机器学习 成绩预测
成绩预测
利用机器学习算法,实现:预测你们班同学的成绩。
要求:
1.任选一门本学期开设的必修课,作为预测对象,必须在本门课程没有考试之前完成论文
2.样本数据的获得与收集,自己提供。
3.使用学过的机器学习算法,
4.编写程序代码
5.训练模型
6.模型测试
# --------------------------转自github--------------------------注:源代码来源于青岛农业大学理信宋彩霞老师,KNN算法;
显示数据集
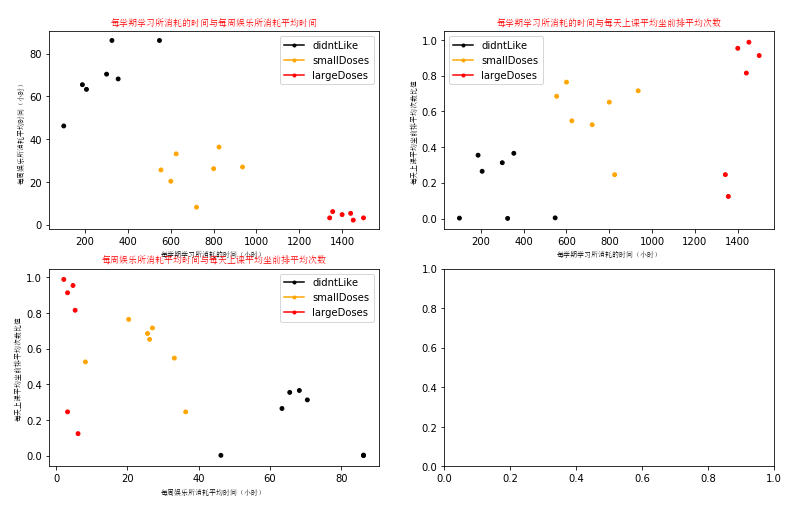
成绩预测
KNN代码
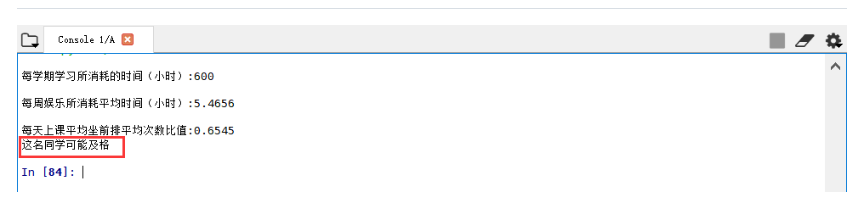
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 | numberOfLabels = len(datingLabels)LabelsColors = []for i in datingLabels: if i == 1: LabelsColors.append('black') if i == 2: LabelsColors.append('orange') if i == 3: LabelsColors.append('red')# 画出散点图,以datingDataMat矩阵的第一(飞行常客例程)、第二列(玩游戏)数据画散点数据,散点大小为15,透明度为0.5axs[0][0].scatter(x=datingDataMat[:, 0], y=datingDataMat[:, 1], color=LabelsColors, s=15, alpha=.99)# 设置标题,x轴label,y轴labelaxs0_title_text = axs[0][0].set_title(u'每学期学习所消耗的时间与每周娱乐所消耗平均时间比值', FontProperties=font)axs0_xlabel_text = axs[0][0].set_xlabel(u'每学期学习所消耗的时间(小时)', FontProperties=font)axs0_ylabel_text = axs[0][0].set_ylabel(u'每周娱乐所消耗平均时间(小时)', FontProperties=font)plt.setp(axs0_title_text, size=9, weight='bold', color='red')plt.setp(axs0_xlabel_text, size=7, weight='bold', color='black')plt.setp(axs0_ylabel_text, size=7, weight='bold', color='black')# 画出散点图,以datingDataMat矩阵的第一(飞行常客例程)、第三列(冰激凌)数据画散点数据,散点大小为15,透明度为0.5axs[0][1].scatter(x=datingDataMat[:, 0], y=datingDataMat[:, 2], color=LabelsColors, s=15, alpha=.99)# 设置标题,x轴label,y轴labelaxs1_title_text = axs[0][1].set_title(u'每学期学习所消耗的时间与每天上课平均坐前排平均次数', FontProperties=font)axs1_xlabel_text = axs[0][1].set_xlabel(u'每学期学习所消耗的时间(小时)', FontProperties=font)axs1_ylabel_text = axs[0][1].set_ylabel(u'每天上课平均坐前排平均次数比值', FontProperties=font)plt.setp(axs1_title_text, size=9, weight='bold', color='red')plt.setp(axs1_xlabel_text, size=7, weight='bold', color='black')plt.setp(axs1_ylabel_text, size=7, weight='bold', color='black')# 画出散点图,以datingDataMat矩阵的第二(玩游戏)、第三列(冰激凌)数据画散点数据,散点大小为15,透明度为0.5axs[1][0].scatter(x=datingDataMat[:, 1], y=datingDataMat[:, 2], color=LabelsColors, s=15, alpha=.99)# 设置标题,x轴label,y轴labelaxs2_title_text = axs[1][0].set_title(u'每周娱乐所消耗平均时间与每天上课平均坐前排平均次数', FontProperties=font)axs2_xlabel_text = axs[1][0].set_xlabel(u'每周娱乐所消耗平均时间(小时)', FontProperties=font)axs2_ylabel_text = axs[1][0].set_ylabel(u'每天上课平均坐前排平均次数比值', FontProperties=font)plt.setp(axs2_title_text, size=9, weight='bold', color='red')plt.setp(axs2_xlabel_text, size=7, weight='bold', color='black')plt.setp(axs2_ylabel_text, size=7, weight='bold', color='black')# 