
让我们从零开始使用PyTorch构建一个轻量级的词嵌入模型

图片来源:Phil Hearing(Unsplash)
在我之前写的一篇文章中,我们学习了如何使用PyTorch的nn.Embedding层将单词转换为稠密向量。但由于该嵌入层是未经训练的,这些向量并没有任何语义含义。默认情况下,PyTorch会使用随机权重初始化嵌入层,这使得生成的向量基本上是毫无意义的。今天,我们要改变这一点,并希望赋予我们的嵌入一些真正的含义。
我们将创建一个微型Word2Vec模型。换句话说,我们将使用Word2Vec方法来训练我们的嵌入层。
Word2Vec是一种非常流行的方法,用于从大型文本语料库中学习单词的向量表示。这些向量携带语义信息,使得具有相似含义的单词被映射到向量空间中的相邻点。例如,“happy”、“joyful”和“cheerful”这些词的嵌入会彼此接近。同样,“car”、“automobile”和“vehicle”也会聚集在一起。
这些向量实际上反映了训练好的Word2Vec模型如何内化各种概念,比如性别差异、地理关系以及类别分组(比如动物、水果、衣物等),这些概念对于自然语言理解至关重要。
测试并使用自己训练的单词嵌入是一种奇妙的体验。想象一下,你可以用向量数学进行推理,比如这样:
Technology + Nature - Industry = Sustainability.
当然,构建一个高性能、全球规模的Word2Vec模型通常是那些拥有大量资源的公司在做的事情。这需要处理TB级的文本,并利用数百个GPU或TPU进行训练。因此,我们将创建一个微型的玩具模型,仅作为一个概念验证(POC)。
下载数据集
我的训练数据来自一本书。这本书可以在Project Gutenberg免费下载,它的名字是 “The Oxford Book of American Essays by Brander Matthews et al”. 你也可以选择其他书籍,甚至可以合并多本书的内容。
我使用wget下载了这本书,并统计了其中的行数、单词数和字符数:
$ wget -O dataset.txt 'https://www.gutenberg.org/ebooks/40196.txt.utf-8'
$ wc -lwc dataset.txt
16020 166444 974113 dataset.txt
处理数据集
现在,我们需要确定数据集中包含的词汇。我们将使用nltk来完成这个任务。思路很简单,就是找到数据集中所有唯一的标记(tokens)。
import nltk
from nltk.tokenize import word_tokenize
from pathlib import Path
nltk.download('punkt_tab')
dataset = Path("./dataset.txt").read_text()
tokens = word_tokenize(dataset.lower())
vocab = sorted(list(set(tokens)))
vocab_size = len(vocab)
print(f"Number of tokens: {len(tokens)}")
print(f"Vocabulary size: {vocab_size}")
print(f"Vocabulary subset: {vocab[1000:1010]}")
示例输出:
Number of tokens: 191122
Vocabulary size: 16831
Vocabulary subset: [
'aisles', 'aitken', 'akin', 'alabamas',
'alacrity', 'aladdin', 'alarm', 'alarmed', 'alarming', 'alas'
]
NLTK的word_tokenize()方法确保标点符号(如 ! ? . ,)被单独处理,因此我们不会丢失任何重要的结构信息。
顺便说一句,Meta AI的LLaMA模型使用的词汇量为32,000个标记(tokens),它们采用的是字节对编码(BPE)分词器。BPE是一种通过迭代合并数据中最频繁的字节或字符对来构建词汇表的方法,它可以通过子词单元高效地表示文本。但在这篇文章中,我们不会使用这种分词方法,也许以后会讨论。
构造训练样本
为了保持简单,我们将使用一个小的上下文窗口,即在目标单词的前后各一个单词。这种方法不仅让Word2Vec算法的实现更加简单,同时仍然能够捕捉单词之间的有意义关系。
center_words = []
context_words = []
for i in range(1, len(tokens) - 1):
center_words.append(tokens[i])
context_words.append(tokens[i - 1])
center_words.append(tokens[i])
context_words.append(tokens[i + 1])
转换为PyTorch张量
为了能够训练我们的微型模型,我们必须将单词数组转换为索引数组,然后再转换为PyTorch张量。
最后,如果你有一块支持NVIDIA CUDA平台的GPU,你可以把这些张量移动到GPU上。如果你只用CPU来执行训练,训练将会花费非常长的时间。
word_to_index = {word: i for i, word in enumerate(vocab)}
center_word_indices = [word_to_index[word] for word in center_words]
