
第一次软工大作业(词频分析)项目总结
第一次软工大作业完成了,这大概也是人生中第一次进行较大规模的项目开发,虽然是一个小巧的个人项目,但还是收获颇多。
这篇博客有点长,为了交作业把本来应该写好几个博文的塞到一个里面了……所以就加了个目录,按需求看吧
目录:
### 1. 初始规划在我的第一篇博文中,我记录了我的初始规划,将功能大致分为五个模块,关系如图:

各个模块的具体功能:
- 文件读取模块:在给定的文件夹中遍历每个文件,依次读取各个文件。
- 字符和行数统计模块:简单地统计字符数与行数。
- 单词统计模块:因为较为复杂,所以单独作为一个模块。
- 存储模块:为单词统计统计模块提供快速存取、统计单词与词组的功能。最开始,我考虑了字典树和哈希表两个方案。
- 输出模块:提供格式化的输出。
最开始,我也规划了一个进度。虽然最后按时完成了项目,但是根本没有严格按照规划的进度进行。
### 2. 开发过程 #### 2.1. 混乱的开始我从周日才开始编码工作,所以在一开始十分急迫,想要一下将所有模块写好。外加一开始我最简单的字符和行数统计模块就和助教给出的标答不同,因此感到灰心丧气、更加懒于debug,所以一心只想着把每个模块都写上,然后再慢慢修改。
事实证明,这是一种非常低效的思想,一开始设计的疏忽会导致后续大量的重构工作。
一开始,我还因为懒得学习visual studio的单元测试功能,打算自己实现类似单元测试的功能,等项目基本做完之后再学习单元测试功能。
同样是事实证明,这个想法也是错误的。单元测试对于项目的重要性众所周知,而重复造轮子(而且还是非常粗陋的方形轮子)毫无必要。
在这个阶段,因为发现初始规划的模块不太合理,我基本没有按照我的初始规划进行编码。这种无计划性为后续带来了很大的麻烦。
这个阶段的结果见第一篇博客。
#### 2.2 迷茫的重构虽然一开始操作十分混乱,但我还是大体搭成了一个框架,可以完成一些功能,虽然漏洞百出。
接下来,理应是调试和优化的过程。然而,如我的第二篇博客中所说,随着调试的继续,我发现我的代码结构、模块分解有许多不妥之处,主要集中于对于单词统计功能的设计。
在一开始的编码过程中,我对于单词的处理很模糊。我将单词分为三个模块,但是耦合非常严重。因此,我进行了不断的重构,但一直无法写出结构合理的代码。
最后,我被迫停止了编码过程,而开始抽象地思考功能分解。惊喜的是,通过抽象的思考,我立刻将功能分解为了_解析单词、词组_和_存储单词_两个模块,按照这个分解方式便非常顺利了。
另一个我重构了很久的东西是哈希表。因为不知道助教是否支持c++11,因此不敢使用unordered_map,只敢自己实现哈希表。我采用拉链法解决冲突。
首先,在分解功能之前,我有一个Word类,又有一个结点类,等等,因此功能非常复杂、耦合严重,这个阶段已经描述过,不再赘述。
然后,由于我对单词、词组的处理方式相似,所以我试图写一个类,而两个哈希表都是这个类的对象。事实证明这样并不可行,因为单词只需要记录实际形式即可,词组需要储存两个单词的形式,两者结构不同,不能用一个类表示。
接下来,我试图创立一个Word类,一个Phrase类,然后用泛型的方法实现哈希表。事实上在此之前我只在学习时写过一点点泛型,已经基本忘光了,又懒于认真学习,只是随便查查写写,因此写了非常久。最后终于写好后,我发现无法编译,查找资料后才发现在visual studio中泛型类的实现应该全部写在头文件中,对我来说这有违“美感”,因此最后放弃了。
再然后,我决定用两个不同的类型实现两个哈希表了。但是仍然是本着OOP的思想,我想写一个WordPool类,然后将哈希表的类型、各种操作封装进去,只暴露接口。不过这个似乎对我来说过于复杂,也不知为何,写了很久都没写好。
最后,我采取了最笨的方法,在全局变量中定义结构体、定义哈希表。这次终于成功了。
反思这个阶段,我发现我最大的错误在于错误地理解了一些原则,因此偏执地追求形式上而非实质上的良好设计。
首先,OOP原则,并不是让我们引入一些毫无意义的类,或者是将任何重复的功能都写成一个类。
例如我最后将两个哈希表用两个类实现,这样不仅满足了两个类的不同要求,而且在之后我发现对于词组的理解有误时,也可以直接修改词组的设计而没有必要重构。
更重要的在于,恰恰因为单词和词组操作非常相似,编码时很容易就将它们写混了。因为两者类型不同,所以写混时编译器会报错或者warning,因此省去了很多麻烦。
其次,不应该盲目地使用自己不熟悉的功能。也许使用泛型真的是一个好方法,而且以后总会学习,但在还有三天就是ddl而且自己根本没怎么写过泛型的时候,泛型一定不是好方法。与其将自己不熟悉的优秀功能写的稀烂,不如尽可能用自己熟悉的功能写好。
最后,不要盲目地重构。我一开始的重构方式只能用盲目来形容,就是看到两个功能有点相似就试图并到一起,有些差别就拆开。
事实上,要经过良好的设计之后,重构才是有意义的。
这个阶段之后的成果见第三次博客。
#### 2.3 调试、优化、移植在这个阶段,基本功能已经完成了,因此我开始逐个模块的调试与整体优化,并进行移植工作。
这个阶段我做了许多小工作,不过也混在一起做了,没有很明确的进度,这确实不太好,在大型项目中也不能这样。一些工作如下:
(1) 单元测试
在这个阶段,我开始使用visual studio的单元测试。
单元测试,即对不同的模块分别测试其接口,十分方便。如图:


