在一般的全联接神经网络中,我们通过反向传播算法计算参数的导数。BP 算法本质上可以认为是链式法则在矩阵求导上的运用。但 CNN 中的卷积操作则不再是全联接的形式,因此 CNN 的 BP 算法需要在原始的算法上稍作修改。这篇文章主要讲一下 BP 算法在卷积层和 pooling 层上的应用。
原始的 BP 算法
首先,用两个例子回顾一下原始的 BP 算法。(不熟悉 BP 可以参考How the backpropagation algorithm works,不介意的话可以看我的读书笔记)
最简单的例子
先看一个最简单的例子(偷个懒,搬个手绘图~囧~):
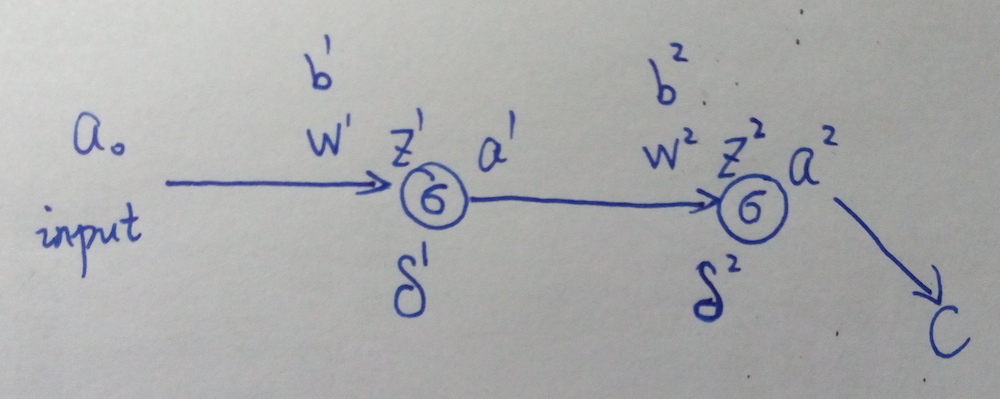
上图中,al 表示第 l 层的输出(a0 就是网络最开始的输入),网络的激活函数假设都是 σ(),wl 和 bl 表示第 l 层的参数,C 表示 loss function,δl 表示第 l 层的误差,zl 是第 l 层神经元的输入,即 zl=wlal−1+bl,al=σ(zl)。
接下来要用 BP 算法求参数的导数 ∂C∂w 和 ∂C∂b。
δ2=∂C∂z2=∂C∂a2∂a2∂z2=∂C∂a2σ′(z2)
δ1=∂C∂z1=δ2∂z2∂a1∂a1∂z1=δ2w2σ′(z1)
算出这两个误差项后,就可以直接求出导数了:
∂C∂b2=∂C∂a2∂a2∂z2∂z2∂b2=δ2
∂C∂w2=∂C∂a2∂a2∂z2∂z2∂w2=δ2a1
∂C∂b1 和 ∂C∂w1 的求法是一样的,这里不在赘述。
次简单的例子
接下来稍微把网络变复杂一点:
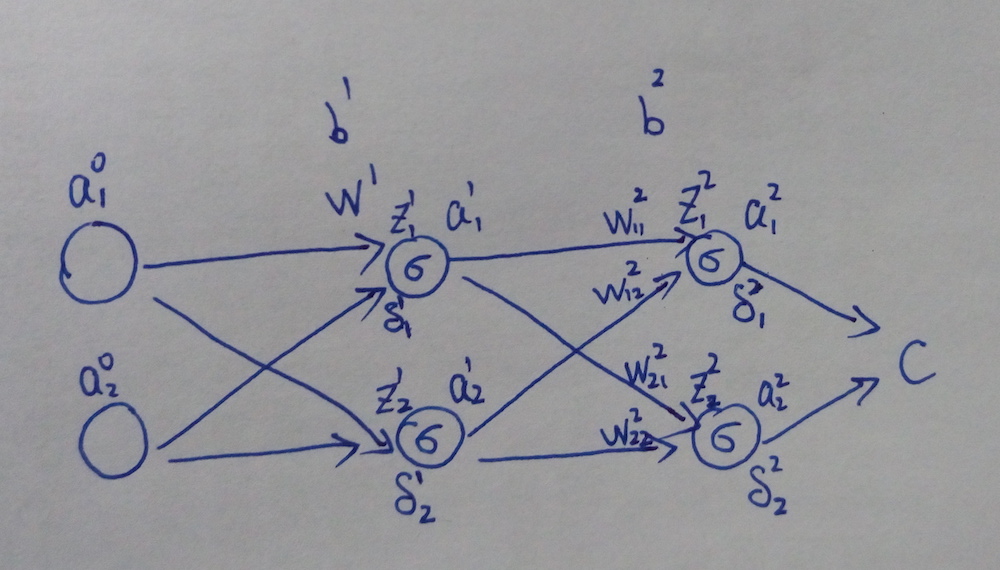
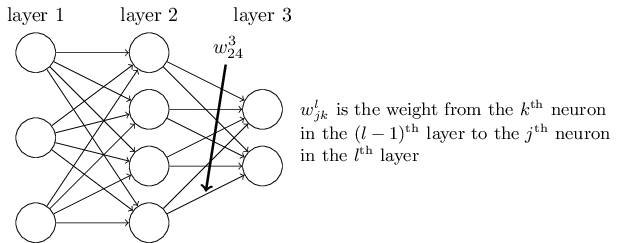
符号的标记和上一个例子是一样的。要注意的是,这里的 Wl 不再是一个数,而变成一个权重矩阵,Wlkj 表示第 l−1 层的第 j 个神经元到第 l 层的第 k 个神经元的权值,如下图所示:
首先,还是要先求出网络的误差 δ。
δ21=∂C∂z21=∂C∂a21σ′(z21)
δ22=∂C∂z22=∂C∂a22σ′(z22)
由此得到:
δ2=[δ21δ22]=⎡⎢⎣∂C∂a21∂C∂a22⎤⎥⎦⊙[σ′(z21)σ′(z22)]
⊙ 表示 elementwise 运算。
接着要根据 δ2 计算前一层的误差 δ1。
δ11=∂C∂z11=∂C∂a21σ′(z21)∂z21∂a11∂a11∂z11+∂C∂a22σ′(z22)∂z22∂a11∂a11∂z11=∂C∂a21σ′(z21)W211σ′(z11)+∂C∂a22σ′(z22)W221σ′(z11)=[∂C∂a21σ′(z21)∂C∂a22σ′(z22)][W211W221]⊙[σ′(z11)](1)
