一、why
每当微博爆出大瓜或者是双十一零点的时候,用户请求量是会突然变得超级大的,如果单纯使用 MySQL 来执行一些语句,服务器容易挂掉。因此,不妨使用一种缓存技术,让这些数据去 redis 而不是直接到 MySQL。并且 redis 是缓存到内存中的,能支持超过 10W 次每秒的读写频率。
二、what
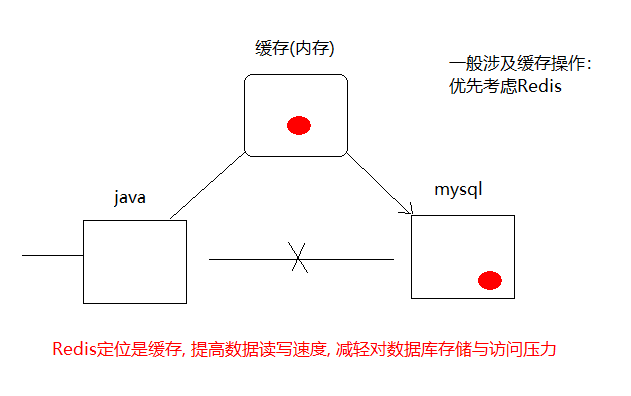
redis 定位是缓存, 提高数据读写速度,减轻对数据库存储与访问压力
Redis简介:
缺点:
Redis是以key-value store存储.
补充知识点:关系型和非关系型数据库的区别
关系型数据库最典型的数据结构是表,由二维表及其之间的联系所组成的一个数据组织
优点:
1、易于维护:都是使用表结构,格式一致;
2、使用方便:SQL语言通用,可用于复杂查询;
3、复杂操作:支持SQL,可用于一个表以及多个表之间非常复杂的查询。
缺点:
1、读写性能比较差,尤其是海量数据的高效率读写;
2、固定的表结构,灵活度稍欠;
3、高并发读写需求,传统关系型数据库来说,硬盘I/O是一个很大的瓶颈。
------------------------------------------------------------------------------------
非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合,可以是文档或者键值对等。
优点:
1、格式灵活:存储数据的格式可以是key,value形式、文档形式、图片形式等等,文档形式、图片形式等等,使用灵活,应用场景广泛,而关系型数据库则只支持基础类型。
2、速度快:nosql可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘;
3、高扩展性;
4、成本低:nosql数据库部署简单,基本都是开源软件。
缺点:
1、不提供sql支持,学习和使用成本较高;
2、无事务处理;
3、数据结构相对复杂,复杂查询方面稍欠。
三、how
1、redis 的安装
先去官网下载 Redis-x64-3.2.100.msi, Windows 系统可用
傻瓜式安装,一直点下一步就可以了
Redis默认端口是: 6379
安装好后会自动启动服务器,并且没有密码
进入到安装目录下,使用 cmd 命令行运行 redis-cli.exe 程序,出现运行界面表示安装成功
2、数据类型及应用场景
Redis命令格式: 类型命令 key 参数数据
key 都为 String 类型,以下列举的都是指 value
1. String类型
介绍
String类型包含多种类型的特殊类型,并且是二进制安全的,比如序列化的对象进行存储,比如一张图片进行二进制存储
应用场景
计数器:许多运用都会使用redis作为计数的基础工具,他可以实现快速计数、查询缓存的功能,同时数据可以异步落地到其他的数据源。
共享session:出于负载均衡的考虑,分布式服务会将用户信息的访问均衡到不同服务器上,用户刷新一次访问可能会需要重新登录,为避免这个问题可以用redis将用户session集中管理,在这种模式下只要保证redis的高可用和扩展性的,每次获取用户更新或查询登录信息都直接从redis中集中获取。
set key value -> 存入键值对
get key -> 根据键取出值
incr key -> 把值递增1
decr key -> 把值递减1
del key -> 根据键删除键值对
setex key timeout value -> 存入键值对,timeout表示失效时间,单位s
ttl key->可以查询出当前的key还剩余多长时间过期
setnx key value -> 如果key已经存在,不做操作, 如果key不存在,直接添加
2. hash类型
介绍
Hash 类型是 String 类型的 field 和 value 的映射表,或者说是一个 String 集合。它特别适合存储对象,相比较而言,将一个对象存储在 Hash 类型里要比存储在 String 类型里占用更少的内存空间,并方便存储整个对象
应用场景用户信息 等管理,但是哈希类型和关系型数据库有所不同,哈希类型是稀疏的,而关系型数据库是完全结构化的,关系型数据库可以做复杂的关系查询,而redis去模拟关系型复杂查询开发困难,维护成本高
--------------------------------------------------------------------------------------------------------
共享session:
key:user_token
value:
class User{
private String userame;
private String password;
private int age;
}
user("dafei", "666", 18)
-------------------------------------
方案1: 将user对象转换json格式字符串存redis 【侧重于查, 改非常麻烦】
