

Data-Free Quantization代码实现
(本文首发于公众号,没事来逛逛)
前面两篇文章介绍 Data-Free Quantization,这篇文章准备用 pytorch 实现一遍 weight equalize 算法,并捋一下刚踩的新坑。
Weight Equalization
其实 pytorch 官方有一个 weight equalize 的实现 (参考:https://github.com/pytorch/pytorch/blob/v1.8.1/torch/quantization/_equalize.py),但这个实现没法用于 depthwise conv,因此这篇文章准备自己实现一个 weight equalize。
新踩的坑
一
然而,就当我信心满满准备用 mobilenet 跑一波效果时,突发又踩到另一个坑。
记得我在之前的文章说过,weight equalize 可以作用在 conv->relu->conv 这样的卷积对上,其中的 relu 可以是任意分段线性的函数,比如 leakyrelu、prelu、relu6 以及任意满足下面形式的函数:
都可以用于 weight equalize。因为这类函数稍加变换都可以满足 ,其中 由 演变而来:
在实际使用中,除了对 weight 做 equalize 外,还需要把这类函数换成 。
以 mobilenetv2 中的 relu6 为例,一般的 relu6 长这个样子:
经过变换后得到:
这样一来,,然后,对于网络里面需要做 weight equalize 的 conv->relu6->conv 组合,我们都需要把 换成 ,这样才能保证做完 equalize 后网络的输出和之前等价。
而 relu、leakyrelu、prelu 这些函数的 都是它们自身,所以可以直接使用。
