

论文笔记:Learning wrapped guidance for blind face restoration
这篇论文主要是讲人脸修复的,所谓人脸修复,其实就是将低清的,或者经过压缩等操作的人脸图像进行高清复原。这可以近似为针对人脸的图像修复工作。在图像修复中,我们都会假设退化的图像是高清图像经过某种函数映射后得到的(比如,由高清图像得到一张模糊的图像可能是使用了高斯模糊核),因此,图像修复的本质就是把这个函数映射找出来。由于神经网络可以近似任意函数,因此在深度学习时代,图像修复已经是一个被解决得比较好的问题了。比如,在图像去噪或者超分任务中,U-Net、FCN 之类的网络结构已经成为标配了。
不过,针对人脸的图像修复则是一个更为严苛的任务。原因主要是以下两点:
- 对于一般的图像,大家可能不会太在意细节恢复得好还是差,但对于人脸来说,由于这是人类最熟悉的部分,因此人脸中的很多细节,如一些皱纹、酒窝等都需要恢复出来才能让人满意,因此,这是一个粒度更细的图像修复任务。
- 另外,通常的图像修复都是针对一种退化场景设计的,比如,在去噪任务中,可能就只是针对某种或某几种噪声而言,而不考虑图像模糊等其他因素,因此任务相对简单。但如果退化的种类太多,退化函数本身可能会非常复杂,即使神经网络也未必能近似出来。正如标题中 blind 所言,退化函数的类型、数量我们是无法事先获悉的。事实上,论文考虑了 jpeg 压缩、高斯模糊、高斯噪声、图片放缩等退化方式,并且对每种方式进行随机组合,因此退化函数是非常复杂的。
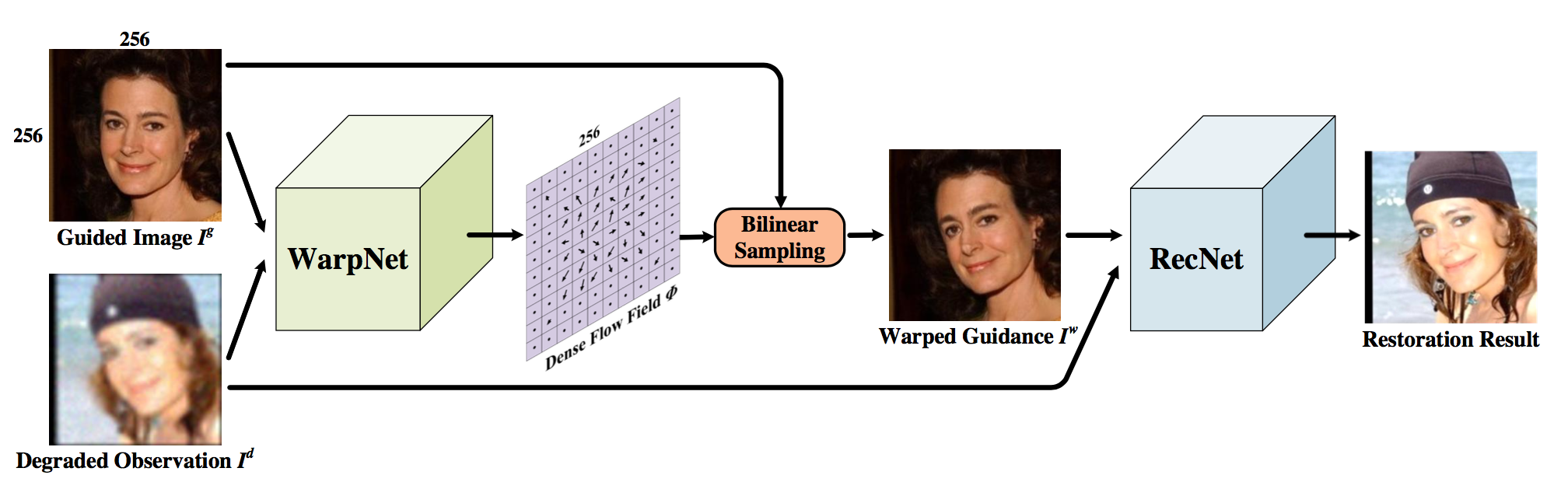
论文方法
为了让任务简单一些,论文用了一张引导图来引入更多先验信息,这里所说的引导图是同一个人在不同姿势以及环境下的高清图片。这个想法也是很正常的,试想一下,对于一张严重模糊的人脸来说,我们如何确定恢复出来的图像是否有酒窝、有眼角纹呢?在没有任何先验的情况下,这是一个 mission impossible,因此,有了一张引导图后,在修复过程中就显得有据可考了。