key value
----------------------------------------------
user_token : "{name:dafei, age:19, password:666}"
方案2: 将user对象转换hash对象存redis【侧重于改,查询相对麻烦】
key value
---------------------------------------------
user_token : {
name:ddafei
age 19
password: 666
}
API
hset key hashkey hashvalue -> 存入一个hash对象
hget key hashkey -> 根据hash对象键取去值
hexists key hashkey -> 判断hash对象是含有某个键
hdel key hashkey -> 根据hashkey删除hash对象键值对
3. list类型
介绍
Redis 中的 List 类似 Java 中的 queue ,也可以当做 List 来用。
应用场景
用户收藏文章列表:xxxx_user_articles:uid [aid1, aid2, aid3.....]
lrange key start end -> 范围显示列表数据,全显示则设置0 -1
rpush key value -> 往列表右边添加数据
lpush key value -> 往列表左边添加数据
lpop key -> 弹出列表最左边的数据
rpop key -> 弹出列表最右边的数据
llen key -> 获取列表长度
4. set类型
介绍
Set 集合是 string 类型的无序集合,set 是通过 hashtable 实现的,对集合我们可以取交集、并集、差集。
应用场景
1.准备一个抽奖池:sadd luckydraw 1 2 3 4 5 6 7 8 9 10 11 12 13
2.抽3个三等奖:spop luckydraw 3
3.抽2个二等奖:spop luckydraw 2
4.抽1个二等奖:spop luckydraw 1
API
sadd key value -> 往set集合中添加元素
smembers key -> 列出set集合中的元素
srem key value -> 删除set集合中的元素
spop key count -> 随机弹出集合中的元素
sdiff key1 key2 -> 返回key1中特有元素(差集)
sinter key1 key2 -> 返回两个set集合的交集
sunion key1 key2 -> 返回两个set集合的并集
scard key -> 返回set集合中元素个数
5. sorted_set类型
排行榜、排序的场景该类型很好用
排行榜:有序集合经典使用场景。例如视频网站需要对用户上传的视频做排行榜,榜单维护可能是多方面:按照时间、按照播放量、按照获得的赞数等。
zadd key score column -> 存入分数和名称
zincrby key score column -> 偏移名称对应的分数
zrange key start end -> 按照分数升序输出名称
zrevrange key start end -> 按照分数降序输出名称
zrank key name -> 升序返回排名
zrevrank key name -> 降序返回排名
zcard key -> 返回元素个数
6. 小结
6-1: 使用哪个数据类型
1>如果要排序选用zset
JSON.toJsonString(map)
有些公司约定: 所有的redis的key跟value都使用字符串(排除使用zset场景) 【偏redis String类型json结构】
优点: java操作中如果使用各种类型: list set 其他的 操作redis时需要明确指定的泛型,麻烦。所以有些公司统一规范, 统一使用字符串,减少泛型操作。
Listlist = ... set = ....
List list = redis对象.getList set =redis对象.getSet
6-2:怎么设计 key 与 value值
key的设计
value值
3、redis 进阶
1. redis高级命令
返回满足的所有键 keys * (可以模糊查询)
exists 是否存在指定key
expire 设置某个key的过期时间.使用ttl查看剩余时间
persist 取消过期时间
dbsize 查看数据库的key数量
(慎用!)flushdb 清空当前数据库(慎用!!!!)
2. redis安全性
因为 redis 速度非常快,所以在一台比较好的服务器下,一个外部用户在一秒内可以进行15w次的密码尝试,这意味你需要设定非常强大的密码来方式暴力破解.
vi编辑redis.conf文件,找到下面进行保存修改
requirepass [密码]
重启服务器 pkill redis-server
再次进入127.0.01:6379>keys *
(error)NOAUTH Authentication required.