同理,δ12=[∂C∂a21σ′(z21)∂C∂a22σ′(z22)][W212W222]⊙[σ′(z12)]。
这样,我们就得到第 1 层的误差项:
δ1=[W211W221W212W222]⎡⎢⎣∂C∂z21∂C∂z22⎤⎥⎦⊙[σ′(z11)σ′(z12)]=W2Tδ2⊙σ′(z1)(2)
然后,根据误差项计算导数:
∂C∂b2j=∂C∂z2j∂z2j∂b2j=δ2j∂C∂w2jk=∂C∂z2j∂z2j∂w2jk=a1kδ2j∂C∂b1j=∂C∂z1j∂z1j∂b1j=δ1j∂C∂w1jk=∂C∂z1j∂z1j∂w1jk=a0kδ1j
BP 算法的套路
在 BP 算法中,我们计算的误差项 δl 其实就是 loss function 对 zl 的导数 ∂C∂zl,有了该导数后,根据链式法则就可以比较容易地求出 ∂C∂Wl 和 ∂C∂bl。
CNN 中的 BP 算法
之所以要「啰嗦」地回顾普通的 BP 算法,主要是为了熟悉一下链式法则,因为这一点在理解 CNN 的 BP 算法时尤为重要。
下面就来考虑如何把之前的算法套路用在 CNN 网络中。
CNN 的难点在于卷积层和 pooling 层这两种很特殊的结构,因此下面重点分析这两种结构的 BP 算法如何执行。
卷积层
假设我们要处理如下卷积操作:
⎛⎜⎝a11a12a13a21a22a23a31a32a33⎞⎟⎠∗(w11w12w21w22)=(z11z12z21z22)
这个操作咋一看完全不同于全联接层的操作,这样,想套一下 BP 算法都不知从哪里入手。但是,如果把卷积操作表示成下面的等式,问题就清晰多了(卷积操作一般是要把卷积核旋转 180 度再相乘的,不过,由于 CNN 中的卷积参数本来就是学出来的,所以旋不旋转,关系其实不大,这里默认不旋转):
z11=a11w11+a12w12+a21w21+a22w22z12=a12w11+a13w12+a22w21+a23w22z21=a21w11+a22w12+a31w21+a32w22z22=a22w11+a23w12+a32w21+a33w22
更进一步,我们还可以把上面的等式表示成下图:
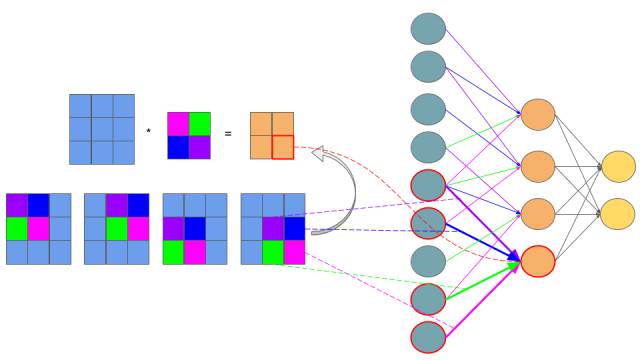
上图的网络结构中,左边青色的神经元表示 a11 到 a33,中间橙色的表示 z11 到 z22。需要注意的是,青色和橙色神经元之间的权值连接用了不同的颜色标出,紫色线表示 w11,蓝色线表示 w12,依此类推。这样一来,如果你熟悉 BP 链式法则的套路的话,你可能已经懂了卷积层的 BP 是怎么操作的了。因为卷积层其实就是一种特殊的连接层,它是部分连接的,而且参数也是共享的。
假设上图中,z 这一层神经元是第 l 层,即 z=zl,a=al−1。同时假设其对应的误差项 δl=∂C∂zl 我们已经算出来了。下面,按照 BP 的套路,我们要根据 δl 计算 δl−1、∂C∂wl 和 ∂C∂bl 。
