import pandas as pd
datafile= r"D:\Weixin\WeChat Files\wxid_cg9y4qd0yxhb22\FileStorage\File\2023-03\air_data.csv" # 航空原始数据,第一行为属性标签
resultfile = r"C:\Users\86139\Desktop\te\explore.csv" # 数据探索结果表
# 读取原始数据,指定UTF-8编码(需要用文本编辑器将数据装换为UTF-8编码)
data = pd.read_csv(datafile, encoding = 'utf-8')
# 包括对数据的基本描述,percentiles参数是指定计算多少的分位数表(如1/4分位数、中位数等)
explore = data.describe(percentiles = [], include = 'all').T # T是转置,转置后更方便查阅
explore['null'] = len(data)-explore['count'] # describe()函数自动计算非空值数,需要手动计算空值数
explore = explore[['null', 'max', 'min']]
explore.columns = ['空值数', '最大值', '最小值'] # 表头重命名
'''
这里只选取部分探索结果。
describe()函数自动计算的字段有count(非空值数)、unique(唯一值数)、top(频数最高者)、
freq(最高频数)、mean(平均值)、std(方差)、min(最小值)、50%(中位数)、max(最大值)
'''
explore.to_csv(resultfile) # 导出结果
import pandas as pd
import matplotlib.pyplot as plt
datafile= r"D:\Weixin\WeChat Files\wxid_cg9y4qd0yxhb22\FileStorage\File\2023-03\air_data.csv" # 航空原始数据,第一行为属性标签
# 读取原始数据,指定UTF-8编码(需要用文本编辑器将数据装换为UTF-8编码)
data = pd.read_csv(datafile, encoding = 'utf-8')
# 客户信息类别
# 提取会员入会年份
from datetime import datetime
ffp = data['FFP_DATE'].apply(lambda x:datetime.strptime(x,'%Y/%m/%d'))
ffp_year = ffp.map(lambda x : x.year)
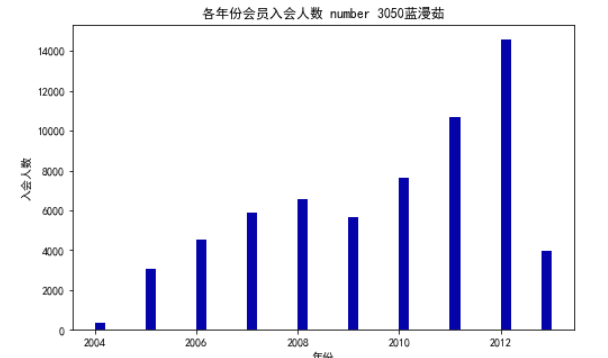
# 绘制各年份会员入会人数直方图
fig = plt.figure(figsize = (8 ,5)) # 设置画布大小
plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示
plt.rcParams['axes.unicode_minus'] = False
plt.hist(ffp_year, bins='auto', color='#0504aa')
plt.xlabel('年份')
plt.ylabel('入会人数')
plt.title('各年份会员入会人数 number 3050蓝漫茹')
plt.show()
# 提取会员不同性别人数
male = pd.value_counts(data['GENDER'])['男']
female = pd.value_counts(data['GENDER'])['女']
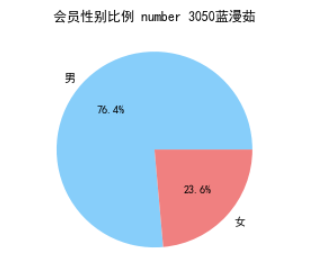
