

Pytorch推出fx,量化起飞
(本文首发于公众号,没事来逛逛)
Pytorch1.8 发布后,官方推出一个 torch.fx 的工具包,可以动态地对 forward 流程进行跟踪,并构建出模型的图结构。这个新特性能带来什么功能呢?别的不说,就模型量化这一块,炼丹师们有福了。
其实早在三年前 pytorch1.3 发布的时候,官方就推出了量化功能。但我觉得当时官方重点是在后端的量化推理引擎(FBGEMM 和 QNNPACK)上,对于 pytorch 前端的接口设计很粗糙。用过 pytorch 量化的同学都知道,这个量化接口实在是太麻烦、太粗糙、太暴力了。官方又把这个第一代的量化方式称为 Eager Mode Quantization。我后面会用一个例子来展示这种方式有多傻x。
而随着 fx 的推出,由于可以动态地 trace 出网络的图结构,因此就可以针对网络模型动态地添加一些量化节点。官方又称这种新的量化方式为 FX Graph Mode Quantization。上一张官方的图来对比一下这两种方式的优缺点:
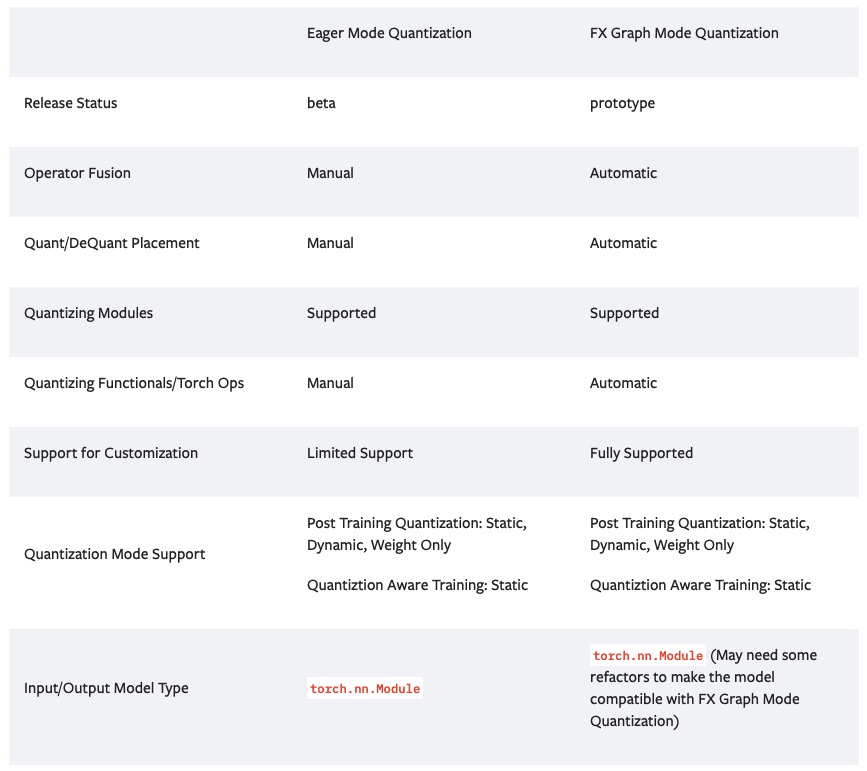
我总结一下这张图,Eager Mode Quantization 需要手工修改网络代码,并对很多节点进行替换,而 FX Graph Mode Quantization 则大大提高了自动化的能力。
现在就用代码实际对比一下二者的差异。
首先,定义一个简单的网络:
class Net(nn.Module): def __init__(self, num_channels=1): super(Net, self).__init__() self.conv1 = nn.Conv2d(num_channels, 40, 3, 1) self.conv2 = nn.Conv2d(40, 40, 3, 1) self.fc = nn.Linear(5*5*40, 10) def forward(self, x): x = F.relu(self.conv1(x)) x = F.max_pool2d(x, 2, 2) x = F.relu(self.conv2(x)) x = F.max_pool2d(x, 2, 2) x = x.reshape(-1, 5*5*40) x = self.fc(x) return x
这个网络的写法应该是很常见的,结构非常简单。pytorch 这种动态图有一个很好的地方,就是可以在 forward 函数中天马星空构造「电路图」,比如 Functional 这些函数模块可以随意调用,而不需要在 init 函数里面事先定义,再比如可以随时加入 if、for 等逻辑控制语句。这就是动态图区别于静态图的地方。但这种好处的代价就是,我们很难获取网络的图结构。
下面我们就看看 Eager 模式下的量化怎么操作。
看过我之前量化系列教程的读者应该知道,模型量化需要在原网络节点中插入一些伪量化节点,或者把一些 Module 或者 Function 替换成量化的形式。对于 Eager 模式,由于它只会对 init 函数里面定义的模块进行替换,因此,如果有一些 op 没有在 init 中定义,但又在 forward 中用到了(比如上面代码的 F.relu),那就凉凉了。
因此,上面这段网络代码是没法直接用 Eager 模式量化的,需要重新写成下面这种形式:
class NetQuant(nn.Module): def __init__(self, num_channels=1): super(NetQuant, self).__init__() self.conv1 = nn.Conv2d(num_channels, 40, 3, 1) self.relu1 = nn.ReLU() self.pool1 = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(40, 40, 3, 1) self.relu2 = nn.ReLU() self.pool2 = nn.MaxPool2d(2, 2) self.fc = nn.Linear(5*5*40, 10) self.quant = torch.quantization.QuantStub() self.dequant = torch.quantization.DeQuantStub() def forward(self, x): x = self.quant(x) x = self.relu1(self.conv1(x)) x = self.pool1(x) x = self.relu2(self.conv2(x)) x = self.pool2(x) x = x.reshape(-1, 5*5*40) x = self.fc(x) x = self.dequant(x) return x
