你真是个绝对的傻瓜,居然相信“AI 代理”的炒作。
你真是个绝对的傻瓜,居然相信“AI 代理”的炒作。

“AI 代理” — 由 X 的 Grok 生成
我甚至不能浏览 LinkedIn 而不看到一些产品经理在炒作 AI 代理“马上就会到来”。
在你跳进评论区之前,我不是偏见。我从 ChatGPT 之前就开始使用大型语言模型,当时它还是 GPT-3,只能预测句子中的下一个词(而不是现在大家熟悉的聊天界面)。
我从零开始构建过 AI 应用,训练过各种类型的 AI 模型。我曾在世界上最顶尖的人工智能和计算机科学学校——卡内基梅隆大学,学习过深度学习课程,并在那里获得了我的硕士学位。
然而,当我看到 TikTok 上的另一个视频时,我忍不住感到尴尬,想起了“Web 3 要改变互联网”的话题。
我发誓,这一定是机器人农场、不了解技术的非技术人士和 OpenAI 精心制造的炒作,目的是让他们获得更多的资金。我是说,你认识多少个发布过生产级 AI 代理的工程师?
没错,零个。
下面是为什么这一切炒作都是无稽之谈。
什么是“AI 代理”?
AI 代理在人工智能领域其实有很长的历史。最近,由于 ChatGPT 的出现,它的意思变成了一个大型语言模型,结构上用于执行推理并完全自主地完成任务。
这个模型可能会通过强化学习进行微调,但在实际应用中,人们通常只是使用 OpenAI 的 GPT、Google Gemini 或 Anthropic 的 Claude。
代理和语言模型的区别在于,代理能自主完成任务。
这里有个例子。
我有一个算法交易和金融研究平台,
假设我想停止支付外部数据提供商费用,获取美国公司基本数据。
对于传统的语言模型,我必须编写与之交互的代码。这会是如下的步骤:
-
构建一个脚本,抓取 SEC 网站,或使用 GitHub 仓库获取公司信息(遵守其服务条款中的每秒 10 次请求的限制)
-
使用像 pypdf 这样的 Python 库将 PDF 转换为文本
-
将其发送给大型语言模型进行数据格式化
-
验证响应
-
将其保存到数据库
-
对所有公司重复此过程
使用 AI 代理,你理论上应该只需要说:
“抓取所有美国公司的过去和未来历史数据,并将其保存到 MongoDB 数据库。”
也许它会问你一些澄清性问题。它可能会问你对数据架构的想法是什么,或者哪些信息最重要。
但基本思想是,你给它一个目标,它会完全自主地完成任务。
听起来好得难以置信,对吧?
那是因为它确实不可信。
AI 代理在实践中的问题
现在,如果最便宜的小型语言模型是免费的,像 Claude 3.5 一样强大,并且可以在任何 AWS T2 实例上本地运行,那么这篇文章的语气就完全不同了。
它不会是批评,而是警告。
然而,实际上,AI 代理在现实世界中不起作用,原因如下:
- 小型模型根本不够强大 代理的核心问题是它们依赖于大型语言模型。
更具体地说,它们依赖于一个“好”模型。
GPT-4o mini,最便宜的大型语言模型,除了 Flash 外,是非常棒的,价格也很划算。
但它根本不够强大,无法完成现实世界中的代理任务。
它会偏离目标,忘记目标,或者在任何情况下都会犯一些简单的错误,尽管你给它提供了很好的提示。
如果被部署到实际应用中,你的业务将为此付出代价。当大型语言模型出错时,除非你也建立了(可能是基于 LLM 的)验证框架,否则很难发现。一开始的一个小错误,导致后续一切都出问题。
- 错误的积累 假设你正在使用 GPT-4o-mini 进行代理工作。
你的代理将提取公司财务信息的任务分解成更小的子任务。假设每个子任务正确的概率是 90%。
错误会积累。如果一个任务有四个子任务,完成最终输出的概率极低。
比如,我们来分解一下:
-
完成一个子任务的概率是 90%
-
完成两个子任务的概率是 0.9 * 0.9 = 81%
-
完成四个子任务的概率是 66%
看明白了吗?