会发现没有权限进行查询auth [密码]
输入密码则成功进入
每次进入的时候都需要输入免密,还有种简单的方式:
redis-cli -a [密码]
3. redis事务
Redis的事务非常简单,使用方法如下:
首先是使用multi方法打开事务;
然后进行设置,这时设置的数据会放到队列里进行保存;
最后使用exec执行.把数据依次存储到redis中.使用discard方法取消事务
Redis 事务可以一次执行多个命令, 并且带有以下三个重要的保证:
- 批量操作在发送 EXEC 命令前被放入队列缓存。
- 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行。
- 在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中。
一个事务从开始到执行会经历以下三个阶段:
- 开始事务。
- 命令入队。
- 执行事务。
- 以下是一个事务的例子, 它先以 **MULTI** 开始一个事务, 然后将多个命令入队到事务中, 最后由 **EXEC** 命令触发事务, 一并执行事务中的所有命令:
---------------------------------------------------------------
redis 127.0.0.1:6379> MULTI
OK
redis 127.0.0.1:6379> SET book-name "Mastering C++ in 21 days"
QUEUED
redis 127.0.0.1:6379> GET book-name
QUEUED
redis 127.0.0.1:6379> SADD tag "C++" "Programming" "Mastering Series"
QUEUED
redis 127.0.0.1:6379> SMEMBERS tag
QUEUED
redis 127.0.0.1:6379> EXEC
1) OK
2) "Mastering C++ in 21 days"
3) (integer) 3
4) 1) "Mastering Series"
2) "C++"
3) "Programming"
---------------------------------------------------------------
单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
比如:
---------------------------------------------------------------
redis 127.0.0.1:7000> multi
OK
redis 127.0.0.1:7000> set a aaa
QUEUED
redis 127.0.0.1:7000> set b bbb
QUEUED
redis 127.0.0.1:7000> set c ccc
QUEUED
redis 127.0.0.1:7000> exec
1) OK
2) OK
3) OK
---------------------------------------------------------------
如果在 set b bbb 处失败,set a 已成功不会回滚,set c 还会继续执行。
4. redis持久化机制( 重点掌握 )
Redis是一个支持持久化的内存数据库,也就是说redis需要经常将内存中中的数据同步到硬盘来保证持久化.
Redis持久化的两种方式:
一.RDB方式
snapshotting(快照)默认方式.将内存中以快照的方式写入到二进制文件中.默认为dump.rdb.可以配置设置自动做快照持久化方式.我们可以配置redis在n秒内如果超过m个key就修改自动做快照.
Snapshotting设置:
save 900 1 #900秒内如果超过1个Key被修改则发起快照保存
save 300 10 #300秒内如果超过10个key被修改,则发起快照保存
save 60 10000
-----------------------------------------------------
AOF方式
append-only file (缩写aof)的方式,由于快照方式是在一定时间间隔做一次,所以可能发生reids意外down的情况就会丢失最后一次快照后的所有修改的数据.aof比快照方式有更好的持久化性,是由于在使用aof时,redis会将每一个收到的写命令都通过write函数追加到命令中,当redis重新启动时会重新执行文件中保存的写命令来在内存中重建这个数据库的内容.这个文件在bin目录下:appendonly.aof
aof不是立即写到硬盘中,可以通过配置文件修改强制写到硬盘中.