这样一来,除了 Conv、Linear 这些含有参数的 Module 外,ReLU、MaxPool2d 也在 init 中定义了,Eager 模式才能进行处理。
这还没完,由于有些节点是要做 fuse 之后才能量化的(比如:Conv + ReLU),因此我们需要手动指定这些层进行合并:
model = NetQuant() model.qconfig = torch.quantization.get_default_qconfig('fbgemm') modules_to_fuse = [['conv1', 'relu1'], ['conv2', 'relu2']] # 指定合并layer的名字 model_fused = torch.quantization.fuse_modules(model, modules_to_fuse) model_prepared = torch.quantization.prepare(model_fused) post_training_quantize(model_prepared, train_loader) # 这一步是做后训练量化 model_int8 = torch.quantization.convert(model_prepared)
这一套流程下来不可谓不繁琐,而且,这只是一个相当简单的网络,遇上复杂的,或者是别人天马行空写完丢给你量化的网络,分分钟可以去世。pytorch 这套设计直接劝退了很多想上手量化的同学,我很早之前看到这些操作也是一点上手的欲望都没有。
那这套新的 Graph 模式的量化又是怎样的呢?
由于 FX 可以自动跟踪 forward 里面的代码,因此它是真正记录了网络里面的每个节点,在 fuse 和动态插入量化节点方面,要比 Eager 模式强太多。还是前面那个模型代码,我们不需要对网络做修改,直接让 FX 帮我们自动修改网络即可:
from torch.quantization import get_default_qconfig, quantize_jit from torch.quantization.quantize_fx import prepare_fx, convert_fx model = Net() qconfig = get_default_qconfig("fbgemm") qconfig_dict = {"": qconfig} model_prepared = prepare_fx(model, qconfig_dict) post_training_quantize(model_prepared, train_loader) # 这一步是做后训练量化 model_int8 = convert_fx(model_prepared)
对比一下前面 Eager 模式的流程,有没有感觉自己又可以了。
目前 FX 这个新工具包还在优化中,很多功能并不完善。比如,如果 forward 代码中出现了 if 和 for 等控制语句,它依然还是解析不了,这个时候就需要你把 if 还有 for 语句手动拆解掉。但相比起之前的流程,已经是一个巨大的进步了。而且,有了这个图结构,很多后训练量化的算法也可以更加方便的操作(很多 PTQ 的算法需要针对针对网络的拓扑结构优化)。除此以外,像 NAS 等模型结构搜索之类的算法,也可以更加方便的进行。
总的来说,pytorch 推出的这个新特性实在是极大弥补了动态图的先天不足。之前一直考虑针对 pytorch 做一些离线量化的工具,但由于它的图结构很难获取,因此一直难以入手(ONNX 和 jit 这些工具对量化支持又不够)。现在有了 fx,感觉可以加油起飞了。希望官方再接再厉,不要机毁人亡。
欢迎关注我的公众号:大白话AI,立志用大白话讲懂AI。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具