SQL Server ->> 分析函数 PERCENTILE_DISC \PERCENT_RANK \PERCENTILE_CONT \CUME_DIST \LAST_VALUE \FIRST_VALUE \LAG \LEAD
先建个成绩表作为测试数据


CREATE TABLE dbo.score ( [class] nvarchar(10), [student] nvarchar(10), [subject_name] nvarchar(10), [score] decimal(4,1) ) INSERT INTO dbo.score VALUES ( N'高一4班', N'马云', N'语文', 92.0 ), ( N'高一4班', N'马云', N'数学', 98.0 ), ( N'高一4班', N'马云', N'英语', 94.0 ), ( N'高一4班', N'马云', N'政治', 95.0 ), ( N'高一4班', N'马云', N'历史', 92.0 ), ( N'高一4班', N'马云', N'物理', 97.0 ), ( N'高一4班', N'马云', N'化学', 100.0 ), ( N'高一4班', N'马云', N'地理', 100.0 ), ( N'高一4班', N'马云', N'生物', 93.0 ), ( N'高一4班', N'马化腾', N'语文', 98.0 ), ( N'高一4班', N'马化腾', N'数学', 99.0 ), ( N'高一4班', N'马化腾', N'英语', 93.0 ), ( N'高一4班', N'马化腾', N'政治', 100.0 ), ( N'高一4班', N'马化腾', N'历史', 95.0 ), ( N'高一4班', N'马化腾', N'物理', 96.0 ), ( N'高一4班', N'马化腾', N'化学', 94.0 ), ( N'高一4班', N'马化腾', N'地理', 95.0 ), ( N'高一4班', N'马化腾', N'生物', 98.0 ), ( N'高一4班', N'李彦宏', N'语文', 93.0 ), ( N'高一4班', N'李彦宏', N'数学', 96.0 ), ( N'高一4班', N'李彦宏', N'英语', 92.0 ), ( N'高一4班', N'李彦宏', N'政治', 92.0 ), ( N'高一4班', N'李彦宏', N'历史', 100.0 ), ( N'高一4班', N'李彦宏', N'物理', 94.0 ), ( N'高一4班', N'李彦宏', N'化学', 97.0 ), ( N'高一4班', N'李彦宏', N'地理', 92.0 ), ( N'高一4班', N'李彦宏', N'生物', 99.0 ), ( N'高一4班', N'王思聪', N'语文', 98.0 ), ( N'高一4班', N'王思聪', N'数学', 95.0 ), ( N'高一4班', N'王思聪', N'英语', 92.0 ), ( N'高一4班', N'王思聪', N'政治', 100.0 ), ( N'高一4班', N'王思聪', N'历史', 94.0 ), ( N'高一4班', N'王思聪', N'物理', 97.0 ), ( N'高一4班', N'王思聪', N'化学', 96.0 ), ( N'高一4班', N'王思聪', N'地理', 98.0 ), ( N'高一4班', N'王思聪', N'生物', 96.0 ), ( N'高一4班', N'张一鸣', N'语文', 97.0 ), ( N'高一4班', N'张一鸣', N'数学', 99.0 ), ( N'高一4班', N'张一鸣', N'英语', 96.0 ), ( N'高一4班', N'张一鸣', N'政治', 100.0 ), ( N'高一4班', N'张一鸣', N'历史', 97.0 ), ( N'高一4班', N'张一鸣', N'物理', 95.0 ), ( N'高一4班', N'张一鸣', N'化学', 91.0 ), ( N'高一4班', N'张一鸣', N'地理', 94.0 ), ( N'高一4班', N'张一鸣', N'生物', 98.0 ), ( N'高一4班', N'王兴', N'语文', 100.0 ), ( N'高一4班', N'王兴', N'数学', 95.0 ), ( N'高一4班', N'王兴', N'英语', 96.0 ), ( N'高一4班', N'王兴', N'政治', 92.0 ), ( N'高一4班', N'王兴', N'历史', 99.0 ), ( N'高一4班', N'王兴', N'物理', 97.0 ), ( N'高一4班', N'王兴', N'化学', 100.0 ), ( N'高一4班', N'王兴', N'地理', 95.0 ), ( N'高一4班', N'王兴', N'生物', 98.0 ), ( N'高一4班', N'刘强东', N'语文', 93.0 ), ( N'高一4班', N'刘强东', N'数学', 96.0 ), ( N'高一4班', N'刘强东', N'英语', 96.0 ), ( N'高一4班', N'刘强东', N'政治', 98.0 ), ( N'高一4班', N'刘强东', N'历史', 96.0 ), ( N'高一4班', N'刘强东', N'物理', 97.0 ), ( N'高一4班', N'刘强东', N'化学', 97.0 ), ( N'高一4班', N'刘强东', N'地理', 94.0 ), ( N'高一4班', N'刘强东', N'生物', 98.0 ), ( N'高一4班', N'黄铮', N'语文', 94.0 ), ( N'高一4班', N'黄铮', N'数学', 91.0 ), ( N'高一4班', N'黄铮', N'英语', 92.0 ), ( N'高一4班', N'黄铮', N'政治', 100.0 ), ( N'高一4班', N'黄铮', N'历史', 92.0 ), ( N'高一4班', N'黄铮', N'物理', 93.0 ), ( N'高一4班', N'黄铮', N'化学', 91.0 ), ( N'高一4班', N'黄铮', N'地理', 97.0 ), ( N'高一4班', N'黄铮', N'生物', 100.0 ), ( N'高一4班', N'丁磊', N'语文', 98.0 ), ( N'高一4班', N'丁磊', N'数学', 95.0 ), ( N'高一4班', N'丁磊', N'英语', 95.0 ), ( N'高一4班', N'丁磊', N'政治', 95.0 ), ( N'高一4班', N'丁磊', N'历史', 91.0 ), ( N'高一4班', N'丁磊', N'物理', 96.0 ), ( N'高一4班', N'丁磊', N'化学', 100.0 ), ( N'高一4班', N'丁磊', N'地理', 94.0 ), ( N'高一4班', N'丁磊', N'生物', 98.0 ), ( N'高一4班', N'雷军', N'语文', 100.0 ), ( N'高一4班', N'雷军', N'数学', 92.0 ), ( N'高一4班', N'雷军', N'英语', 98.0 ), ( N'高一4班', N'雷军', N'政治', 95.0 ), ( N'高一4班', N'雷军', N'历史', 94.0 ), ( N'高一4班', N'雷军', N'物理', 99.0 ), ( N'高一4班', N'雷军', N'化学', 97.0 ), ( N'高一4班', N'雷军', N'地理', 96.0 ), ( N'高一4班', N'雷军', N'生物', 96.0 ), ( N'高一4班', N'周鸿祎', N'语文', 91.0 ), ( N'高一4班', N'周鸿祎', N'数学', 94.0 ), ( N'高一4班', N'周鸿祎', N'英语', 96.0 ), ( N'高一4班', N'周鸿祎', N'政治', 99.0 ), ( N'高一4班', N'周鸿祎', N'历史', 93.0 ), ( N'高一4班', N'周鸿祎', N'物理', 99.0 ), ( N'高一4班', N'周鸿祎', N'化学', 93.0 ), ( N'高一4班', N'周鸿祎', N'地理', 100.0 ), ( N'高一4班', N'周鸿祎', N'生物', 99.0 ), ( N'高一4班', N'张朝阳', N'语文', 95.0 ), ( N'高一4班', N'张朝阳', N'数学', 95.0 ), ( N'高一4班', N'张朝阳', N'英语', 94.0 ), ( N'高一4班', N'张朝阳', N'政治', 95.0 ), ( N'高一4班', N'张朝阳', N'历史', 98.0 ), ( N'高一4班', N'张朝阳', N'物理', 93.0 ), ( N'高一4班', N'张朝阳', N'化学', 94.0 ), ( N'高一4班', N'张朝阳', N'地理', 94.0 ), ( N'高一4班', N'张朝阳', N'生物', 91.0 ), ( N'高一4班', N'俞敏洪', N'语文', 91.0 ), ( N'高一4班', N'俞敏洪', N'数学', 95.0 ), ( N'高一4班', N'俞敏洪', N'英语', 100.0 ), ( N'高一4班', N'俞敏洪', N'政治', 99.0 ), ( N'高一4班', N'俞敏洪', N'历史', 91.0 ), ( N'高一4班', N'俞敏洪', N'物理', 97.0 ), ( N'高一4班', N'俞敏洪', N'化学', 93.0 ), ( N'高一4班', N'俞敏洪', N'地理', 93.0 ), ( N'高一4班', N'俞敏洪', N'生物', 94.0 ), ( N'高一4班', N'张磊', N'语文', 99.0 ), ( N'高一4班', N'张磊', N'数学', 99.0 ), ( N'高一4班', N'张磊', N'英语', 92.0 ), ( N'高一4班', N'张磊', N'政治', 98.0 ), ( N'高一4班', N'张磊', N'历史', 97.0 ), ( N'高一4班', N'张磊', N'物理', 99.0 ), ( N'高一4班', N'张磊', N'化学', 100.0 ), ( N'高一4班', N'张磊', N'地理', 91.0 ), ( N'高一4班', N'张磊', N'生物', 100.0 ), ( N'高一4班', N'沈南鹏', N'语文', 96.0 ), ( N'高一4班', N'沈南鹏', N'数学', 92.0 ), ( N'高一4班', N'沈南鹏', N'英语', 93.0 ), ( N'高一4班', N'沈南鹏', N'政治', 91.0 ), ( N'高一4班', N'沈南鹏', N'历史', 94.0 ), ( N'高一4班', N'沈南鹏', N'物理', 100.0 ), ( N'高一4班', N'沈南鹏', N'化学', 95.0 ), ( N'高一4班', N'沈南鹏', N'地理', 91.0 ), ( N'高一4班', N'沈南鹏', N'生物', 97.0 )
百分位数:PERCENTILE_DIST 和 PERCENTILE_CONT
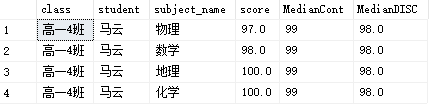
PERCENTILE_DIST:计算当前列值在经过排序后的结果集的给定百分位数,输出值是列值中的一个。DIST是discrete离散的意思,就是经过离散分布后的百分位数。这里我还是搞不懂,既然百分位是要求ORDER BY 列排序后找出给定的百分位的列值,那离散不离散有什么意义?反正都是要经过排序,那不就是连续了吗?反正经过测试,它和PERCENTILE_CONT区别就是,PERCENTILE_DIST是返回列的某个值,而PERCENTILE_CONT不一定。而在结果集行数是偶数的情况下,中位数到底是取上边界还是下边界,好像都是上边界。
PERCENTILE_CONT:计算当前列值在经过排序后的结果集的给定百分位数,输出值可能不是列值。CONT是continuous连续的意思,就是经过连续分布后的百分位数。
SELECT [class] ,[student] ,[subject_name] ,[score] ,PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY [score]) OVER (PARTITION BY [student]) AS MedianCont ,PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY [score]) OVER (PARTITION BY [student]) AS MedianDISC FROM [dbo].[score] WHERE [student] IN ('马云') AND [subject_name] IN ( '数学', '化学', '地理', '物理' ) ORDER BY [score] ASC,[subject_name]
结果
百分比值:CUMU_DIST 和 PERCENT_RANK
CUMU_DIST:计算当前行的排序列值在整个列值中的累计分布,即:低于/高于(排序规则ASC/DESC)或等于当前排序列值的数量占比(注意这里值重复情况下不去重)。 计算公式=低于或等于行 r 的值的行数除以在分区或查询结果集中求出的行数
PERCENT_RANK:计算当前行的排序列值在整个结果集中的相对位置(百分比值)。就是排序后看下当前行的列值排在什么位置,以百分比的形式。第一行是一定是0,NULL值视为最小值。不同行间相同列值返回相同的结果。计算公式=(小于当前值的数量)/(除去当前值外的数量总数)。其实PERCENT_RANK理解起来就是,想象所有值代表一个容器,最大值是最高水位,最小值就是容器底部,PERCENT_RANK就是当前值在容器中的水位(或者说当前水位线占整个容器内水深的百分比)。

SELECT [class] ,[student] ,[subject_name] ,[score] ,CUME_DIST() OVER (PARTITION BY [student] ORDER BY [score] ) AS CUME_DIST ,1.*(COUNT(*) OVER (PARTITION BY [student] ORDER BY [score]))/COUNT(*) OVER (PARTITION BY [student]) ,PERCENT_RANK() OVER (PARTITION BY [student] ORDER BY [score] ) AS PERCENT_RANK ,1.*(RANK() OVER(PARTITION BY [student] ORDER BY [score] )-1)/(COUNT(*) OVER (PARTITION BY [student])-1) FROM [dbo].[score] WHERE [student] IN ('马云') AND [subject_name] IN ( '数学', '化学', '地理', '物理', '语文', '历史', '英语', '生物' ) ORDER BY [score] DESC
结果
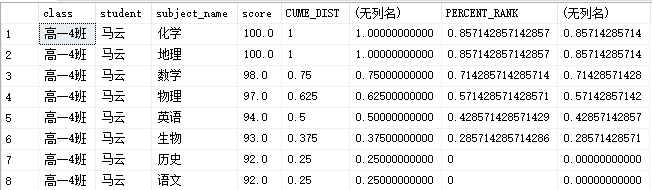