不过,由于引导图中人脸的姿势和退化图是不一致的,这对于模型来说引导的作用可能偏弱(毕竟神经网络又不知道引导图中的五官位置在哪),因此,论文先对引导图进行矫正,再用这张矫正的引导图去引导网络修复退化的图片。所以,论文的架构总的来说分为两部分:WrapNet 和 RecNet。
WrapNet
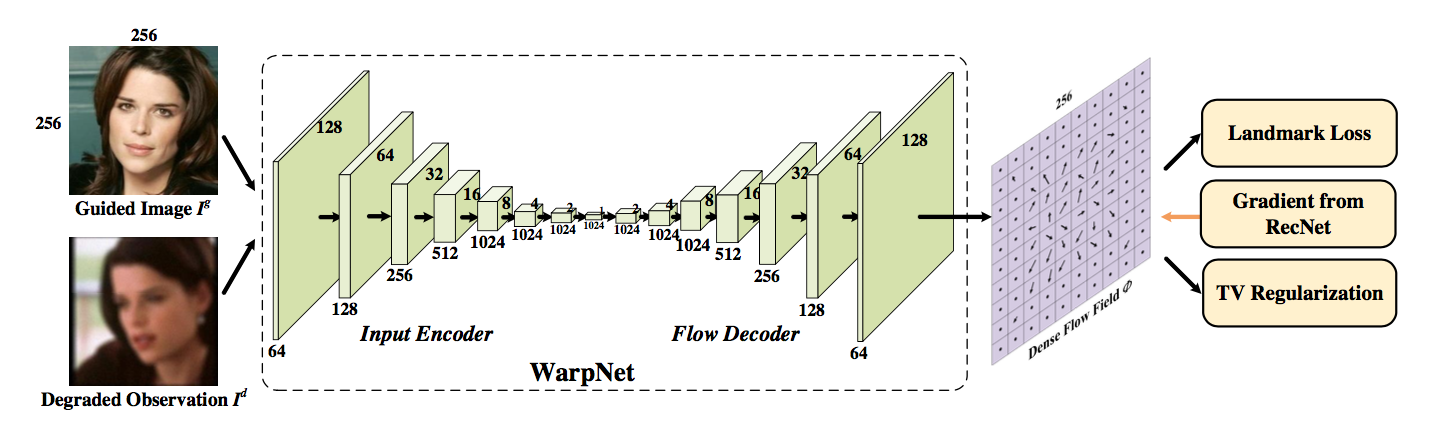
关于如何对引导图的人脸进行矫正的问题,熟悉 STN(Spatial Transform Network) 的读者一定很熟悉了。其实就是计算出矫正 (wrap) 后的图像中每个像素点对应原图的位置,再根据双线性插值得到新的图像。论文用一个 WrapNet 来做这件事情。这个网络的输入是两张叠在一起 (channel通道) 的图片 <退化图,引导图>,网络的结构采用的 auto-encoder,而训练的依据是 wrap 之后人脸的关键点要跟退化图人脸的关键点对齐,也就是图中的 landmark loss。论文采用的数据集其实是不同人的多张高清图片,作者从这些图片中选出正脸的图片作为引导图,然后将其他图片随机采用某种算法 (jpeg压缩等) 退化后得到退化图。因此,可以事先采用其他算法得到每张人脸的关键点,然后用这些关键点来做 landmark loss。
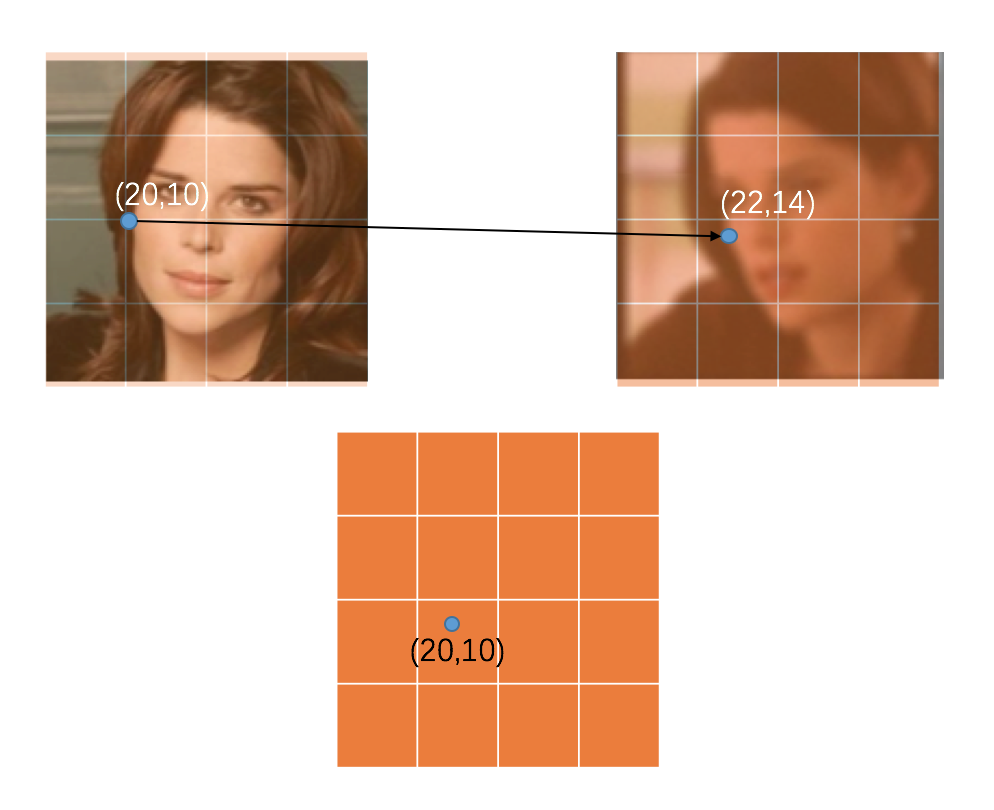
举个接地气的例子。我们可以让网络的输出为一个像素坐标的二维向量矩阵 ,这里的 、 分指图片的高宽,2 是因为每个像素点需要对应 (x, y) 两个数值作为像素位置。例如,如果我们检测到引导图上有个关键点在脸颊的位置是 (20, 10) ,而同样是脸颊这个点,在退化图上的位置是 (22, 14),那么 WrapNet 算出来的矩阵在 (22, 14) 这个点的值理论上就应该是 (20, 10)。之后,我们就可以根据插值的方式,将 wrap 后的图片在 (22, 14) 这个点的像素值填充为原图在 (20, 10) 这个点的像素值。这个矩阵就是论文中所说的 flow field。而 landmark loss 其实就是对网络输出来的矩阵做一次回归,让矩阵这些位置上的向量值和我们理论上需要的向量值做一次 MSE Loss(Mean Square Error)。