# 绘制会员性别比例饼图
fig = plt.figure(figsize = (7 ,4)) # 设置画布大小
plt.pie([ male, female], labels=['男','女'], colors=['lightskyblue', 'lightcoral'],
autopct='%1.1f%%')
plt.title('会员性别比例 number 3050蓝漫茹')
plt.show()
# 提取不同级别会员的人数
lv_four = pd.value_counts(data['FFP_TIER'])[4]
lv_five = pd.value_counts(data['FFP_TIER'])[5]
lv_six = pd.value_counts(data['FFP_TIER'])[6]
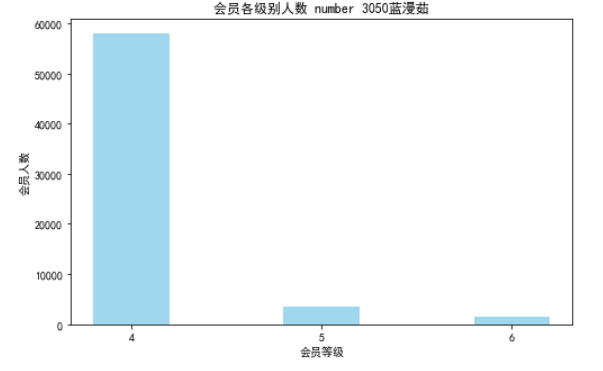
# 绘制会员各级别人数条形图
fig = plt.figure(figsize = (8 ,5)) # 设置画布大小
plt.bar(x=range(3), height=[lv_four,lv_five,lv_six], width=0.4, alpha=0.8, color='skyblue')
plt.xticks([index for index in range(3)], ['4','5','6'])
plt.xlabel('会员等级')
plt.ylabel('会员人数')
plt.title('会员各级别人数 number 3050蓝漫茹')
plt.show()
# 提取会员年龄
age = data['AGE'].dropna()
age = age.astype('int64')
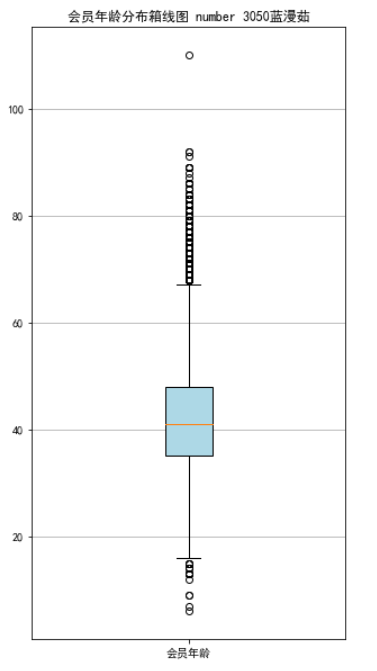
# 绘制会员年龄分布箱型图
fig = plt.figure(figsize = (5 ,10))
plt.boxplot(age,
patch_artist=True,
labels = ['会员年龄'], # 设置x轴标题
boxprops = {'facecolor':'lightblue'}) # 设置填充颜色
plt.title('会员年龄分布箱线图 number 3050蓝漫茹')
# 显示y坐标轴的底线
plt.grid(axis='y')
plt.show()
# 乘机信息类别
lte = data['LAST_TO_END']
fc = data['FLIGHT_COUNT']
sks = data['SEG_KM_SUM']
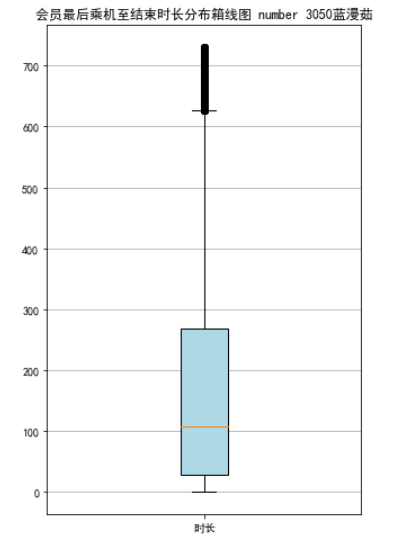
# 绘制最后乘机至结束时长箱线图
fig = plt.figure(figsize = (5 ,8))
plt.boxplot(lte,
patch_artist=True,
labels = ['时长'], # 设置x轴标题
boxprops = {'facecolor':'lightblue'}) # 设置填充颜色
plt.title('会员最后乘机至结束时长分布箱线图 number 3050蓝漫茹')
# 显示y坐标轴的底线
plt.grid(axis='y')
plt.show()
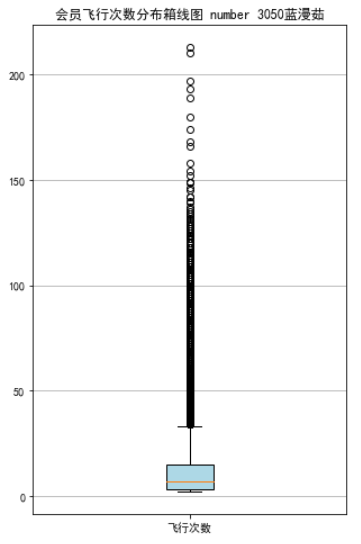
# 绘制客户飞行次数箱线图
fig = plt.figure(figsize = (5 ,8))
plt.boxplot(fc,
patch_artist=True,
labels = ['飞行次数'], # 设置x轴标题
boxprops = {'facecolor':'lightblue'}) # 设置填充颜色
plt.title('会员飞行次数分布箱线图 number 3050蓝漫茹')
