[ML] Decision Tree & Ensembling Metholds
热身:分类问题若干策略
SVM, LR, Decision Tree的比较
同样是分类:SVM、LR、决策树,三者之间有什么优劣势呢?
答:Are decision tree algorithms linear or nonlinear: nonlinear! 更接近 "神经网络"。
一、与"判别式分类"的比较
逻辑回归 LR
LR的优势:
- 对观测样本的概率值输出
- 实现简单高效
- 多重共线性的问题可以通过L2正则化来应对
- 大量的工业界解决方案
- 支持online learning(个人补充)
LR的劣势:
- 特征空间太大时表现不太好
- 对于大量的分类变量无能为力
- 对于非线性特征需要做特征变换
- 依赖所有的样本数据
支持向量机器 SVM
SVM的优点:
- 能够处理大型特征空间
- 能够处理非线性特征之间的相互作用
- 无需依赖整个数据
SVM的缺点:
- 当观测样本很多时,效率并不是很高
- 有时候很难找到一个合适的核函数
决策树
决策树的优点:
- 直观的决策规则
- 可以处理非线性特征
- 考虑了变量之间的相互作用
决策树的缺点:
- 训练集上的效果高度优于测试集,即过拟合[随机森林克服了此缺点]
- 没有将排名分数作为直接结果
二、结论
我总结出了一个工作流程来让大家参考如何决定使用哪个模型:
1. 使用LR试一把总归不会错的,至少是个baseline
2. 看看决策树相关模型例如随机森林,GBDT有没有带来显著的效果提升,即使最终没有用这个模型,也可以用随机森林的结果来去除噪声特征
3. 如果你的特征空间和观测样本都很大,有足够的计算资源和时间,试试SVM吧,
决策树算法
Ref: 算法杂货铺——分类算法之决策树(Decision tree)
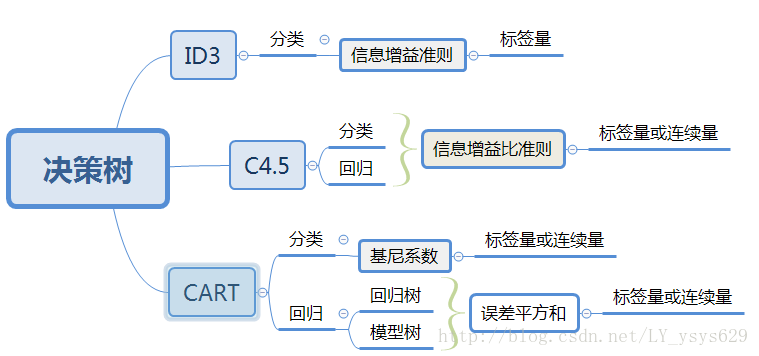
一、构造决策树
属性选择度量算法有很多,一般使用自顶向下递归分治法,并采用不回溯的贪心策略。这里介绍ID3和C4.5两种常用算法。
使用属性选择度量来选择将元组最好地划分成不同的类的属性。所谓决策树的构造就是进行属性选择度量确定各个特征属性之间的拓扑结构。
二、模型参数
官方文档:https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeRegressor.html
也可用于 ”回归问题“:回归树,模型树。
决策“森林”
Ensemble method(集成方法),参考博文:机器学习--集成学习(Ensemble Learning)
主流的两种方式
一、Bootstrap Aggregating (缩写:Bagging)
Bootstrap 样本集,“有放回去” 的方式。 举个栗子:构造 Random Forest(随机森林)
(1) 获得 Bootstrap 做为一个 dataset
(2) 随机选择d个特征
开始训练一颗树。

二、Boosting(弱弱变强)
boost算法是基于PAC学习理论(probably approximately correct)而建立的一套集成学习算法(ensemble learning)。
其根本思想在于通过多个简单的弱分类器,构建出准确率很高的强分类器,PAC学习理论证实了这一方法的可行性。
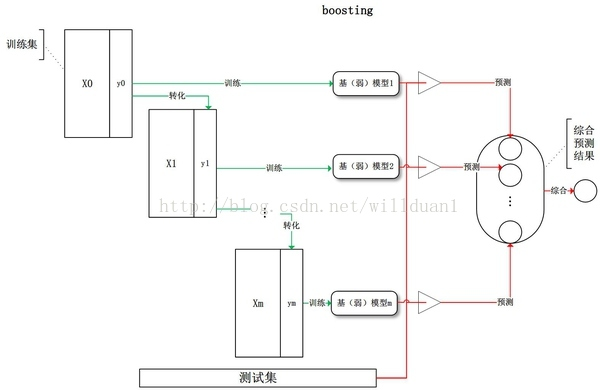
(1)在每一轮如何改变训练数据的权值或概率分布?
通过提高那些在前一轮被弱分类器分错样例的权值,减小前一轮分对样例的权值,来使得分类器对误分的数据有较好的效果。
【划分的不好就多重视一点】
(2)通过什么方式来组合弱分类器?
通过加法模型将弱分类器进行 "线性组合",比如如下三种方式:
* AdaBoost(Adaptive boosting)算法:刚开始训练时对每一个训练例赋相等的权重,然后用该算法对训练集训练t轮,每次训练后,对训练失败的训练例赋以较大的权重,也就是让学习算法在每次学习以后更注意学错的样本,从而得到多个预测函数。
通过拟合残差的方式逐步减小残差,将每一步生成的模型叠加得到最终模型。
# AdaBoost Algorithm from sklearn.ensemble import AdaBoostClassifier clf = AdaBoostClassifier() ... clf.fit(x_train,y_train) clf.predict(x_test)
* GBDT(Gradient Boost Decision Tree),每一次的计算是为了减少上一次的残差,GBDT在残差减少(负梯度)的方向上建立一个新的模型。
# Gradient Boosting from sklearn.ensemble import GradientBoostingClassifier clf = GradientBoostingClassifier() # n_estimators = 100 (default) # loss function = deviance(default) used in Logistic Regression clf.fit(x_train,y_train) clf.predict(x_test)
* XGBoost (Extreme Gradient Boosting),掀起了一场数据科学竞赛的风暴。
# XGBoost from xgboost import XGBClassifier clf = XGBClassifier() # n_estimators = 100 (default) # max_depth = 3 (default) clf.fit(x_train,y_train) clf.predict(x_test)
两者的综合对比
一、Bagging,Boosting 二者之间的区别
1)样本选择上
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
二、决策树与算法框架进行结合
1)Bagging + 决策树 = 随机森林
2)AdaBoost + 决策树 = 提升树 Boosting Tree
3)Gradient Boosting + 决策树 = GBDT
第三种融合策略
一、Stacking(有层次的融合模型)
Ref: 数据挖掘竞赛利器-Stacking和Blending方式
用不同特征训练出来的三个GBDT模型进行融合时,我们会将三个GBDT作为基层模型,在其上在训练一个次学习器(通常为线性模型LR)【有点像mlp】
/* continue ... */

 浙公网安备 33010602011771号
浙公网安备 33010602011771号