不过,关键点的数量毕竟是有限的,这样训练出来的网络虽然可以保证关键点的部位是对齐的,但其他部位却可能偏得很厉害,正因如此,论文中还使用 TV Loss(Total Variation Loss)。这个 Loss 主要是保证 wrap 后的图像能平滑一点。比如说,眼珠 wrap 后的新像素位置与原来的位置相比偏离了 (10, 20),那么眼珠周围的像素 wrap 后的像素位置与原像素偏离的距离应该也是 (10, 20) 左右,这样一来,只要保证每个像素偏移的距离都差不多,整幅图像就相对平滑一点 (所谓平滑,就是说 wrap 后的人脸不会太过扭曲)。具体实现的时候可以通过 flow field 矩阵的梯度来实现。关于 TV Loss 的更多信息,请参考其他资料。
RecNet
训练完 WrapNet 后,就来到论文的重头戏 RecNet。
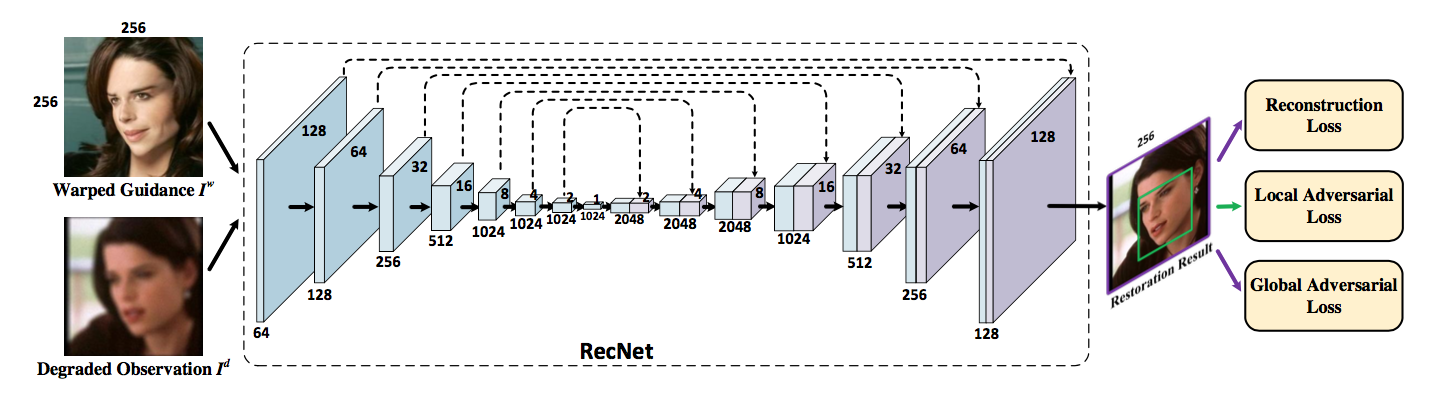
和其他图像超分的方法类似,RecNet 采用的是 U-Net 结构,它的输入与 WrapNet 类似,也是将 wrap 后的图片和退化图叠在一起。在 Loss 选择上,主要是考虑了 MSE Loss 和 VGG Loss。前者是 auto-encoder 中常用的 loss,即通过和 Ground truth 计算逐像素的均方误差来恢复高清图像,而后者通常又称为感知误差 (perceptual loss),这是借鉴了图像风格化中的思路,即根据一个已经训练好的 VGG 网络,将网络输出的图片和 Ground truth 都输入 VGG 后,对 feature map 做 MSE Loss (选择哪一层 feature map 需要进行实验尝试,一般会用第三层后的),目的是希望二者在内容上能保持一致。