context_word_indices = [word_to_index[word] for word in context_words]
import torch
center_word_tensor = torch.tensor(center_word_indices, dtype=torch.long)
context_word_tensor = torch.tensor(context_word_indices, dtype=torch.long)
center_word_tensor = center_word_tensor.to("cuda")
context_word_tensor = context_word_tensor.to("cuda")
我们刚刚创建的这些张量可以用于创建 TensorDataset 类的一个实例,这是一个方便的实用类,帮助我们管理和组织由张量组成的数据集。目前,TensorDataset 将确保我们的模型在训练时获取对应的中心词和上下文词对。
使用 TensorDataset 来创建 DataLoader 类的一个实例是个不错的主意,这样可以实现批处理和数据随机打乱,使训练更加高效。
创建数据加载器
tensor_dataset = torch.utils.data.TensorDataset(
center_word_tensor, context_word_tensor
)
data_loader = torch.utils.data.DataLoader(
tensor_dataset, batch_size=8192, shuffle=True
)
批量大小将设为 8192。如果你有 GPU,这通常是一个安全的起点。它在内存使用和训练效率之间保持平衡。但你可以自由尝试不同的数值。
我认为我们的训练数据已经准备好了。现在,让我们创建一个微型模型,它包含一个嵌入层和一个线性层。这将是一个继承自 PyTorch nn.Module 的类的实例。
定义模型
import torch.nn as nn
embedding_dim = 128
class TinyWord2Vec(nn.Module):
def init(self, vocab_size, embedding_dim):
super(TinyWord2Vec, self).init()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.output_layer = nn.Linear(embedding_dim, vocab_size)
def forward(self, center_word_idx):
embeddings = self.embedding(center_word_idx)
output = self.output_layer(embeddings)
return output
model = TinyWord2Vec(vocab_size, embedding_dim).to("cuda")
我将使用 128 维度的嵌入。
要真正训练我们的模型,我们需要两个核心组件:损失函数(loss function) 和 优化器(optimizer)。
损失函数 用于衡量模型的预测值与实际目标值之间的差距。它量化了模型的预测有多“错误”,并提供一个信号来引导训练过程。因此,训练的目标本质上就是最小化这个损失。
CrossEntropyLoss 非常适用于分类问题,在这些问题中,我们需要为多个可能的类别分配概率。在我们的情况下,这些类别就是词汇表中的单词。在内部,它在一步操作中结合了 LogSoftmax 和 NLLLoss(负对数似然损失,Negative Log Likelihood Loss)。
loss_function = nn.CrossEntropyLoss()
优化器的职责是根据损失函数计算出的梯度来更新模型的权重。它将决定在训练过程中调整嵌入的幅度。
Adam 优化器是一个不错的选择,因为它能够动态调整学习率,并且通常比传统优化器(如随机梯度下降 SGD)收敛得更快。
import torch.optim as optim
optimizer = optim.Adam(model.parameters(), lr=0.01)
你可能已经猜到了,lr 参数指定了我们模型的学习率。是的,它是一个超参数(hyperparameter),用于控制模型更新权重的速度。0.01 是一个不错的起点。
现在,我们已经准备好所有必需的内容,可以开始训练循环(training loop)了。我们将训练 50 轮(epochs)。在机器学习中,一个 epoch 指的是对整个训练数据集完整地遍历一次。
num_epochs = 50
for epoch in range(num_epochs):
total_loss = 0
for center_words, context_words in data_loader:
optimizer.zero_grad()
output = model(center_words)
loss = loss_function(output, context_words)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch + 1}/{num_epochs}, Loss: {total_loss:.4f}")
Output:
Epoch 1/50, Loss: 374.3675