为了缓解这个问题,你会想使用更强大的语言模型。更强的模型可能将每个子任务的正确率提高到 99%。经过四个子任务,最终的准确率是 96%。这已经好很多了(但仍然不是完美的)。
最重要的是,切换到这些更强的模型会带来成本的爆炸式增长。
- 成本的爆炸性增长
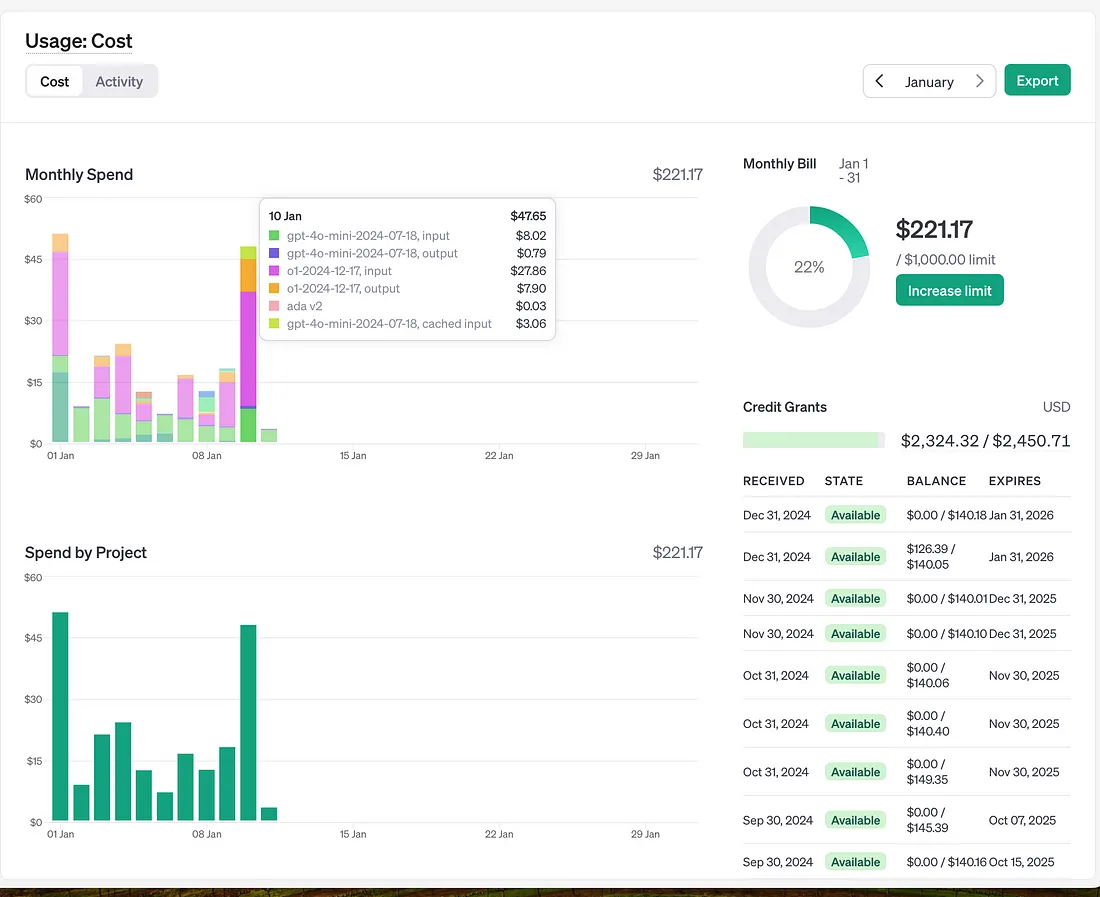
OpenAI 的 o1 模型与 GPT-4o-mini 之间的成本差异
一旦你切换到更强的 OpenAI 模型,你会看到成本爆炸式增长。
粉色和橙色的线是 OpenAI 的 o1 模型的成本。我可能每天使用它 4-5 次,用于非常密集的任务,比如生成股票分析的语法有效查询。
青柠绿和深蓝色的线是 GPT-4o-mini。该模型每天处理成百上千的请求,最终的成本只是 O1 的一小部分。
更重要的是,即使是这样,你仍然需要验证最终输出。你将因为同样的原因使用更强的模型进行验证。
所以,你为代理使用更大的模型,也为验证使用更大的模型。
看出来我为什么觉得这是 OpenAI 的阴谋了吗?
- 你正在创造非确定性结果的工作
使用 LLM 代理,你的整个工作范式转向了类似数据科学的方式。
你不再写可在任何地方运行且便宜的确定性代码,而是为运行在 GPU 集群上的模型编写非确定性提示。
如果你“幸运”,你在自己拥有 GPU 和微调模型,但即使如此,仅仅维护代理完成简单任务就会让你花费大量资金。
如果不幸的是,你完全被 OpenAI 锁定;如果你尝试换模型,你的提示直接就不能用,OpenAI 可以逐渐提高价格,而你正在使用他们的 API 运行关键的业务流程。
在你说“你可以用 OpenRouter 容易地切换模型”之前,先想一想。Anthropic 的模型输出与 OpenAI 的模型输出是不同的。
所以你必须重新调整整个技术栈,花费一大笔钱,只为了获得一个微小的改进,在另一个 LLM 提供商那里。
看到问题了吗?
结论
几乎可以肯定的是,当我看到关于代理的帖子时,发布者往往是一个没有实际使用过语言模型的人。
可以想象,这简直让人愤怒。
我不是说 AI 没有它的应用场景。即使是代理,几年后也能为工程师写简单代码提供价值。
但没有哪个理智的公司会用一套极其昂贵、容易出错的代理来替代他们的运营团队,以便执行公司关键的业务流程。
如果他们尝试,我们都将亲眼看到他们在两年内破产。他们会成为商业教科书中的一课,而 OpenAI 会从中赚取额外的 10 亿美元收入。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号