而 这个东东就比较复杂,虽然只是一个线性分段函数,但要知道,我们可是每个 channel 都会对应一个 ,换句话说, 在处理不同 channel 的时候,得根据不同的 调整分段区间。这根本没法用。。
然后我就想,要不换成 shufflenet 试试。结果发现 shufflenet 里面用了很多分组卷积 (group conv),更加没法用了。
想到这里,我已经一口老血吐出来了,这个 weight equalize 方法看起来牛逼,实际上不讲武德啊。。这两个典型的用了 depthwise conv 的小网络都没法用!

没办法,最后做了妥协,把 mobilenetv2 里面的 relu6 都换成 relu (通常需要 finetune 一下网络),然后再用 weight equalize 试试效果先。
二
除此以外,还存在另一个隐藏的坑:用于 weight equalize 的网络模块中不能有多个分支。说人话就是,我们只能针对下面的这类结构做 weight equalize:
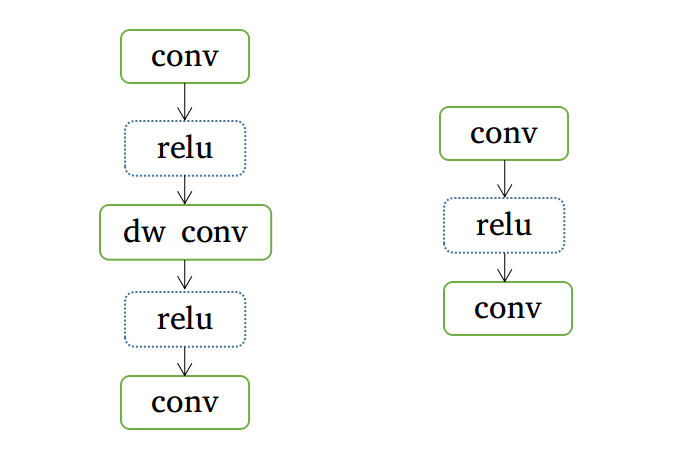
(上图中的 relu 函数可有可无,而且可以换成 leakyrelu 和 prelu)
如果这个模块中间出现其他分支 (最后一个 conv 除外),比如这样:
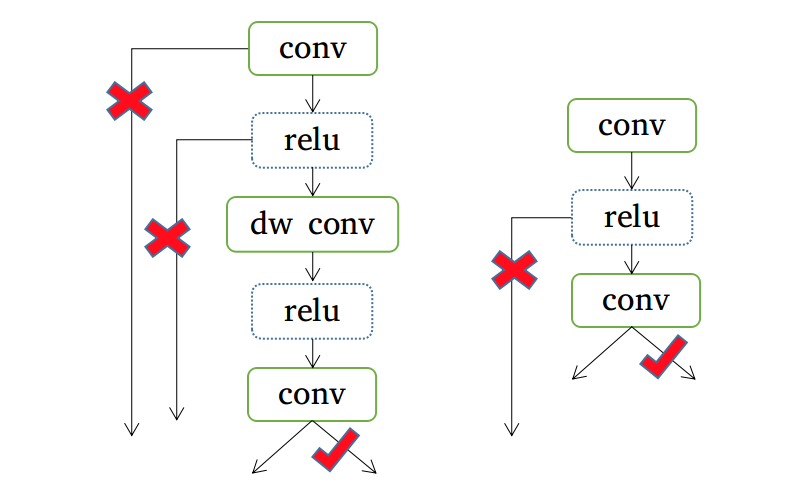
就没法做 equalize 了。
因为 weight equalize 要求对一个卷积做缩放之后,后面必须跟着一个卷积把这个缩放因子抵消掉,如果跟着多个分支,那除非这几个分支都跟着一个卷积,且每个分支的缩放因子一样,否则网络的结果是不等价的。因此,为了实现上的方便,这种多分支的情况就被我跳过了。
代码实现
下面开始代码实现环节。完整代码可以在后台回复「001」获取,因为有些坑没填完,暂时还没打算开源。
以下代码会用上 Pytorch FX 的功能,因此需要在 1.8 以上的版本使用。关于 FX 如何使用,限于篇幅这里就不展开,后面再找个机会单独介绍。