虽然结果都是浮点型百分比的输出结果,但是CUMU_DIST理解起来更像是元素区块的占比,而PERCENT_DIST理解起来更像是水位线。
排序取值函数:LAST_VALUE 和 FIRST_VALUE
都是排序后取值,区别是FIRST_VALUE是取首行的列值,LAST_VALUE是取末尾行的列值,两个函数都要求指定ORDER BY子句。但是排序的规则决定了两者取出来的值是有很大区别的。因为两个都必须是搭配OVER子句使用,意味着ORDER BY后的结果是一个开窗函数后的结果,开窗的窗口大小是随读取行越滚动越大。 FIRST_VALUE+升序=固定值,排序最小行列值;FIRST_VALUE+降序=固定值,排序最大行列值;LAST_VALUE+升序=当前窗口内最大排序行的列值;LAST_VALUE+降序=当前窗口内最小排序行的列值;
SELECT [class] ,[student] ,[subject_name] ,[score] ,FIRST_VALUE([score]) OVER (PARTITION BY [student] ORDER BY [score] ASC) AS FIRST_VALUE_SORT_BY_SCORE_ASC ,LAST_VALUE([score]) OVER (PARTITION BY [student] ORDER BY [score] ASC) AS LAST_VALUE_SORT_BY_SCORE_ASC ,FIRST_VALUE([score]) OVER (PARTITION BY [student] ORDER BY [score] DESC) AS FIRST_VALUE_SORT_BY_SCORE_DESC ,LAST_VALUE([score]) OVER (PARTITION BY [student] ORDER BY [score] DESC) AS LAST_VALUE_SORT_BY_SCORE_DESC FROM [dbo].[score] WHERE [student] IN ('马云') AND [subject_name] IN ( '数学', '化学', '地理', '物理' ) ORDER BY [score] ASC
结果

前后行取值函数:LAG 和 LEAD
LAG英文是下陷的意思,LEAD英文是前面的意思。那么这两个函数理解起来就是,把当前集合基于排序,LAG是下拉X行,LEAD是上提X行,这个X取决于函数中的第二个参数<OFFSET>。LEAD+升序=比当前行排序值大的行的列值,LEAD+降序=比当前行排序值小的行的列值,LAG+升序=比当前行排序值小的行的列值,LAG+降序=比当前行排序值大的行的列值。 OFFSET决定了偏移多少行,第三个参数决定了如果偏移量超出当前集合边界返回的值,DEFAULT=NULL。
SELECT [class] ,[student] ,[subject_name] ,[score] ,LAG ([score]) OVER (PARTITION BY [student] ORDER BY [score] ASC,[subject_name]) LAG_ASC ,LAG ([score]) OVER (PARTITION BY [student] ORDER BY [score] DESC,[subject_name]) LAG_DESC ,LEAD([score]) OVER (PARTITION BY [student] ORDER BY [score] ASC,[subject_name]) LEAD_ASC ,LEAD([score]) OVER (PARTITION BY [student] ORDER BY [score] DESC,[subject_name]) LEAD_DESC ,LAG ([score],2) OVER (PARTITION BY [student] ORDER BY [score] ASC,[subject_name]) LAG_ASC_OFFSET_2 ,LAG ([score],2) OVER (PARTITION BY [student] ORDER BY [score] DESC,[subject_name]) LAG_DESC_OFFSET_2 ,LEAD([score],2) OVER (PARTITION BY [student] ORDER BY [score] ASC,[subject_name]) LEAD_ASC_OFFSET_2 ,LEAD([score],2) OVER (PARTITION BY [student] ORDER BY [score] DESC,[subject_name]) LEAD_DESC_OFFSET_2 FROM [dbo].[score] WHERE [student] IN ('马云') AND [subject_name] IN ( '数学', '化学', '地理', '物理', '历史' ) ORDER BY [score]
结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号