设置图例didntLike = mlines.Line2D([], [], color='black', marker='.', markersize=6, label='didntLike')smallDoses = mlines.Line2D([], [], color='orange', marker='.', markersize=6, label='smallDoses')largeDoses = mlines.Line2D([], [], color='red', marker='.', markersize=6, label='largeDoses')# 添加图例axs[0][0].legend(handles=[didntLike, smallDoses, largeDoses])axs[0][1].legend(handles=[didntLike, smallDoses, largeDoses])axs[1][0].legend(handles=[didntLike, smallDoses, largeDoses])# 显示图片plt.show()numberOfLabels = len(datingLabels)LabelsColors = []for i in datingLabels: if i == 1: LabelsColors.append('black') if i == 2: LabelsColors.append('orange') if i == 3: LabelsColors.append('red')# 画出散点图,以datingDataMat矩阵的第一(飞行常客例程)、第二列(玩游戏)数据画散点数据,散点大小为15,透明度为0.5axs[0][0].scatter(x=datingDataMat[:, 0], y=datingDataMat[:, 1], color=LabelsColors, s=15, alpha=.99)# 设置标题,x轴label,y轴labelaxs0_title_text = axs[0][0].set_title(u'每学期学习所消耗的时间与每周娱乐所消耗平均时间比值', FontProperties=font)axs0_xlabel_text = axs[0][0].set_xlabel(u'每学期学习所消耗的时间(小时)', FontProperties=font)axs0_ylabel_text = axs[0][0].set_ylabel(u'每周娱乐所消耗平均时间(小时)', FontProperties=font)plt.setp(axs0_title_text, size=9, weight='bold', color='red')plt.setp(axs0_xlabel_text, size=7, weight='bold', color='black')plt.setp(axs0_ylabel_text, size=7, weight='bold', color='black')# 画出散点图,以datingDataMat矩阵的第一(飞行常客例程)、第三列(冰激凌)数据画散点数据,散点大小为15,透明度为0.5axs[0][1].scatter(x=datingDataMat[:, 0], y=datingDataMat[:, 2], color=LabelsColors, s=15, alpha=.99)# 设置标题,x轴label,y轴labelaxs1_title_text = axs[0][1].set_title(u'每学期学习所消耗的时间与每天上课平均坐前排平均次数', FontProperties=font)axs1_xlabel_text = axs[0][1].set_xlabel(u'每学期学习所消耗的时间(小时)', FontProperties=font)axs1_ylabel_text = axs[0][1].set_ylabel(u'每天上课平均坐前排平均次数比值', FontProperties=font)plt.setp(axs1_title_text, size=9, weight='bold', color='red')plt.setp(axs1_xlabel_text, size=7, weight='bold', color='black')plt.setp(axs1_ylabel_text, size=7, weight='bold', color='black')# 画出散点图,以datingDataMat矩阵的第二(玩游戏)、第三列(冰激凌)数据画散点数据,散点大小为15,透明度为0.5axs[1][0].scatter(x=datingDataMat[:, 1], y=datingDataMat[:, 2], color=LabelsColors, s=15, alpha=.99)# 设置标题,x轴label,y轴labelaxs2_title_text = axs[1][0].set_title(u'每周娱乐所消耗平均时间与每天上课平均坐前排平均次数', FontProperties=font)axs2_xlabel_text = axs[1][0].set_xlabel(u'每周娱乐所消耗平均时间(小时)', FontProperties=font)axs2_ylabel_text = axs[1][0].set_ylabel(u'每天上课平均坐前排平均次数比值', FontProperties=font)plt.setp(axs2_title_text, size=9, weight='bold', color='red')plt.setp(axs2_xlabel_text, size=7, weight='bold', color='black')plt.setp(axs2_ylabel_text, size=7, weight='bold', color='black')# 设置图例didntLike = mlines.Line2D([], [], color='black', marker='.', markersize=6, label='didntLike')smallDoses = mlines.Line2D([], [], color='orange', marker='.', markersize=6, label='smallDoses')largeDoses = mlines.Line2D([], [], color='red', marker='.', markersize=6, label='largeDoses')# 添加图例axs[0][0].legend(handles=[didntLike, smallDoses, largeDoses])axs[0][1].legend(handles=[didntLike, smallDoses, largeDoses])axs[1][0].legend(handles=[didntLike, smallDoses, largeDoses])# 显示图片plt.show()# 获得normMat的行数m = normMat.shape[0]# 百分之十的测试数据的个数numTestVecs = int(m * hoRatio)# 分类错误计数errorCount = 0.0for i in range(numTestVecs): # 前numTestVecs个数据作为测试集,后m-numTestVecs个数据作为训练集 classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 4) print("分类结果:%d\t真实类别:%d" % (classifierResult, datingLabels[i])) if classifierResult != datingLabels[i]: errorCount += 1.0print("错误率:%f%%" % (errorCount / float(numTestVecs) * 100))# 生成NumPy数组,测试集inArr = np.array([precentTats, ffMiles, iceCream])# 测试集归一化norminArr = (inArr - minVals) / ranges# 返回分类结果classifierResult = classify0(norminArr, normMat, datingLabels, 3)#print(classifierResult)# 打印结果print("这名同学可能%s" % (resultList[classifierResult-1]))# 1、测试代码filename = "datingTestSet.txt"# 打开并处理数据datingDataMat, datingLabels = file2matrix(filename)showdatas(datingDataMat, datingLabels)#2、测试代码datingClassTest()# 正式代码classifyPerson() |
数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | 720 8.215452 0.52524 smallDoses354 68.216555 0.36525 didntLike100 46.215475 0.00215 didntLike800 26.21545 0.65154 smallDoses935 27.02155 0.71525 smallDoses1500 3.21525 0.91242 largeDoses1400 4.74522 0.95321 largeDoses1342 3.21455 0.24565 largeDoses1440 5.33456 0.81454 largeDoses187 65.52452 0.35456 didntLike206 63.34556 0.26443 didntLike300 70.45221 0.31245 didntLike600 20.35455 0.76354 smallDoses825 36.34556 0.24536 smallDoses1356 6.15322 0.12354 largeDoses1452 2.15433 0.98724 largeDoses625 33.15442 0.54675 smallDoses554 25.64652 0.68443 smallDoses325 86.21156 0.00054 didntLike547 86.21156 0.00354 didntLike |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2020-05-04 《C程序设计语言》 练习1-22