我们先梳理一下算法流程:
- 合并 Conv 和 BatchNorm;
- 按照 conv->(relu)->conv、conv->(relu)->depthwise conv->(relu)->conv 的模式寻找卷积对;
- 对卷积对做 weight equalize。
对于 Conv 和 BatchNorm 的合并,我在之前的文章中介绍过原理,这里先略过。pytorch 官方也悄咪咪内置了这部分功能 (https://github.com/pytorch/pytorch/blob/v1.8.1/torch/fx/_experimental/fuser.py),由于涉及到 FX 的用法,之后有机会再细讲。
整个算法框架如下:
def equalize(model, inplace=False): if not inplace: model = deepcopy(model) model.eval() # 提取模型graph,方便匹配卷积对 model = torch.fx.symbolic_trace(model) # 步骤1:fuse BN model = fuse(model) # 步骤2:寻找适合equalize的卷积对 paired_modules_list = _find_module_pairs(model) name_to_module = {} name_set = {name for pair in paired_modules_list for name in pair} for name, module in model.named_modules(): if name in name_set: name_to_module[name] = module # 步骤3:每个卷积对进行equalize for i, pair in enumerate(paired_modules_list): print("equalize: ", pair) if len(pair) == 2: _cross_layer_equalization(name_to_module[pair[0]], name_to_module[pair[1]]) elif len(pair) == 3: _cross_layer_depthwise_equalization(name_to_module[pair[0]], name_to_module[pair[1]], name_to_module[pair[2]]) return model
接下来是踩坑重点:寻找合适的卷积对,这部分是需要分 conv 和 fc 两种情况实现的:
def _find_module_pairs(model): name_modules = dict(model.named_modules()) module_pair_lists = [] for node in model.graph.nodes: if node.op == "call_module": # "call_module"表示torch.nn中定义的op module = name_modules[node.target] if type(module) == torch.nn.Conv2d and \ module.groups == 1: # 第一个卷积默认是普通卷积,group=1 layer_group = _find_conv_downstream_layer_to_scale(node, name_modules) if len(layer_group) != 0: module_pair_lists.append(layer_group) if type(module) == torch.nn.Linear: layer_group = _find_fc_downstream_layer_to_scale(node, name_modules) if len(layer_group) != 0: module_pair_lists.append(layer_group) module_pair_lists = [pair for pair in module_pair_lists if len(pair) == 2 or len(pair) == 3] return module_pair_lists def _find_conv_downstream_layer_to_scale(cur_node, name_modules): layer_group = [] # 匹配conv->(relu)->conv,匹配到的话,就把卷积对放到layer_group if _match_conv_conv(cur_node, name_modules, layer_group): return layer_group # 匹配conv->(relu)->dw conv->(relu)->conv,匹配到的话,就把卷积对放到layer_group elif _match_conv_dwconv_conv(cur_node, name_modules, layer_group): return layer_group else: return []
这部分代码比较杂,我加了一些注释,希望能帮助需要的同学看懂。当然在此之前最好先熟悉一下 FX 中的一些 api 的使用。
接下来是另外两个核心函数:一个是对 conv-conv 这样的匹配对进行 equalize,并一个则是对 conv-dwconv-conv 进行 equalize,这一部分的实现和我前一篇文章中给出的伪代码基本一样,这里简单贴出处理 conv-conv 的代码:
def _cross_layer_equalization(module1, module2): if type(module1) not in _supported_types or type(module2) not in _supported_types: raise ValueError("module type not supported:", type(module1), " ", type(module2)) weight1 = module1.weight weight2 = module2.weight bias1 = module1.bias # 重排,这一部分其实可有可无,不过重排可以更好地理解代码逻辑 if type(module2) == torch.nn.Conv2d: weight2 = weight2.permute(1, 0, 2, 3) elif type(module2) == torch.nn.Linear: weight2 = weight2.permute(1, 0) # 计算两个weight的数值范围 r1 = compute_range(weight1) r2 = compute_range(weight2) # 计算缩放因子,这里包含了每个kernel的缩放系数 s = r1 / torch.sqrt(r1 * r2) # 对scale进行维度扩张,方便进行broadcast size = [1] * weight1.ndim size[0] = weight1.size(0) s = torch.reshape(s, size) weight1 = weight1 * (1 / s) weight2 = weight2 * s if type(module2) == torch.nn.Conv2d: weight2 = weight2.permute(1, 0, 2, 3) elif type(module2) == torch.nn.Linear: weight2 = weight2.permute(1, 0) module1.weight = torch.nn.Parameter(weight1) module2.weight = torch.nn.Parameter(weight2) if bias1 is not None: s = s.view(-1,) bias1 = bias1 * (1 / s) module1.bias = torch.nn.Parameter(bias1)
这一部分相对好理解一些,同样地,我也加了一些注释,方便有需要的同学理解。
效果如何
这里我分别测试了 mobilenetv2 (把 relu6 换成 relu) 和 resnet18 的效果 (完整测试代码见 test_weight_equalize.py 文件)。
mobilenetv2
首先,我查看了 mobilenetv2 前几层可分离卷积的数值范围:
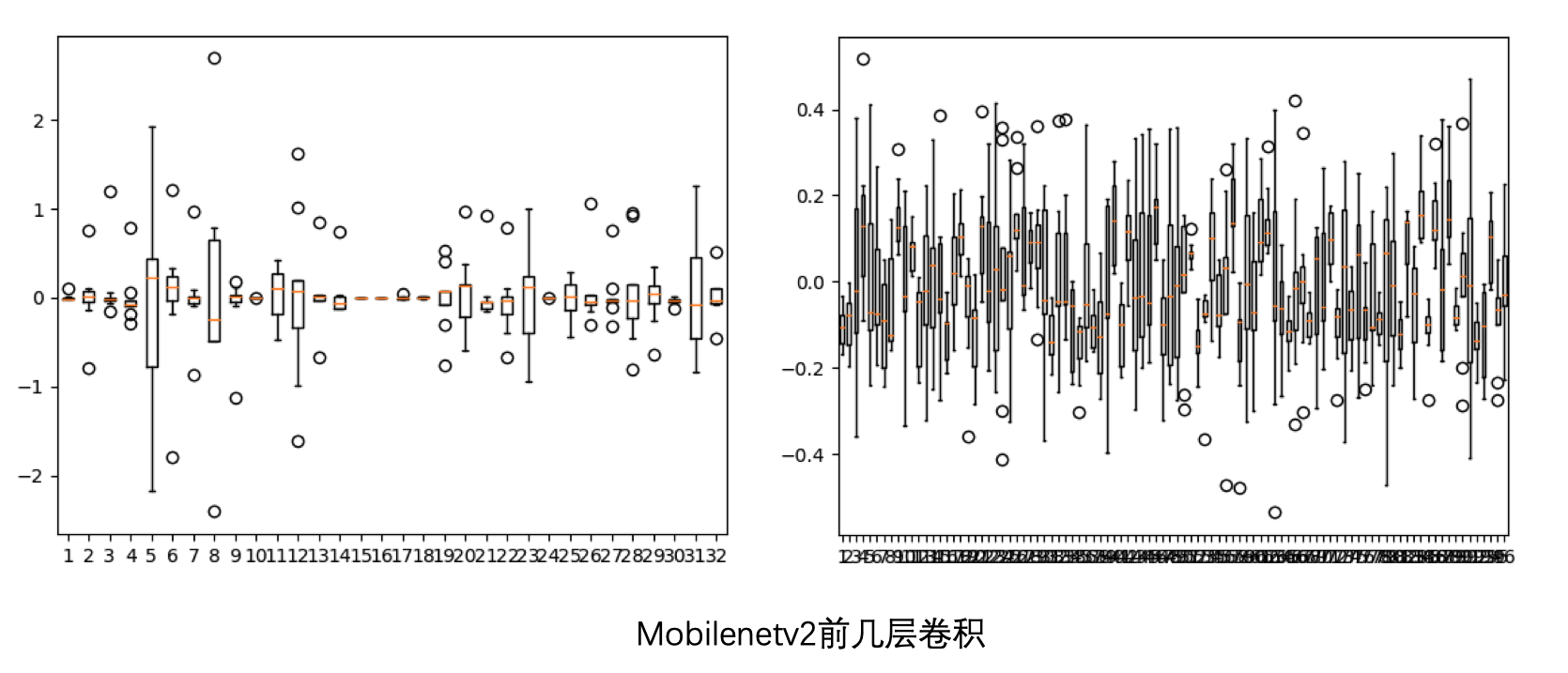
这个数值范围确实比较大,但似乎还能忍受。
然后是把 BatchNorm 和 Conv 合并后:
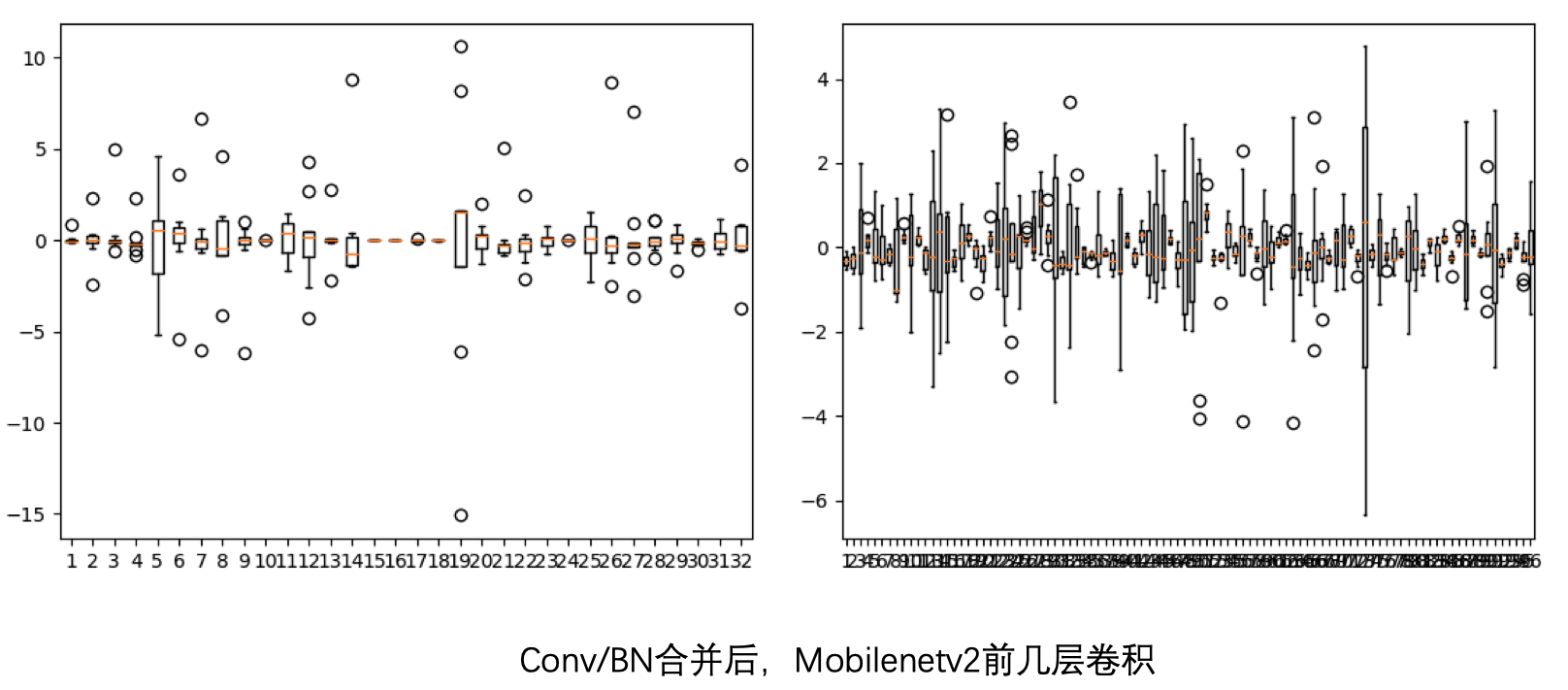
但这一步,这个数值范围就大的有点难以接受了,和论文里面给出的比较相似了。
做完 weight equalize 后:
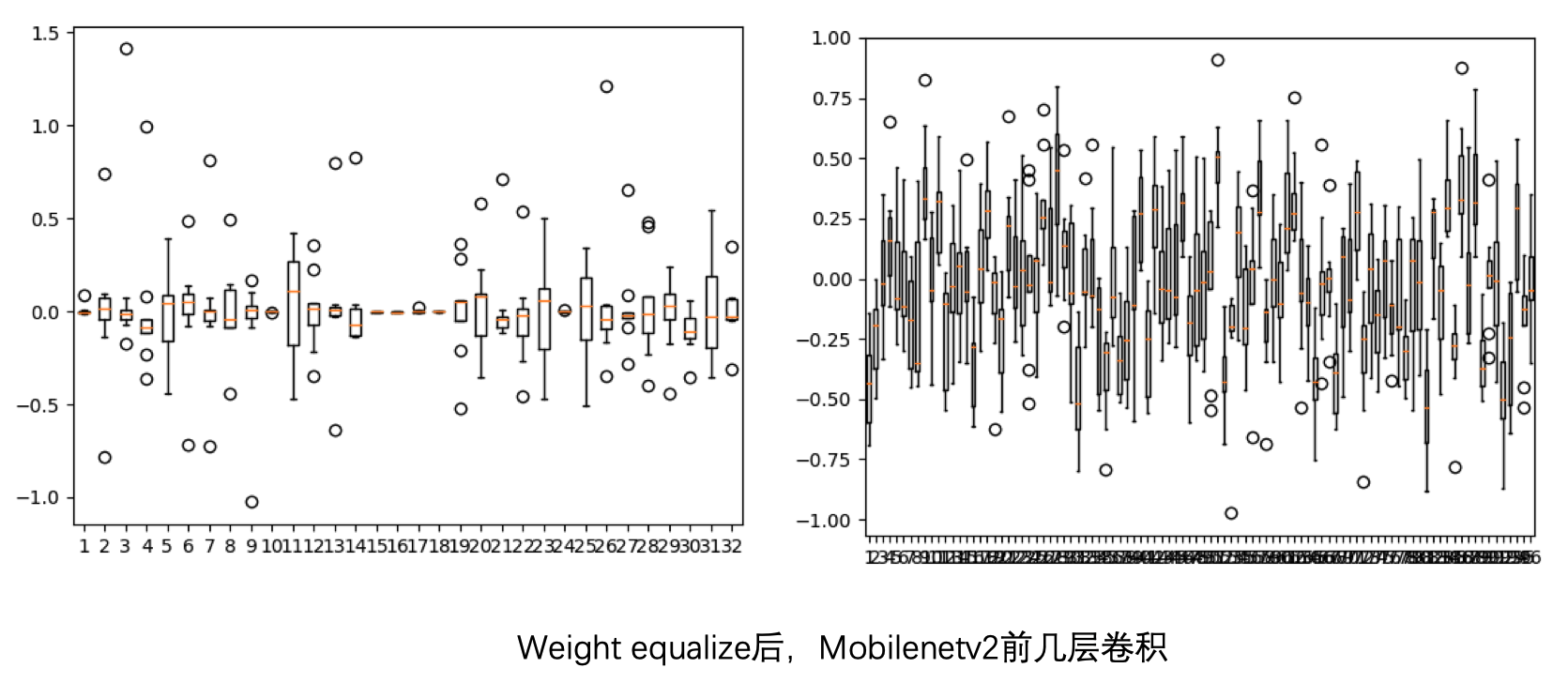
数值范围拉小了很多,跟第一张图比较接近了。
resnet18
然后再看一下 resnet18 的情况。
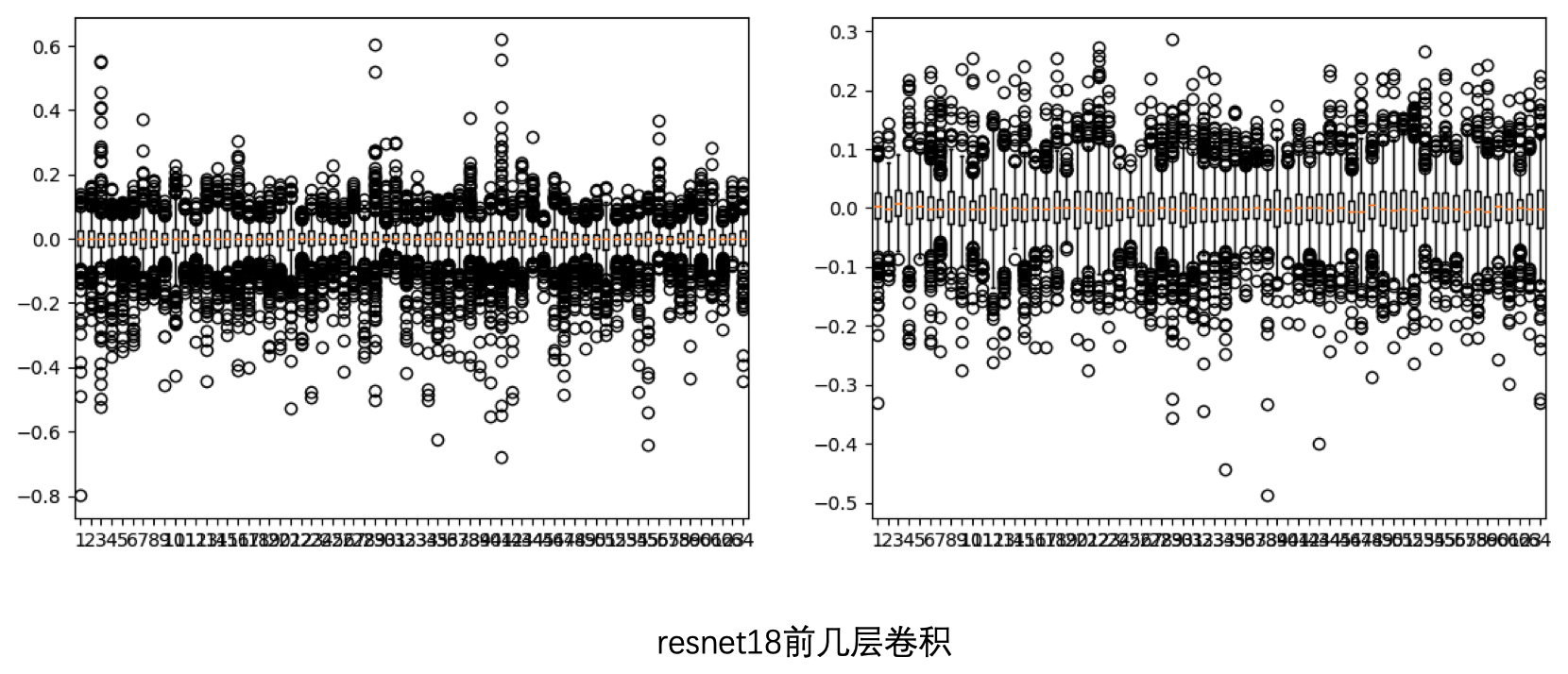
同样地,看一下前几层卷积的数值范围:
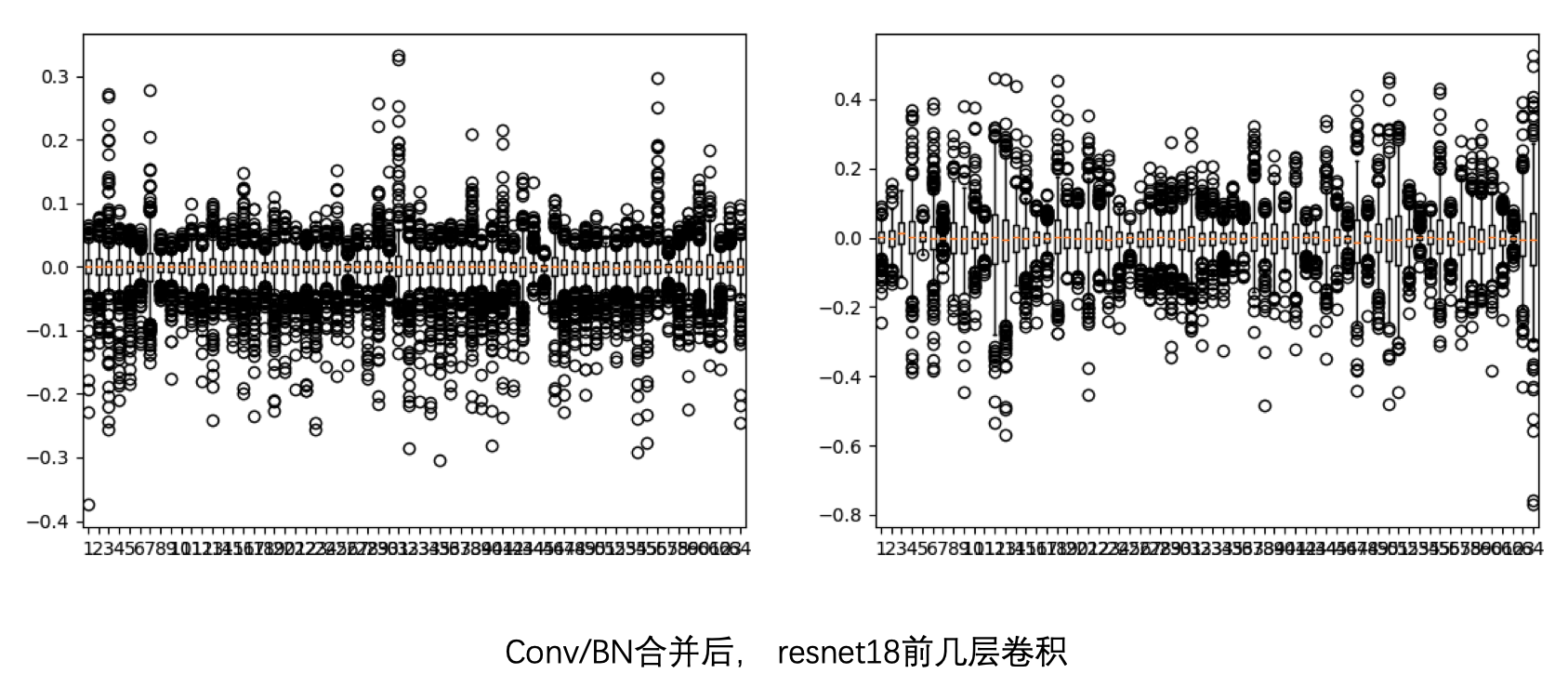
合并 BN 后:
做完 weight equalize 后:
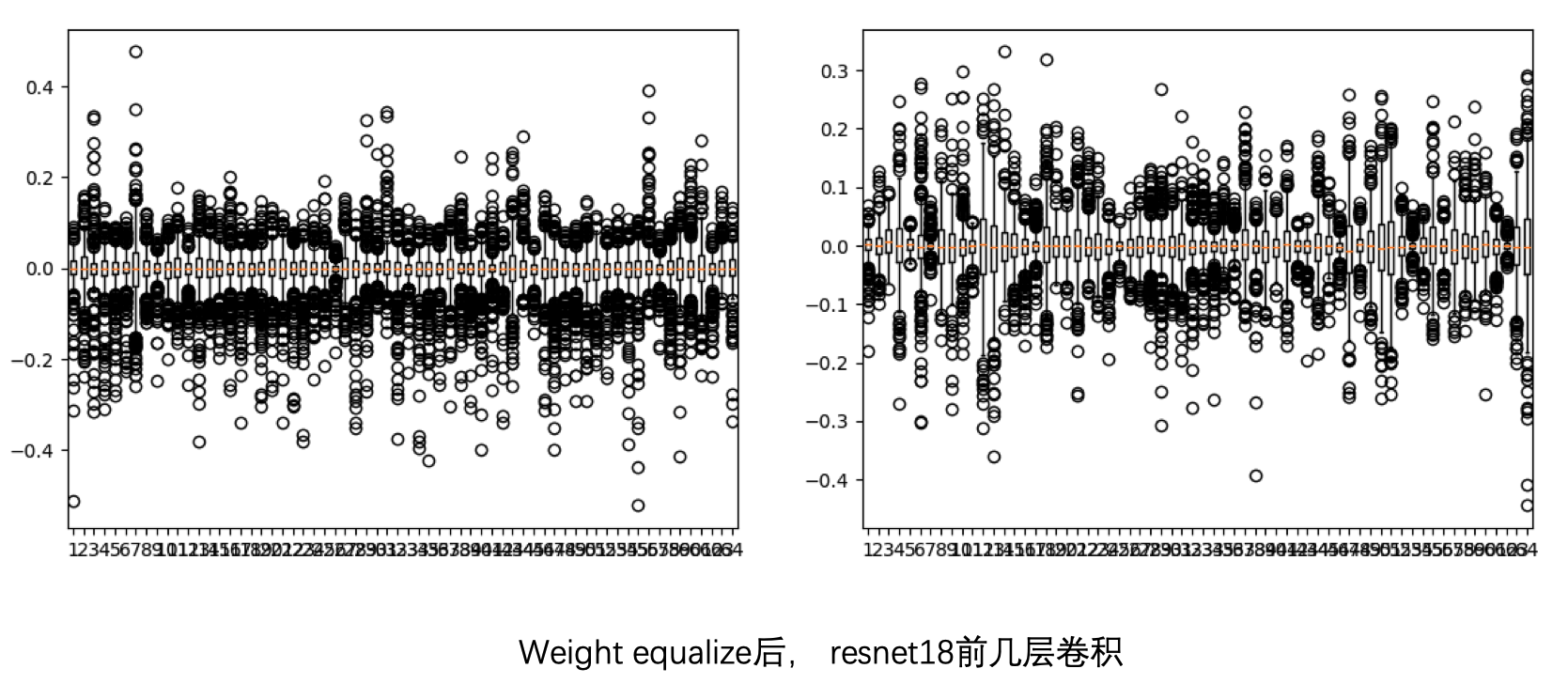
几乎没啥变化,所以 weight equalize 在这种没有可分离卷积的网络上面其实作用不大。
由此,可以初步得出一个结论:
- depthwise conv 会使得卷积的 kernel 之间在数值分布上产生较大差异;
- batchnorm 会使得这种差异进一步放大,因为 batchnorm 会单独对每个 input channel 都会计算均值和方差。
最后,再给大家提个醒,如果想要使用 weight equalize,先看看你的网络里面是不是使用了很多 depthwise conv,以及这些 conv 之间的激活函数是不是 ReLU、LeakyReLU、PReLU 这些,以及有没有 group conv 在里面破坏氛围,当这几点都满足后,weight equalize 才能发挥作用。
总结
这篇文章介绍了我用 pytorch fx 手撸 Weight Equalization 算法的过程中踩的几个坑,可以看出,这个算法对 mobilenetv2 这类网络确实有不小的作用,但限制也挺多,比如对激活函数有比较大的约束等。
代码方面应该还存在不少 bug。此外,我在看公司大佬实现的代码时发现,其实没必要像高通那样把 depthwise conv 单独拿出来实现,可以把可分离卷积和分组卷积都统一起来,用 conv-conv 的模式做 equalize 就可以,这样可以简便很多,效果也相差无几。这里就不方便透漏太多了。
另外,有读者问:还有 Bias Correction 呢?哪去了!
被 Weight Equalize 坑了这么久,只剩一口仙气了,谁爱 Correction 谁去
欢迎关注我的公众号:大白话AI,立志用大白话讲懂AI。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异