

论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
在上计算机视觉这门课的时候,老师曾经留过一个作业:识别一张 A4 纸上的手写数字。按照传统的做法,这种手写体或者验证码识别的项目,都是按照定位+分割+识别的套路。但凡上网搜一下,就能找到一堆识别的教程,分割的文章次之,而定位的文章就少之又少了。这其中的缘由也很简单:识别目前来说已经不是什么难事了,所以容易写,但分割和定位却仍然是一个头疼不已的问题,不同场景方法不同,甚至同一场景也要结合多种图像处理方法,因此很难有通用的解决策略。在深度学习火起来之后,很多研究人员开始尝试用深度学习的特征提取能力来解决定位的问题,本文学习的这篇论文,就是被誉为用 CNN 解决物体定位的开山之作:R-CNN。
这篇文章打算浅浅地分析一下 R-CNN。
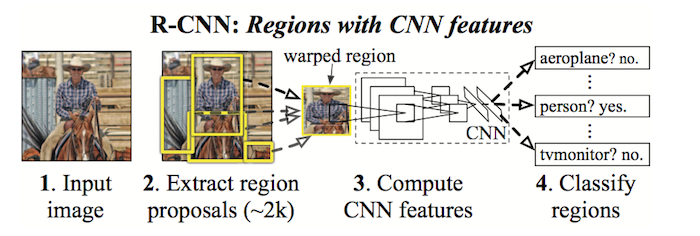
R-CNN是什么
R-CNN 中的 R 指的是 Region,所以,R-CNN 其实就是用 CNN 来定位 Region。它由 Ross Girshick 等人于 2014 年提出,当时实现了物体检测上 state-of-art(最好) 的精度,而且速度上也比以往的方法有所提高。
R-CNN 的流程
文章最开始的图片中给出了 R-CNN 的基本框架。R-CNN 的算法流程其实很简单,主要分为三步:
- 通过 Selective Search 选出大约 2000 个 bounding box(不了解 Selective Search 的同学可以上网自学,不介意的话还可以查看我上一篇文章,由于本文重点是 R-CNN,所以这里直接把它当作一个黑盒子使用了);
- 用 CNN 对这些 bounding box 提取特征;
- 使用 linear SVM 对这些特征进行分类,判断 bounding box 内是否是物体,或者是什么物体。
训练阶段
训练阶段分为 CNN 和 SVM 两部分。
1. Supervised pre-training
CNN 模型直接采用了 Krizhevsky 等人在 2012 年的分类网络模型
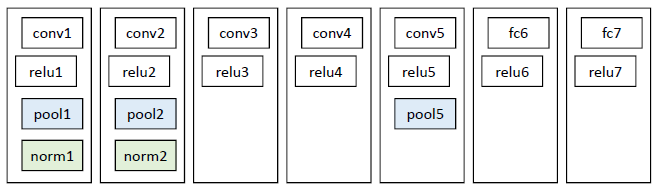
这个网络的参数比较多(超过一百万),因此需要大量的训练数据。作者直接将 Krizhevsky 在 ILSVRC 2012 上训练好的参数复制过来,有人称这种做法为「迁移学习」,因为 CNN 的本质就是提取图片的特征(类似于 SIFT ),因此,尽管训练集不同,训练出来的参数其实是可以通用的。当然啦,对于一些更具体的任务(如手写体识别),个人觉得最好还是单独训练一下。
2. Domain-specific fine-tuning