aof设置:
appendonly yes //启动aof持久化方式有三种修改方式
#appendfsync always//收到命令就立即写到磁盘,效率最慢.但是能保证完全的持久化
#appendfsync everysec//每秒写入磁盘一次,在性能和持久化方面做了很好的折中
#appendfsync no //完全以依赖os 性能最好,持久化没保证
5. Redis内存淘汰机制及过期Key处理
参考:https://www.cnblogs.com/maguanyue/p/12090414.html
------------------------------------------------------------
Redis内存淘汰机制及过期Key处理
“天长地久有时尽,此恨绵绵无绝期。”好诗!好诗啊!即使是天长地久,也总会有尽头,那么,Redis的内存是不是也会有时尽呢?答案是肯定的。那么,当Redis的内存满了以后,再来新的请求,我们该怎么办呢?这时候,大家就应该来了解Redis的内存淘汰策略了,了解了相关的知识点后,就能明白“Redis内存有时尽”后,会发生些什么。
Redis内存淘汰机制
Redis内存淘汰机制是指当内存使用达到上限(可通过maxmemory配置,0为不限制,即服务器内存上限),根据一定的算法来决定淘汰掉哪些数据,以保证新数据的存入。
常见的内存淘汰机制分为四大类:
1. LRU:LRU是Least recently used,最近最少使用的意思,简单的理解就是从数据库中删除最近最少访问的数据,该算法认为,你长期不用的数据,那么被再次访问的概率也就很小了,淘汰的数据为最长时间没有被使用,仅与时间相关。
2. LFU:LFU是Least Frequently Used,最不经常使用的意思,简单的理解就是淘汰一段时间内,使用次数最少的数据,这个与频次和时间相关。
3. TTL:Redis中,有的数据是设置了过期时间的,而设置了过期时间的这部分数据,就是该算法要解决的对象。如果你快过期了,不好意思,我内存现在不够了,反正你也要退休了,提前送你一程,把你干掉吧。
4. 随机淘汰:生死有命,富贵在天,是否被干掉,全凭天意了。
通过maxmemroy-policy可以配置具体的淘汰机制,看了网上很多文章说只有6种,其实有8种,可以看Redis5.0的配置文件,上面有说明:
1. volatile-lru -> 找出已经设置过期时间的数据集,将最近最少使用(被访问到)的数据干掉。
2. volatile-ttl -> 找出已经设置过期时间的数据集,将即将过期的数据干掉。
3. volatile-random -> 找出已经设置过期时间的数据集,进行无差别攻击,随机干掉数据。
4. volatile-lfu -> 找出已经设置过期时间的数据集,将一段时间内,使用次数最少的数据干掉。
5. allkeys-lru ->与第1个差不多,数据集从设置过期时间数据变为全体数据。
6. allkeys-lfu -> 与第4个差不多,数据集从设置过期时间数据变为全体数据。
7. allkeys-random -> 与第3个差不多,数据集从设置过期时间数据变为全体数据。
8. no-enviction -> 什么都不干,报错,告诉你内存不足,这样的好处是可以保证数据不丢失,这也是系统默认的淘汰策略。
Redis过期Key清除策略
Redis中大家会对存入的数据设置过期时间,那么这些数据如果过期了,Redis是怎么样把他们消灭掉的呢?我们一起来探讨一下。下面介绍三种清除策略:
惰性删除:当访问Key时,才去判断它是否过期,如果过期,直接干掉。这种方式对CPU很友好,但是一个key如果长期不用,一直存在内存里,会造成内存浪费。
定时删除:设置键的过期时间的同时,创建一个定时器,当到达过期时间点,立即执行对Key的删除操作,这种方式最不友好。
定期删除:隔一段时间,对数据进行一次检查,删除里面的过期Key,至于要删除多少过期Key,检查多少数据,则由算法决定。举个例子方便大家理解:Redis每秒随机取100个数据进行过期检查,删除检查数据中所有已经过期的Key,如果过期的Key占比大于总数的25%,也就是超过25个,再重复上述检查操作。
Redis服务器实际使用的是惰性删除和定期删除两种策略:通过配合使用这两种删除策略,可以很好地在合理使用CPU和避免浪费内存之间取得平衡。
4、Jedis 的使用
添加依赖
<dependency>
<groupid>redis.clients</groupid>
<artifactid>jedis</artifactid>
</dependency>
普通 API
jedis 的 api 和 redis 操作命令一致,直接调用即可。
@Test
public void testJedisPool() {
// 1:创建Jedis连接池
JedisPool pool = new JedisPool("localhost", 6379);
// 2:从连接池中获取Jedis对象
Jedis jedis = pool.getResource();
/* 设置密码
jedis.auth(密码); */
// 3:TODO
System.out.println(jedis); // 这里可以jedis.xxx调用命名
// 4:关闭资源
jedis.close();
pool.destroy();
}
@Test
public void testTool(){
GenericObjectPoolConfig config = new GenericObjectPoolConfig();
//最大连接数, 默认8个
config.setMaxTotal(100);
//最大空闲连接数, 默认8个
config.setMaxIdle(20);
//获取连接时的最大等待毫秒数(如果设置为阻塞时BlockWhenExhausted),如果超时就抛异常, 小于零:阻塞不确定的时间, 默认-1
config.setMaxWaitMillis(-1);
//在获取连接的时候检查有效性, 默认false
config.setTestOnBorrow(true);
JedisPool pool = new JedisPool(config,"192.168.122.128",6379,5000,"wolfcode");
Jedis j = pool.getResource();
String name = j.get("name");
System.out.println(name);
j.close();
pool.close();
pool.destroy();
}
5、集成 SpringBoot
添加依赖
<parent>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-parent</artifactid>
<version>2.4.3</version>
<relativepath>
</relativepath></parent>
<dependencies>
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-web</artifactid>
</dependency>
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-data-redis</artifactid>
</dependency>
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter</artifactid>
