
SQL Server ->> 基于表TIMESTAMP类型字段+NOLOCK脏读的ETL增量同步方案发现的数据遗漏问题
公司有一个数据仓库项目,源到ODS这一层的增量数据同步实现是基于对源数据库表添加TIMESTAMP类型字段,ETL(SSIS包)再基于每次增量同步数据的最大TIMESTAMP值向后读取新更新的数据行,同时允许脏读(表查询加NOLOCK)。这里允许脏读是为了不阻塞源数据库,因为源数据库是生产库。同步作业是每天早上7点开始,8点半结束。
SELECT COL1,COL2,COL3 FROM SOURCE_TABLE1 WHERE TIMESTAMP >= @MAX_TIMESTAMP_LAST_TIME
基于TIMESTAMP类型的ETL增量数据同步方案其实不用多说了,这是SQL SERVER 2000/2005的数据库增量数据同步方案,它的好处是不影响生产系统的代码(select * from source_table是不会把timestamp带出来的,除非timestamp字段的命名跟其他表冲突之类的。),由于SQL SERVER 2008(企业版)开始增加了CDC(change data capture)作为专为ETL而生的数据同步技术,timestamp有了替代方案。
讲了前面的背景,这个方案在实际使用过程中遇到的问题。其实不管是timestamp还是updateTime字段实现的ETL增量同步方案都会遇到一个问题,就是如果锁表读数据又可能堵塞表,如果脏读(查询加NOLOCK提示)又有数据提取遗漏的风险。前者在以往离线数仓场景(T+1)其实也还是可行的,因为一般ETL抽数都是凌晨发生,凌晨时间生产系统基本是不会有什么交易发生,但是对于没办法在凌晨,时间窗口是早上或者压根不存在时间窗口的情况下,锁表抽数据就不太实际了,尤其是每次的增量数据可能比较多的情况下(例如交易数据可能一天就是几十万甚至百万级别的增量)。
我发现的项目里面基于表TIMESTAMP类型字段+NOLOCK脏读的ETL增量同步方案发现的数据遗漏问题的原因就:
1、没有所谓的time window,因为上游其实很多数据也是通过上游的上游API给过来的数据;
2、数据增量抽取的时间设置在早上7点;
3、NOLOCK脏读表,且每次表的增量数据是50-100W数据;
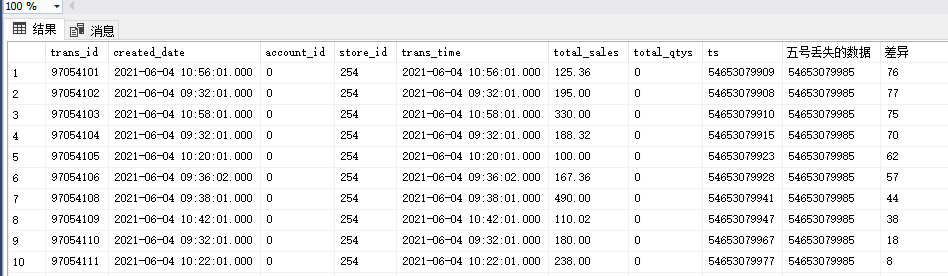
上面三个背景因素直接导致项目的增量同步出现了数据遗漏,我是怎么确定数据遗漏是NOLOCK脏读造成的呢?
我把丢失数据的10行数据行的timestamp跟ETL跑的那天所记录表的最大timestamp发现,恰好两个时间戳(转出bigint)的差异刚好是50左右,这个值转化成秒可以理解为0.1-0.2秒。这恰好验证NOLOCK脏读可能会丢失部分读取进程读完数据后数据才写入数据库造成数据遗漏的风险。
解决方案:
其实像这种问题也很好解决,就是每次做增量同步的时候把SQL WHERE语句的timestamp >= @delta_ts,开始读取的时间戳位置往前偏移一部分,我的经验值是偏移10000的量(这个10000是timestamp转出bigint后的数值)。