前面刚说了,直接用其他数据集训练好的参数不太保险,作者马上用行动打消了我的疑虑。这一步,为了让 CNN 适应新的数据集,作者在原来参数的基础上,用 PASCAL VOC 的数据继续训练网络(PASCAL VOC 是论文采用的数据集)。另外,考虑到 VOC 的数据集比较小(ILSVRC 2012 有 1000 种类别,VOC 只有 20 种),论文将原网络最后一层 1000 classification 的输出层减小为 21 classification(20个类别 + 背景),并将这一层 fc 的参数随机初始化,这一步相当于优化参数 (fine-tuning) 的作用。除此之外,为了获得大量的训练样本,还需要事先对 VOC 数据集标定出物体所在的矩形区域(这一步比单纯的图片类别标记难度要大得多,因此数据量很少,且缺乏背景数据)。
之后,论文采用 Selective Search 在 VOC 上选出很多矩形框,将与标准矩形框的覆盖区域 >= 0.5 IoU 的标为正样本,其余的标为负样本(负样本应该就是背景了)。然后,采用 SGD,以 0.001 为学习率进行训练。每次训练的 batch 为 32 个正样本和 96 个背景样本。这里之所以让背景样本多于正样本,原因在于图片中的正样本窗口相比于背景窗口,数量很少。
关于 IoU,这里简单提一下。IoU 指的是 intersection-over-union,是一个定位精度的评价标准。因为算法的结果不可能百分之百跟人工标定的矩形数据吻合,因此就需要有一个标准判断结果的准确性。
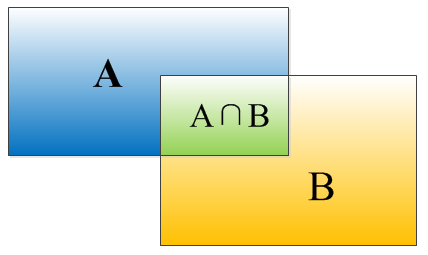
上面这幅图摘自文末链接。IoU 的计算方法为:。
3. Object category classifiers
训练完 CNN 后,我们就可以通过它提取物体的特征了。这里使用 fc7 层输出的 4096 维的向量作为特征。
对于每一类物体,我们要训练一个二分类的 SVM 模型,由 SVM 来判断矩形区域内是否有物体存在。SVM 的训练数据是 CNN 提取的特征向量,对应的 label 和上面一样分为 21 类。与 CNN 不同的是,我们重新调整了 IoU 的阈值。在 CNN 中,我们将 >= 0.5 IoU 的矩形都标为正样本,但在训练 SVM 的时候,作者发现,取 0.3 IoU 效果最好。所以,这一次我们将 >= 0.3 IoU 的矩形都标记为正样本作为 SVM 的训练数据。
预测阶段
预测的时候,我们先通过 Selective Search 选出 2000+ 矩形区域,用 CNN 的 fc7 层提取特征向量,再用 SVM 对这些矩形区域进行评分判断。由于矩形区域存在大量的重叠,因此论文最后用非极大值抑制(non-maximum suppression)的方法对这些区域进行筛选。
具体做法是:先从所有矩形区域中,选出 SVM 得分最高的区域,将与该区域的 IoU 面积超过阈值的都删除,然后从剩下的矩形区域中再挑选出得分最高的,继续剔除 IoU 超过阈值的区域,如此往复直到没有矩形区域可选为止。