# 显示y坐标轴的底线
plt.grid(axis='y')
plt.show()
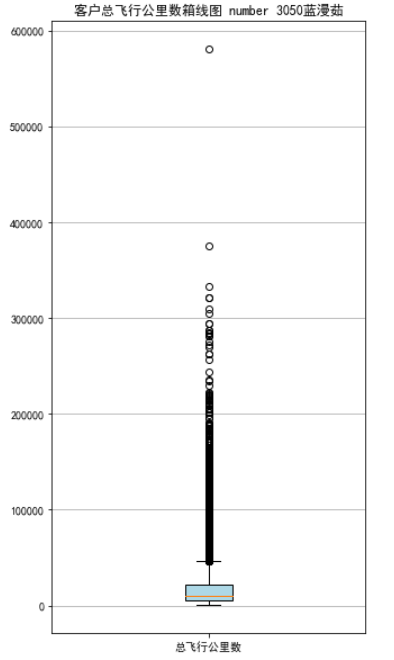
# 绘制客户总飞行公里数箱线图
fig = plt.figure(figsize = (5 ,10))
plt.boxplot(sks,
patch_artist=True,
labels = ['总飞行公里数'], # 设置x轴标题
boxprops = {'facecolor':'lightblue'}) # 设置填充颜色
plt.title('客户总飞行公里数箱线图 number 3050蓝漫茹')
# 显示y坐标轴的底线
plt.grid(axis='y')
plt.show()
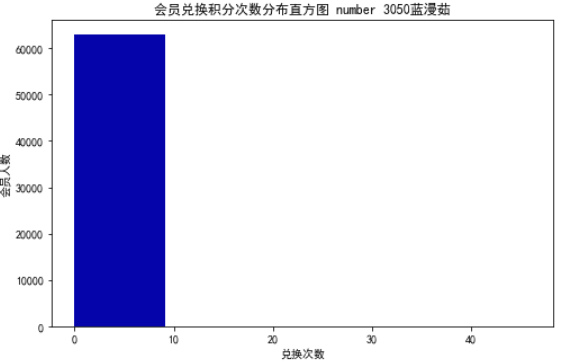
# 积分信息类别
# 提取会员积分兑换次数
ec = data['EXCHANGE_COUNT']
# 绘制会员兑换积分次数直方图
fig = plt.figure(figsize = (8 ,5)) # 设置画布大小
plt.hist(ec, bins=5, color='#0504aa')
plt.xlabel('兑换次数')
plt.ylabel('会员人数')
plt.title('会员兑换积分次数分布直方图 number 3050蓝漫茹')
plt.show()
# 提取会员总累计积分
ps = data['Points_Sum']
# 绘制会员总累计积分箱线图
fig = plt.figure(figsize = (5 ,8))
plt.boxplot(ps,
patch_artist=True,
labels = ['总累计积分'], # 设置x轴标题
boxprops = {'facecolor':'lightblue'}) # 设置填充颜色
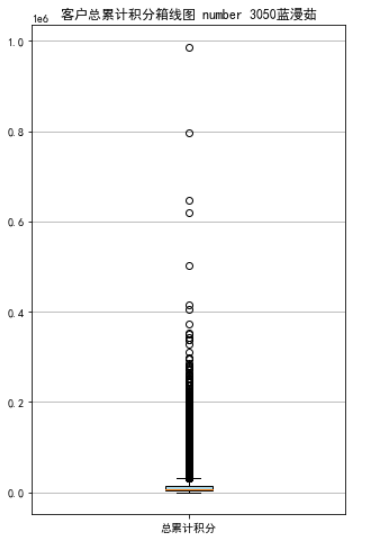
plt.title('客户总累计积分箱线图 number 3050蓝漫茹')
# 显示y坐标轴的底线
plt.grid(axis='y')
plt.show()
# 提取属性并合并为新数据集
data_corr = data[['FFP_TIER','FLIGHT_COUNT','LAST_TO_END',
'SEG_KM_SUM','EXCHANGE_COUNT','Points_Sum']]
age1 = data['AGE'].fillna(0)
data_corr['AGE'] = age1.astype('int64')
data_corr['ffp_year'] = ffp_year
# 计算相关性矩阵
dt_corr = data_corr.corr(method = 'pearson')
print('相关性矩阵为:\n',dt_corr)
# 绘制热力图
import seaborn as sns
plt.subplots(figsize=(10, 10)) # 设置画面大小
sns.heatmap(dt_corr, annot=True, vmax=1, square=True, cmap='Blues')
plt.title('热力图 number 3050蓝漫茹')
plt.show()

import pandas as pd
a=r"C:\Users\86139\Desktop\te\city.xls"
data=pd.read_excel(a)
d=data['WORK_CITY'].value_counts()
#统计列“WORK_CITY”中各个类型的重复次数
print(d)
resultfile = '../te/city12.csv'
d.to_csv(resultfile)