但是,仅仅靠这两个 Loss 的话,就只能做到普通的图像修复或超分的效果,对于一些更细节的纹理,这两个 Loss 实在是恢复不出来的 (均方误差其实是在拟合一个整体平均值,而纹理这种高频的信息往往会被当作异常点,因此拟合效果不佳)。再者,人脸中的细节还得靠引导图来提供,如果引导图中有纹理,那么就应该恢复出这些纹理,反之亦然。这类似于条件概率,要给网络加一个开关的作用。那如何引导 RecNet 学习呢?论文中采用了 cGAN(Conditional GAN) 的思路,我觉得这个想法也是水到渠成的,首先,MSE Loss 难以拟合出最真实的人脸数据分布,但 GAN 其实可以把这个分布拟合得更好,另外,用了 Condition 后,也可以起到引导的作用 (其实 RecNet 中将引导图和退化图 concat 在一起,本身就很类似 cGAN)。
论文中总共用了两个 GAN,一个是作用在整幅图像上 (Global cGAN),一个作用在人脸区域 (Local GAN)。Global cGAN 中判别器的输入是三张图片的叠加,真实样本是 (引导图、wrap 图、Ground truth),假样本则是 (引导图、wrap 图、网络输出)。而 Local GAN 论文一笔带过了,我猜测应该就是个普通的 GAN,即真实样本是 Ground truth,而假样本是网络输出。
然而,对论文的这种设计方式,我个人持保留意见。首先,cGAN 的想法是正确的,但我认为这个 GAN 的作用应该是要让 RecNet 可以更好地恢复出纹理,因此判别器对纹理的识别能力应该要尽可能的强,而纹理这种东西和图像内容是无关的,也就是说,对于图像中的每个小块,它都能起到判别作用,因此,我觉得判别器的输入应该是一个个图片块,而不是整张图像或整个人脸区域,所以,我倾向于用 Patch cGAN 来做。
实验
说来惭愧,我自己在复现这篇论文的时候,发现训练出来的模型成了一个普通的去噪/超分模型,对于纹理的修复效果很差,引导图几乎不起作用 (也就是说,不管引导图是什么,重建出来的图片几乎是一样的)。我觉得可能 RecNet 在设计上还可以再优化一下,比如把 content 和 style 分出来之类的。当然,可能是我的能力和大佬们有差距,做不出论文的效果。所以,实验的结果就只能请各位看官自己去论文里面找了。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异