</dependency>
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-test</artifactid>
<scope>test</scope>
</dependency>
</dependencies>
application.properties 添加配置
#application.properties
spring.redis.host=127.0.0.1
spring.redis.port=6379
#如果设置了密码需要加上
#spring.redis.password=admin
注入
@Autowired
private StringRedisTemplate redisTemplate;
对应数据类型
String-------opsForValue()
/**
* 操作String
*/
@Test
public void testRedisTemplateString() throws InterruptedException {
// set key value -> 存入键值对
redisTemplate.opsForValue().set("name", "fei");
// get key -> 根据键取出值
System.out.println(redisTemplate.opsForValue().get("name"));
redisTemplate.opsForValue().set("age", "20");
// incr key -> 把值递增1
redisTemplate.opsForValue().increment("age");
// decr key -> 把值递减1
redisTemplate.opsForValue().decrement("age");
// del key -> 根据键删除键值对
redisTemplate.delete("age");
System.out.println("-------删除了 key->age -------");
System.out.println("获取 age,它的vlue为 " + redisTemplate.opsForValue().get("age"));
// setex key timeout value -> 存入键值对,timeout表示失效时间,单位s
redisTemplate.opsForValue().set("time", "timeout", 10, TimeUnit.SECONDS);
// ttl key->可以查询出当前的key还剩余多长时间过期
Thread.sleep(3000);
System.out.println(redisTemplate.getExpire("time"));
// setnx key value -> 如果key已经存在,不做操作, 如果key不存在,直接添加
redisTemplate.opsForValue().setIfAbsent("age", "42");
redisTemplate.opsForValue().setIfAbsent("aa", "12");
}
Hash-------opsForHash()
/**
* 操作 Hash
*/
@Test
public void testRedisTemplateHash() {
// hset key hashkey hashvalue -> 存入一个hash对象
HashMap map = new HashMap();
map.put("name", "fei");
redisTemplate.opsForHash().putAll("user", map);
// hget key hashkey -> 根据hash对象键取去值
System.out.println(redisTemplate.opsForHash().get("user", "name"));
// hexists key hashkey -> 判断hash对象是含有某个键
System.out.println(redisTemplate.opsForHash().hasKey("user", "name"));
System.out.println(redisTemplate.opsForHash().hasKey("user", "age"));
// hdel key hashkey -> 根据hashkey删除hash对象键值对
redisTemplate.opsForHash().delete("user", "name");
System.out.println("--删除了name---" + redisTemplate.opsForHash().get("user", "name"));
}
List-------opsForList()
/**
* 操作 list
*/
@Test
public void testRedisTemplateList() {
// rpush key value -> 往列表右边添加数据
redisTemplate.opsForList().leftPush("apple", "1");
redisTemplate.opsForList().leftPush("apple", "2");
redisTemplate.opsForList().leftPush("apple", "3");
// lrange key start end -> 范围显示列表数据,全显示则设置0 -1
redisTemplate.opsForList().range("apple", 0, -1).forEach(System.err::println);
// lpush key value -> 往列表左边添加数据
redisTemplate.opsForList().rightPush("apple", "a");
System.out.println("------------往列表左边添加数据--------------");
redisTemplate.opsForList().range("apple", 0, -1).forEach(System.err::println);
// lpop key -> 弹出列表最左边的数据
redisTemplate.opsForList().leftPop("apple");
System.out.println("------------弹出列表最左边的数据--------------");
redisTemplate.opsForList().range("apple", 0, -1).forEach(System.err::println);
// rpop key -> 弹出列表最右边的数据
redisTemplate.opsForList().rightPop("apple");
System.out.println("-------------弹出列表最右边的数据-------------");
redisTemplate.opsForList().range("apple", 0, -1).forEach(System.err::println);
// llen key -> 获取列表长度
System.out.println("获取列表长度:" + redisTemplate.opsForList().size("apple"));
}