单元测试真的非常好用。单元测试不仅方便,而且能够迅速发现并定位错误,在这个阶段我还重构了好几次,幸亏有单元测试,否则许多重构过程中的细微错误我都发现不了。
(2) 字符与行数的统计
因为字符数、行数与助教给出的答案始终不一样,所以我花了很大的力气。
最后,我找到了一个似乎没什么用处的错误:我一开始是通过EOF字符判断是否到达文件末尾,然而某些文件中因为各种奇怪的原因可能会有这个字符,所以应该采用ifstream的eof()方法判断是否到达文件末尾。
然而,问题还没有消失。而且在我移植到linux下后,同样的代码、同样的文件,两个平台下结果居然不一样……最后我终于发现,只要是ascii码编码的纯文本文件都不会出问题,而unicode等其他编码方式编码的文件和非文本文件都会出问题。这已经超出了我的知识范围,我决定不予处理。
(3) 存储模块的重构
还是担心全局变量会被误操作,所以还是用一个类将其包裹了起来。不过在之前编写了那么多的前提下,再将全局变量实现改为类实现就简单多了。这进一步说明编码工作不能操之过急,应该一块块来,从小到大。
然而,发现一个类实例不能开辟那么大的空间,于是仍然将哈希表作为全局变量,但将其写在cpp文件里不对外暴露,而实现了一个访问器类。
(4) string和char数组
最开始,我使用的是string。后来因为听说很慢,所以没有经过性能测试就改成了char数组。
再后来,老师说单词最大长度为1024,因此采用定长字符数组轻松爆内存。然而如果使用char指针我害怕自己出错,而且不断地修改char指针估计也和string效率差不多,因此在存储模块改成了string,解析模块仍使用数组。最后的性能测试发现,string并没有成为性能瓶颈。
说明实验是检验真理的唯一标准……
### 3. psp表格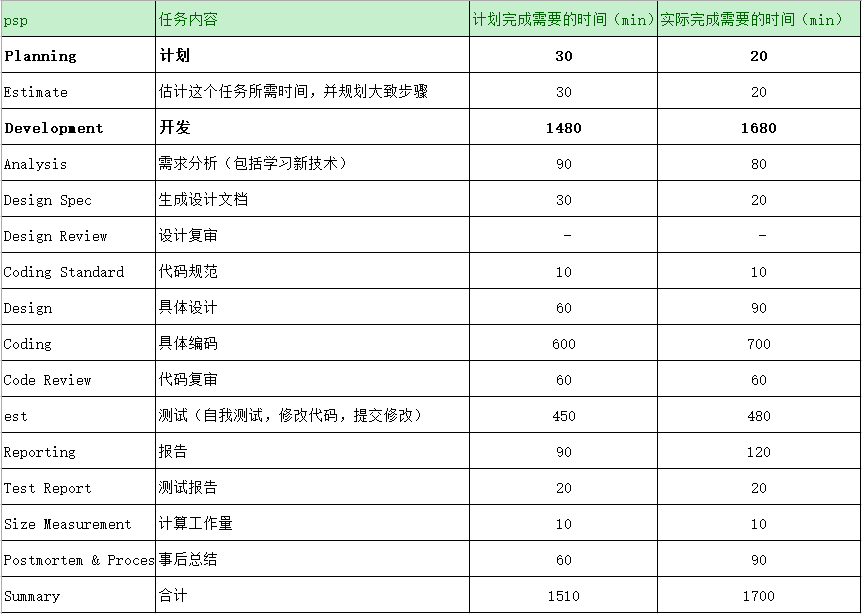
我的哈希表具体实现为开辟一个指针数组,每加入一个数据项并new一个结点。运用visual studio的性能分析工具,我发现new新节点消耗了很多时间,成为性能瓶颈。考虑到动态内存分配回收会比静态区内存分配慢,所以我打算将哈希表改为一个结点数组,产生冲突时再new新节点。、
更改代码之后,通过visual studio显示new结点不再是性能瓶颈,我很高兴。然而奇怪的是,不管是在linux平台下还是windows平台下,更改后的代码运行时间没有显著降低。分析并与大佬讨论后,我认为是因为申请的节点空间一直存活到了最后,没有频繁的new delete、不容易产生内存碎片,加上系统分配内存的机制较好,所以与静态区分配内存效率上没有显著区别。
因此,为了节约空间,还是使用了之前的代码。
#### 4.2 linux上使用valgrind工具分析内存泄漏valgrind是一个强大的分析工具,其功能包括内存分析、多线程分析、性能分析等,介绍见valgrind介绍、安装与使用。
因为我大量使用了动态内存分配,因此我很担心内存泄漏问题,于是一开始就是用了valgrind的内存泄漏分析工具。
结果显示,并没有发现结点的内存泄漏。这也很正常,因为申请的结点会一直存活到最后。
然而显示,产生了内存泄漏。查找遍历文件夹时,使用了opendir而没有使用closedir,因此产生了
valgrind分析结果十分冗长,在此不附上了。另附valgrind五种内存泄漏的解释。
本来还打算使用valgrind的性能分析工具,然而实在太慢了,于是使用了gprof。
#### 4.3 linux上使用gprof分析性能gprof是GNU自带的性能分析工具,其使用方法简单,编译时加上-pg选项,之后直接运行便会生成gmon.out文件,用gprof工具对此文件进行解析即可。详见使用gprof对程序的性能分析。命令行代码如下:
g++ hw1.cpp -pg -no-pie -o test.exe
./test.exe test
gprof test.exe gmon.out > gprof.log
随后,查看gprof.log中的性能报告结果即可。我使用助教给的测试集,分析结果如下:

gprof给出了对各项数据的解释,较为重要的数据为%time表示时间占比,self time表示本函数占据时间。
可以看出,add_phrase函数占据了最多时间。联想visual studio的统计结果,推测是动态分配内存消耗的时间,这个在4.1 visual studio上进行性能测试与优化已经提及。修改代码后,gprof确实显示add_phrase不再消耗最多时间,结果如下:

注:两个测试集不一样,因此不应该比较绝对时间,应该比较时间占比
说明推测是正确的。
另外,哈希函数是一个性能的瓶颈。因此我又尝试了好几个哈希函数,但时间占用率都在14% ~ 16%之间,没有显著差别,不知如何优化。
对于单词的解析也消耗了较多时间,因此我在单词的解析模块中使用的是char数组而非string,但之后个人觉得已经没有优化空间了。
### 5. 最终结构最终,我的代码分为六个模块,关系如图:

各个模块具体解释:
- main:调用traverse_file模块获取给定文件夹下所有文件的绝对路径,通过count模块对各个文件进行统计。
- traverse_file:实现遍历递归的功能,在windows下使用<io.h>,在linux下使用<dirent.h>。本质上为DFS,用栈保存历史路径即可。
- count:获取文件名,打开给定文件、读取字符,将字符分别发送给count_word、count_char两个模块进行统计。加上这一个模块是因为我发现文件流读写太慢,因此两个统计应该同时进行。然而让两个模块共享文件流并不妥当,所以我选择在count模块中打开文件流,将字符分发给两个统计模块,从而降低耦合。
- count_char:由count模块发送的字符进行字符、行数统计。
- count_word:由count模块发送的字符解析为各个单词,自己统计单词总数,并将解析出的单词存入word_pool模块中。
- word_pool:存储count_word模块发送的各个单词、词组,并能进行排序、找出词频最高的单词、词组。对于存储模块的具体实现,由于哈希表操作方便,比字典树更适合操作词组,而且同学们大多采用的是哈希表,因此我选择了采用哈希表。
编码之前一定要先设计。
而且一定要是良好的设计……
不要一次进行太多工作,允许项目慢慢演变。
很多问题只有在编码过程中才会慢慢发现,尤其是自己知识能力没有那么扎实的时候。所以要保持一定的灵活性,不要一开始就把一切都计划得过于精致,而应该允许项目结构慢慢调整。
另外,个人能力是有限的,应该从小处开始编码,慢慢做大,敏捷开发。
编码规则是为人服务的,不要盲目追求编码规则。
盲目地追求编码规则,有时候会将问题复杂化,而编码规则理应用来将问题简单化。
另外,编码规则只有被理解了之后才有用处,盲目地遵循编码规则往往是没有真正理解的表现。
多在网上查找资料,寻找他人帮助。
这次编码中,我通过网络学到了很多东西,如递归遍历文件夹的方式、valgrind,gprof的使用方法、一些bug的解决方法等。
同时,同学与助教也给了我许多帮助。
很多时候,不应该一个人陷在问题里,积极地求助更高效。
使用单元测试!
单元测试可以快速查找与定位错误,在较大的项目中必不可少。visual studio有自带的单元测试框架,还有nunit、xunit等许多良好的单元测试框架,要利用这些工具。
其他与这次项目相关的博文:
软工第一次个人作业 需求分析、模块规划与时间规划
软工第一次作业 进度记录
软工第一次作业 进度记录2
软工第一次作业 进度记录三 简单的性能分析