Epoch 2/50, Loss: 287.4267
Epoch 3/50, Loss: 267.5057
...
Epoch 50/50, Loss: 222.7124
注意: 当我们将 center_words 传入模型时,我们得到的嵌入形状是 (batch_size, embedding_dim)。而 nn.CrossEntropyLoss() 期望模型的输出形状为 (batch_size, vocab_size)。
你现在可以运行代码,训练可能需要一段时间才能完成。而且,在程序退出后,你会丢失训练得到的嵌入。所以,我们需要保存模型的权重。
保存模型
torch.save(model.state_dict(), "tinyw2v_weights.pth")
state_dict() 返回一个字典,其中包含模型的参数(即它的权重和偏置)。因此,我们保存了一切必要的内容,以便之后加载模型。
你现在可以运行训练,并观察损失的下降。我已经创建了一张损失曲线图。
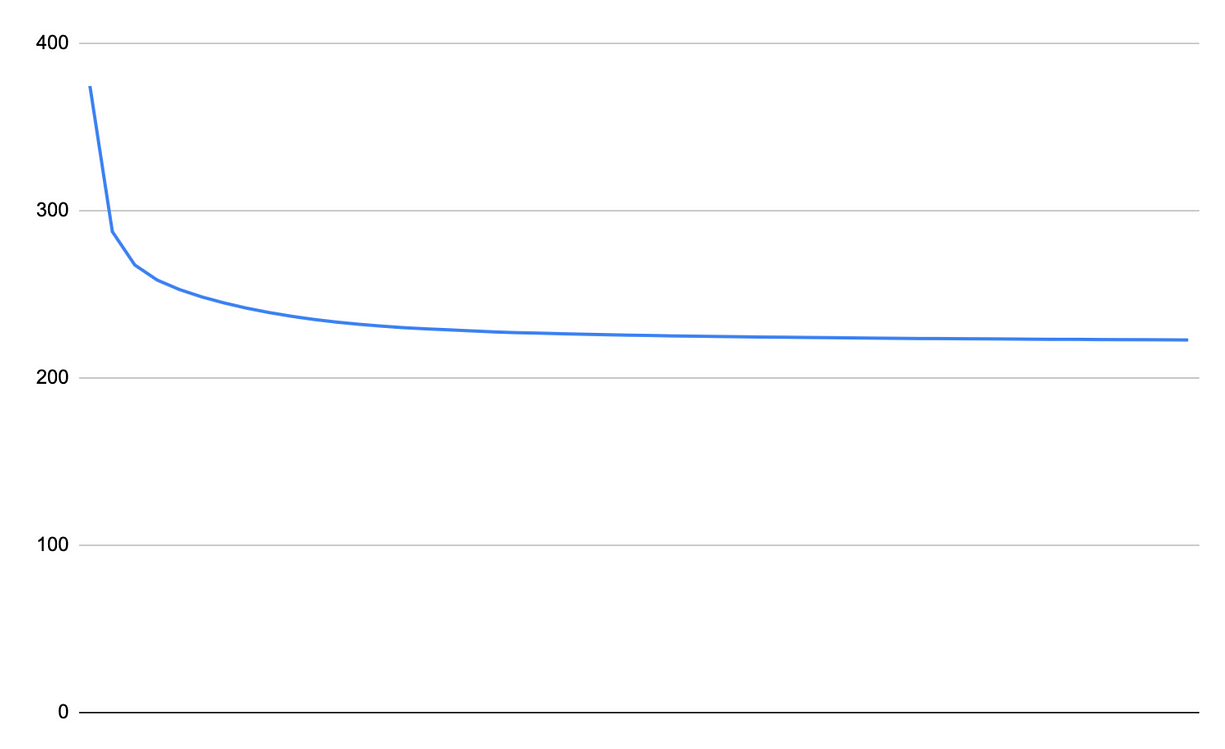
损失曲线,Hathibelagal 截图
我们可以看到,如果继续训练,并不会带来明显的改进。损失曲线几乎已经在约 222 处趋于平稳。
让我们看看我们的嵌入是否有一定的意义。不能对这么小的数据集抱太高的期望,但还是值得一试。所以,首先要将模型设置为评估模式。哦,另外,除非你打算重新训练模型,否则别忘了加载权重。
model.load_state_dict(torch.load("tinyw2v_weights.pth"))
model.eval()
或者,如果你的模型是在 GPU 上训练的,但你想在 CPU 上进行推理,请使用以下代码:
model.load_state_dict(torch.load("tinyw2v_weights.pth",
map_location=torch.device('cpu')))
model.eval()
现在,要测试我们的模型,我们将简单地使用 PyTorch 的 cosine_similarity() 函数。借助它,我们可以判断我们的嵌入是否真正编码了单词之间的关系。
在单词嵌入的背景下,余弦相似度(cosine similarity) 有助于量化两个单词在语义上的相关性,基于它们的向量表示。因此,我们的思路是获取目标单词的嵌入,并计算它与词汇表中所有其他单词的余弦相似度,然后找出最相似的五个单词。
评估模型
def get_similar(target_word):
target_idx = vocab.index(target_word)
target_embedding = model.embedding.weight[target_idx]
similarities = torch.cosine_similarity(
target_embedding.unsqueeze(0), model.embedding.weight, dim=1)
top_indices = similarities.topk(6).indices[:]
similar_words = [vocab[idx] for idx in top_indices]
print(similar_words)
get_similar("four")
get_similar("greek")
get_similar("man")
Output:
['four', 'threescore', 'seven', 'six', 'eating', 'fourscore']
['greek', 'zest', 'german', 'french', 'operative', 'inconsistencies']
['man', 'age', 'cabin_', 'poet', 'jacket', 'farthing']
正如你所看到的,我们的词嵌入已经开始有一定的意义了。例如,“greek”、“german” 和 “french” 似乎被聚类在一起。
你可以通过增加训练数据的规模来进一步改进嵌入。例如,我尝试将《傲慢与偏见》(Pride and Prejudice)的文本拼接到我的数据集中。
$ wget -O p2.txt https://www.gutenberg.org/cache/epub/1342/pg1342.txt
$ echo " " >> dataset.txt
$ cat p2.txt >> dataset.txt
这样一来,损失下降到了约 138。于是,我再次运行了 get_similar() 函数,得到的结果明显更好。
get_similar("heart")
get_similar("pride")
get_similar("man")
['heart', 'mind', 'atonement', 'fights', 'sagacity', 'overtaken']
['pride', 'beauty', 'condemned', 'abilities', 'statue', 'portrait']
['man', 'woman', 'soul', 'market-place', 'battle', 'display']
如果你坚持到了这里,恭喜你!


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· 实操Deepseek接入个人知识库
· 易语言 —— 开山篇
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比