Set-------opsForSet()
/**
* 操作 set
*/
@Test
public void testRedisTemplateSet() {
// sadd key value -> 往set集合中添加元素
redisTemplate.opsForSet().add("user", "aa", "bb", "cc", "ee");
redisTemplate.opsForSet().add("user2", "aa", "DD", "FF");
// smembers key -> 列出set集合中的元素
redisTemplate.opsForSet().members("user").forEach(System.err::println);
// srem key value -> 删除set集合中的元素
redisTemplate.opsForSet();
System.out.println("---------- 删除set集合中的元素-----------");
redisTemplate.opsForSet().members("user").forEach(System.err::println);
// spop key count -> 随机弹出集合中的元素
System.out.println("随机弹出集合中的元素:" + redisTemplate.opsForSet().pop("user"));
// sdiff key1 key2 -> 返回key1中特有元素(差集)
System.out.println("返回key1中特有元素(差集): " + redisTemplate.opsForSet().difference("user", "user2"));
// sinter key1 key2 -> 返回两个set集合的交集
System.out.println("返回两个set集合的交集 :" + redisTemplate.opsForSet().intersect("user2", "user"));
// sunion key1 key2 -> 返回两个set集合的并集
System.out.println("返回两个set集合的并集 :" + redisTemplate.opsForSet().union("user2", "user"));
// scard key -> 返回set集合中元素个数
System.out.println("返回set集合user中元素个数:" + redisTemplate.opsForSet().size("user"));
}
sorted_set-------opsForZSet()
/**
* 操作 zset
*/
@Test
public void testRedisTemplateZSet() {
// zadd key score column -> 存入分数和名称
redisTemplate.opsForZSet().add("player", "p1", 100);
redisTemplate.opsForZSet().add("player", "p2", 100);
redisTemplate.opsForZSet().add("player", "p3", 100);
redisTemplate.opsForZSet().add("player", "p4", 100);
// zincrby key score column -> 偏移名称对应的分数
redisTemplate.opsForZSet().incrementScore("player", "p2", 500);
// zrange key start end -> 按照分数升序输出名称
System.out.println(redisTemplate.opsForZSet().range("player", 0, -1));
// zrevrange key start end -> 按照分数降序输出名称
Set<zsetoperations.typedtuple<string>> playerSet = redisTemplate.opsForZSet().reverseRangeWithScores("player", 0, -1);
Iterator<zsetoperations.typedtuple<string>> iterator = playerSet.iterator();
while (iterator.hasNext()) {
ZSetOperations.TypedTuple<string> typedTuple = iterator.next();
Object value = typedTuple.getValue();
double score = typedTuple.getScore();
System.out.println("名称:" + value + " 分数" + score );
}
// zrank key name -> 升序返回排名
System.out.println(redisTemplate.opsForZSet().rank("player", "p2"));
// zrevrank key name -> 降序返回排名
System.out.println(redisTemplate.opsForZSet().reverseRank("player", "p2"));
// zcard key -> 返回元素个数
System.out.println(redisTemplate.opsForZSet().size("player"));
}
6、demo_文章阅读数统计
需求:页面每访问一次(相当于刷新一次),页面显示的 “阅读数:1” 需要 +1 展示
思路:刷新 --------->>页面加载完毕,前端页面发出异步请求,获取阅读数,然后通过 jQuery 语法获取 “阅读数”标签id,调用 .html() 把后端返回的 data 作为参数放进去。后端写接口,实现类调用 redisTemplate.opsForValue().increment,并把返回值返回即可
实现:
阅读数: <span id="articleId" style="color: hotpink">0</span> <br>
<script>
$(function () {
$.get("/articles/detail",{id:"articleId"},function (id) {
$("#articleId").html(id)
})
})
</script>
@RestController
@RequestMapping("articles")
public class ArticleController {
@Autowired
private IArticleService articleService;
@GetMapping("/detail")
public Object detail(String id){
return articleService.selectById(id);
}
}
// 实现类
@Override
public Object selectById(String id) {
return redisTemplate.opsForValue().increment("aiticle:" + id);
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号