

创建用于预测序列的人工智能模型,评估模型的能力。

上一篇:《创建用于预测序列的人工智能模型(三),训练模型》
序言:对于当前的动则几千亿的大语言模型来说,训练的过程可以持续几天几周基于几个月,这取决于拥有的硬件数量以及总要训练的参数。模型训练完成后就进入模型的评估验证过程,一般会不断的重复直到优化完成。
评估人工智能模型的性能
当你训练好了一个 DNN 后,就可以开始用它进行预测了。但请记住,你使用的是窗口化数据集,因此对于某个点的预测是基于之前一定数量时间步的数据。
换句话说,由于你的数据保存在一个名为 series 的列表中,要预测某个值时,需要将从时间步 ttt 到 t+window_sizet + \text{window_size}t+window_size 的值传入模型,它将返回下一个时间步的预测值。例如,如果你想预测时间步 1,020 的值,需要取时间步 1,000 到 1,019 的值,然后用这些值预测序列中的下一个值。获取这些值的代码如下(注意这里写作 series[1000:1020],而不是 series[1000:1019]):
print(series[1000:1020])
然后,获取时间步 1,020 的实际值:
print(series[1020])
要预测该数据点的值,只需将该序列传入 model.predict。不过,为了保持输入形状一致,你需要使用 [np.newaxis],代码如下:
print(model.predict(series[1000:1020][np.newaxis]))
或者,如果你希望代码更通用,可以这样写:
print(series[start_point:start_point+window_size])
print(series[start_point+window_size])
print(model.predict(
series[start_point:start_point+window_size][np.newaxis]))
注意,这些操作基于窗口大小为 20 的假设,这个窗口大小可能比较小,可能会导致模型的准确性不够。如果你想尝试不同的窗口大小,需要重新调用 windowed_dataset 函数对数据集重新格式化,并重新训练模型。
以下是当起始点为 1,000 并预测下一个值时的输出:
[109.170746 106.86935 102.61668 99.15634 105.95478 104.503876
107.08533 105.858284 108.00339 100.15279 109.4894 103.96404
113.426094 99.67773 111.87749 104.26137 100.08899 101.00105
101.893265 105.69048 ]
106.258606
[[105.36248]]
第一个张量显示了一系列的值;接下来是实际的下一个值 106.258606;最后是模型预测的下一个值 105.36248。这是一个相当合理的预测,但我们如何衡量模型在一段时间内的准确性呢?我们将在下一节探讨这个问题。
探索整体预测
在上一节中,你学会了如何通过获取基于窗口大小(在这里是 20)的前一组值并将其传递给模型来预测某个时间点的值。如果想查看模型的整体预测结果,就需要对每一个时间步执行相同的操作。
你可以使用如下简单的循环完成这一任务:
forecast = []
for time in range(len(series) - window_size):
forecast.append(
model.predict(series[time:time + window_size][np.newaxis]))
首先,创建一个名为 forecast 的新数组,用于存储预测值。接着,对原始序列中的每个时间步调用 predict 方法,并将结果存储到 forecast 数组中。注意,对于数据的前 nnn 个元素(即窗口大小),无法进行预测,因为每次预测都需要前 nnn 个值。
完成循环后,forecast 数组将包含从时间步 21 开始的预测值。
如果你还记得,我们在时间步 1,000 处将数据集分为训练集和验证集。因此,下一步只需要保留从这个时间点以后的预测值。由于 forecast 数据已经偏移了 20(或窗口大小的值),可以像这样对其进行切分并转换为 Numpy 数组:
forecast = forecast[split_time-window_size:]
results = np.array(forecast)[:, 0, 0]
现在,results 的形状已经与预测数据一致了。你可以将其与验证数据进行对比并绘制图像:
plt.figure(figsize=(10, 6))
plot_series(time_valid, x_valid)
plot_series(time_valid, results)
绘制出的图像可能类似于图 10-3。
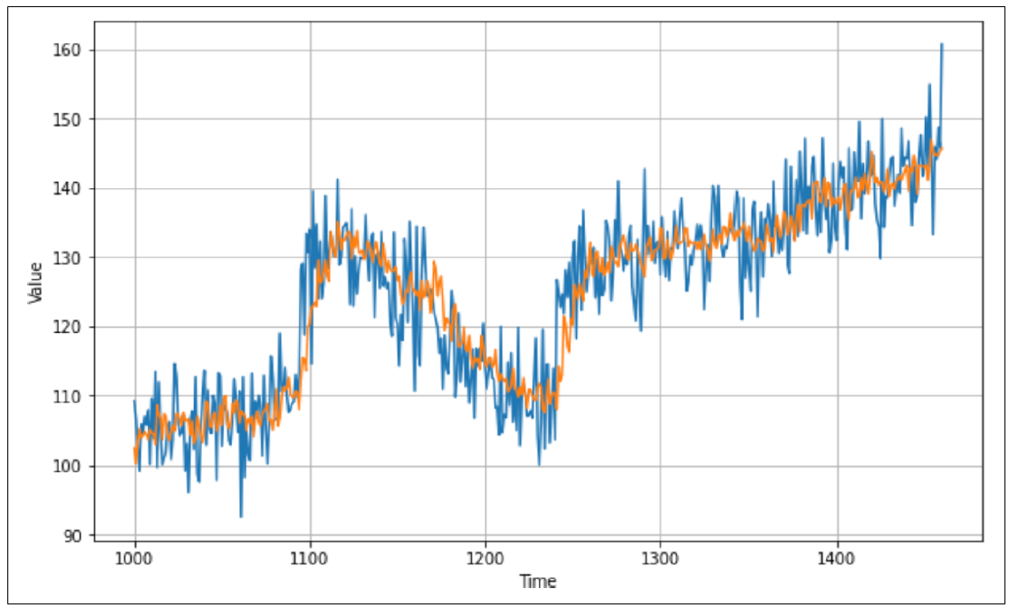
图 10-3:将预测结果与真实值进行对比
从图中可以直观地看到预测结果表现不错,整体上跟随了原始数据的曲线。当数据中出现快速变化时,预测可能需要一些时间来追赶,但总体表现还可以。
然而,仅靠观察曲线很难精确评估效果。最好用一个好的指标进行衡量。在第 9 章中你学到了一个指标——MAE(平均绝对误差)。现在你有了验证数据和预测结果,可以使用如下代码来计算 MAE:
tf.keras.metrics.mean_absolute_error(x_valid, results).numpy()
由于数据中引入了随机性,你的结果可能会有所不同。但我尝试后得到了一个 MAE 值为 4.51。
可以说,尽可能提高预测准确度的过程,其实就是尽量最小化 MAE 的过程。你可以通过一些技术来实现,比如调整窗口大小。我将这个任务留给你自行探索。在下一节中,我们将通过对优化器进行基本的超参数调优来改善神经网络的学习效果,并观察这对 MAE 有什么影响。
总结:本篇内容主要探讨了如何评估人工智能模型的性能。通过预测一个点的值,并使用验证数据集进行对比,观察预测结果和真实值的吻合程度。还展示了利用窗口化数据集,结合循环预测每个时间步的方式,生成整体预测结果。最后通过计算 MAE(平均绝对误差)来量化模型的表现,并提出调整窗口大小等方法进一步优化模型预测精度,为后续的超参数调优打下基础。