做完这一步,剩下的矩形基本就是比较可靠的物体所在的位置了。但作者还想更进一步,结合 CNN 的 pool5 层提取的特征以及 DPM 中的 box regression 对矩形位置进一步微调。这一步论文没有详细说明,而我自己也知之甚少,日后明白了再补上。
几个细节问题
1. CNN的输入
论文中使用的 CNN 需要输入 227*227 的图片,但 Selective Search 找出来的矩形框尺寸各异,因此需要提供一种方法对矩形中的图片进行归一化。
归一化方法无非分为两种:各向异性的缩放和各向同性的缩放。
各向异性的缩放就是直接将图片缩放成 227*227 的规格,而不管图片内容是否扭曲,这种方法最简单,但效果应该比较差。
各向同性的缩放就是要保持长宽的比例,一种方法是将 bounding box 裁剪出来后,先缩放,再用固定的背景颜色填充到需要的尺寸;另一种方法是将原本的 bounding box 的边界延伸后,再进行裁剪及缩放,如果延伸后的 bounding box 超过图片边界,就用 bounding box 中的颜色均值进行填充。
论文中采用的应该是各向异性的方法,但我倾向于采用各向同性的方法。
2. CNN对特征的提取
CNN 中包含很多层,具体要选用哪一层的输出作为特征呢?为此,作者进行了多次对比试验:
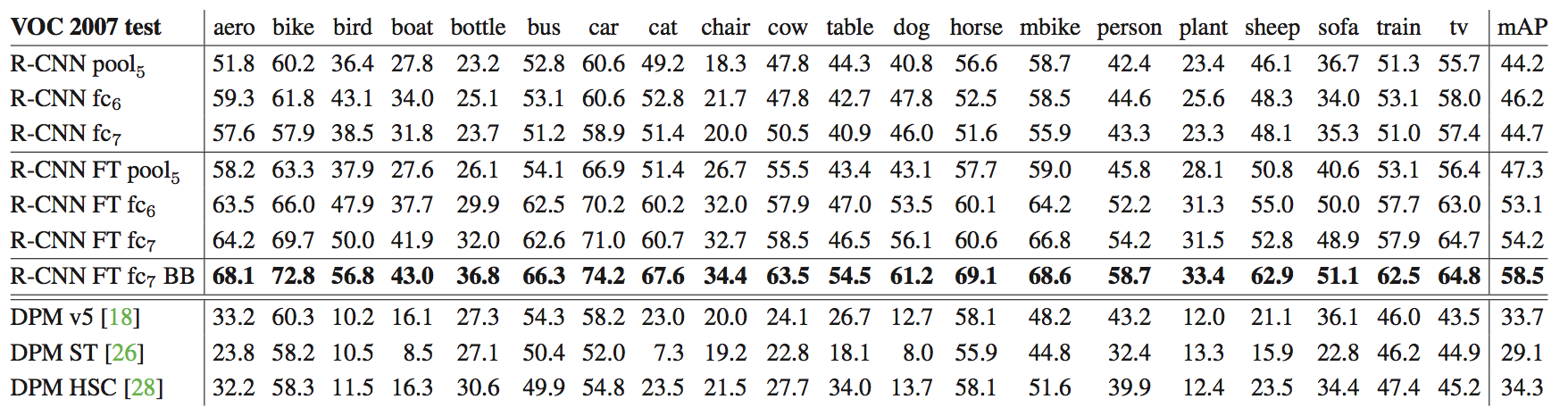
实验结果显示,如果没有进行 fine-tuning,那么 pool5、fc6 以及 fc7 的结果都相差无几,而如果进行 fine-tuning 后,fc6 和 fc7 的结果有了显著提升。
前面说过,FT 就是针对特定情景的训练集,将原本最后一层的 1000 维输出转变为 21 维的输出。如果没有进行 FT,那么相当于把 CNN 当作一种通用的图像特征来使用(只在 ILSVRC 2012 上训练的 CNN,效果上类似 SIFT),其结果表明,pool5、fc6 以及 fc7 效果上差不多,也就是说,在这种情况下,fc6 和 fc7 对特征的表达几乎不起作用,因此我们可以得出这样一个结论:在没有 FT 的时候,CNN 的特征主要是由卷积层(这里是 pool5)学习出来的。
但如果对 CNN 做过 FT 处理,fc6 和 fc7 的效果会有显著提升,反倒是 pool5 的提升效果比较小。对此,我的理解是这样的:pool5 提取的更像是一种通用的特征,不针对特定的训练集,而 fc6 和 fc7 则更具有导向性,对具体的应用场景比较敏感。套用文末参考链接的例子,如果我们要通过图像中的人脸预测性别,那么 pool5 提取的是通用的人脸特征,而 fc6 和 fc7 提取的则是更多跟性别相关的信息。
表中第 7 行是用 BB(binding box regression)微调后的结果,精度上有了进一步提高。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异