卷积层的误差项 δl−1
首先计算 δl−1。假设上图中的 al−1 是前一层经过某些操作(可能是激活函数,也可能是 pooling 层等,但不管是哪种操作,我们都可以用 σ() 来表示)后得到的响应,即 al−1=σ(zl−1)。那么,根据链式法则:
δl−1=∂C∂zl−1=∂C∂zl∂zl∂al−1∂al−1∂zl−1=δl∂zl∂al−1⊙σ′(zl−1)(3)
对照上面的例子,zl−1 应该是一个 9 维的向量,所以 σ′(zl−1) 也是一个向量,根据之前 BP 的套路,这里需要 ⊙ 操作。
这里的重点是要计算 ∂zl∂al−1,这也是卷积层区别于全联接层的地方。根据前面展开的卷积操作的等式,这个导数其实比全联接层更容易求。以 al−111 和 al−112 为例(简洁起见,下面去掉右上角的层数符号 l):
∇a11=∂C∂z11∂z11∂a11+∂C∂z12∂z12∂a11+∂C∂z21∂z21∂a11+∂C∂z22∂z22∂a11=δ11w11
∇a12=∂C∂z11∂z11∂a12+∂C∂z12∂z12∂a12+∂C∂z21∂z21∂a12+∂C∂z22∂z22∂a12=δ11w12+δ12w11
(∇aij 表示 ∂C∂aij。如果这两个例子看不懂,证明对之前 BP 例子中的(1)式理解不够,请先复习普通的 BP 算法。)
其他 ∇aij 的计算,道理相同。
之后,如果你把所有式子都写出来,就会发现,我们可以用一个卷积运算来计算所有 ∇al−1ij:
⎛⎜
⎜
⎜⎝00000δ11δ1200δ21δ2200000⎞⎟
⎟
⎟⎠∗(w22w21w12w11)=⎛⎜⎝∇a11∇a12∇a13∇a21∇a22∇a23∇a31∇a32∇a33⎞⎟⎠
这样一来,(3)式可以改写为:
δl−1=∂C∂zl−1=δl∗rot180(Wl)⊙σ′(zl−1)(4)
(4)式就是 CNN 中误差项的计算方法。注意,跟原始的 BP 不同的是,这里需要将后一层的误差 δl 写成矩阵的形式,并用 0 填充到合适的维度。而且这里不再是跟矩阵 WlT 相乘,而是先将 Wl 旋转 180 度后,再跟其做卷积运算。
卷积层的导数 ∂C∂wl 和 ∂C∂bl
这两项的计算也是类似的。假设已经知道当前层的误差项 δl,参考之前 ∇aij 的计算,可以得到:
∇w11=∂C∂z11∂z11∂w11+∂C∂z12∂z12∂w11+∂C∂z21∂z21∂w11+∂C∂z22∂z22∂w11=δ11a11+δ12a12+δ21a21+δ22a22
∇w12=∂C∂z11∂z11∂w12+∂C∂z12∂z12∂w12+∂C∂z21∂z21∂w12+∂C∂z22∂z22∂w12=δ11a12+δ12a13+δ21a22+δ22a23
其他 ∇wij 的计算同理。
跟 ∇aij 一样,我们可以用矩阵卷积的形式表示:
⎛⎜⎝a11a12a13a21a22a23a31a32a33⎞⎟⎠∗(δ11δ12δ21δ22)=(∇w11∇w12∇w21∇w22)
这样就得到了 ∂C∂wl 的公式:
∂C∂wl=al−1∗δl(5)
对于 ∂C∂bl,我参考了文末的链接,但对其做法仍然不太理解,我觉得在卷积层中,∂C∂bl 和一般的全联接层是一样的,仍然可以用下面的式子得到:
∂C∂bl=δl(6)
理解不一定对,所以这一点上大家还是参考一下其他资料。
pooling 层
跟卷积层一样,我们先把 pooling 层也放回网络连接的形式中:
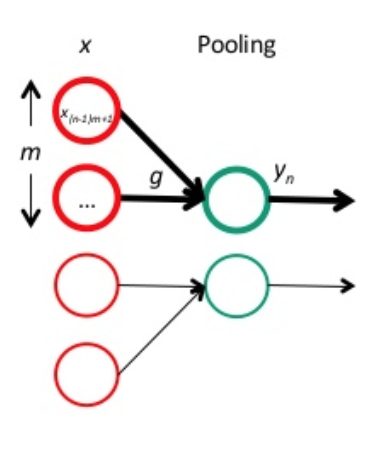
红色神经元是前一层的响应结果,一般是卷积后再用激活函数处理。绿色的神经元表示 pooling 层。很明显,pooling 主要是起到降维的作用,而且,由于 pooling 时没有参数需要学习,因此,当得到 pooling 层的误差项 δl 后,我们只需要计算上一层的误差项 δl−1 即可。要注意的一点是,由于 pooling 一般会降维,因此传回去的误差矩阵要调整维度,即 upsample。这样,误差传播的公式原型大概是:
δl−1=upsample(δl)⊙σ′(zl−1)。
下面以最常用的 average pooling 和 max pooling 为例,讲讲 upsample(δl) 具体要怎么处理。
假设 pooling 层的区域大小为 2×2,pooling 这一层的误差项为:
δl=(2846)
首先,我们先把维度还原到上一层的维度:
⎛⎜
⎜
⎜⎝0000028004600000⎞⎟
⎟
⎟⎠
在 average pooling 中,我们是把一个范围内的响应值取平均后,作为一个 pooling unit 的结果。可以认为是经过一个 average() 函数,即 average(x)=1m∑mk=1xk。在本例中,m=4。则对每个 xk 的导数均为:
∂average(x)∂xk=1m
因此,对 average pooling 来说,其误差项为:
δl−1=δl∂average∂x⊙σ′(zl−1)=upsample(δl)⊙σ′(zl−1)=⎛⎜
⎜
⎜⎝0.50.5220.50.522111.51.5111.51.5⎞⎟
⎟
⎟⎠⊙σ′(zl−1)(7)
在 max pooling 中,则是经过一个 max() 函数,对应的导数为:
∂max(x)∂xk={1if xk=max(x)0otherwise
假设前向传播时记录的最大值位置分别是左上、右下、右上、左下,则误差项为:
δl−1=⎛⎜
⎜
⎜⎝2000000804000060⎞⎟
⎟
⎟⎠⊙σ′(zl−1)(8)
参考
欢迎关注我的公众号「AI小男孩」,立志用大白话讲懂AI






【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异