2) 创建程序对数据进行统计
import os import shutil from pprint import pprint from pyspark.sql import SparkSession from pyspark.sql.functions import window, asc from pyspark.sql.types import StructType, StructField from pyspark.sql.types import TimestampType, StringType TEST_DATA_DIR_SPARK = 'file:///tmp/testdata/' if __name__ == "__main__": # 定义模式 schema = StructType([ StructField("eventTime" TimestampType(), True), StructField("action", StringType(), True), StructField("district", StringType(), True) ]) spark = SparkSession.builder.appName("StructuredEMallPurchaseCount").getOrCreate() spark.sparkContext.setLogLevel("WARN") lines = spark.readStream.format("json").schema(schema).option("maxFilesPerTrigger", 100).load(TEST_DATA_DIR_SPARK) # 定义窗口 windowDuration = '1 minutes' windowedCounts = lines.filter("action = 'purchase'") \ .groupBy('district', window('eventTime', windowDuration)) \ .count() \ .sort(asc('window''))
# 启动流计算 query = windowedCounts \ .writeStream \ .outputMode("complete") \ .format("console") \ .option('truncate', 'false') \ .trigger(processingTime = "10 seconds") \ # 每隔10秒,执行一次流计算 .start() query.awaitTermination()
(3) 测试运行程序
a. 启动 HDFS
$ cd /usr/local/hadoop
$ sbin/start-dfs.sh
b. 运行数据统计程序
/usr/local/spark/bin/spark-submit spark_ss_filesource.py
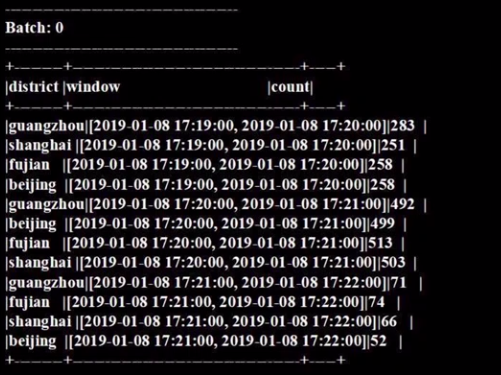
c. 运行结果
二、Socket源和 Rate源
(因为只能r&d,不能生产时间,故,这里暂时略)
一般不用于生产模式,实验测试模式倒是可以。
from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession.builder.appName("TestRateStreamSource").getOrCreate() spark.sparkContext.setLogLevel('WARN')
紧接着是下面的程序:

# 每秒钟发送五行,属于rate源;
# query 代表了流计算启动模式;
运行程序
$ /usr/local/spark/bin/spark-submit spark_ss_rate.py
输出操作
一、启动流计算
writeStream()方法将会返回DataStreamWrite接口。
query = wordCounts.writeStream.outputMode("complete").format("console").trigger(processingTime="8 seconds").start()

输出 outputMode 模式

接收器 format 类型
系统内置的输出接收器包括:File, Kafka, Foreach, Console (debug), Memory (debug), etc。
生成parquet文件
可以考虑读取后转化为DataFrame;或者使用strings查看文件内容。
代码展示:StructuredNetworkWordCountFileSink.py
from pyspark.sql import SparkSession from pyspark.sql.functions import split from pyspark.sql.functions import explode from pyspark.sql.functions import length

只要长度为5的dataframe,也就是单词长度都是5。

"数据源" 终端
# input string to simulate stream.
nc -lk 9999
"流计算" 终端
/usr/local/spark/bin/spark-submit StructuredNetworkWordCountFileSink.py
End.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号