
人工智能语言模型起源全景探究:终章。

上一篇:《人工智能规模法则的起源、分析、内幕以及对齐方法》
(18)《人工智能的宪法:用AI的反馈来确保AI的无害性》(2022年),作者:Yuntao、Saurav、Sandipan、Amanda、Jackson、Jones、Chen、Anna、Mirhoseini、McKinnon、Chen、Olsson、Olah、Hernandez、Drain、Ganguli、Li、Tran-Johnson、Perez、Kerr、Mueller、Ladish、Landau、Ndousse、Lukosuite、Lovitt、Sellitto、Elhage、Schiefer、Mercado、DasSarma、Lasenby、Larson、Ringer、Johnston、Kravec、El Showk、Fort、Lanham、Telleen-Lawton、Conerly、Henighan、Hume、Bowman、Hatfield-Dodds、Mann、Amodei、Joseph、McCandlish、Brown、Kaplan,网址:https://arxiv.org/abs/2212.08073。
在这篇论文中,研究人员将对齐的概念推向了一个新高度,提出了一种训练机制,用于创建“无害”的AI系统。研究人员并非直接通过人类监督,而是提出了一种基于规则清单的自我训练机制(这些规则由人类提供)。与上述提到的InstructGPT论文类似,所提出的方法也使用了强化学习的方式。

来源: https://arxiv.org/abs/2212.08073
(19)《Self-Instruct: Aligning Language Model with Self Generated Instruction (2022)》(2022年),作者:Wang、Kordi、Mishra、Liu、Smith、Khashabi 和 Hajishirzi,网址:https://arxiv.org/abs/2212.10560
指令微调是我们将类似GPT-3的预训练基础模型变得更强大,像ChatGPT这样的更强大LLM(大型语言模型)就得通过这个过程。而像databricks-dolly-15k这样的开源人类生成的指令数据集也可以帮助实现这一目标。那么,如何扩展这个过程呢?其中一种方法是通过自我生成来引导LLM。
Self-Instruct就是一种几乎不需要注释的方式来将预训练的LLM与指令对齐。
这个方法是怎么运作的呢?简而言之,它是一个四步过程:
-
用一组人类编写的指令(此处为175个)来初始化任务池,并采样指令。
-
使用预训练的LLM(如GPT-3)来确定任务类别。
-
给定新的指令,让预训练的LLM生成回答。
-
在将生成的回答加入任务池之前,收集、修剪和筛选这些回答。
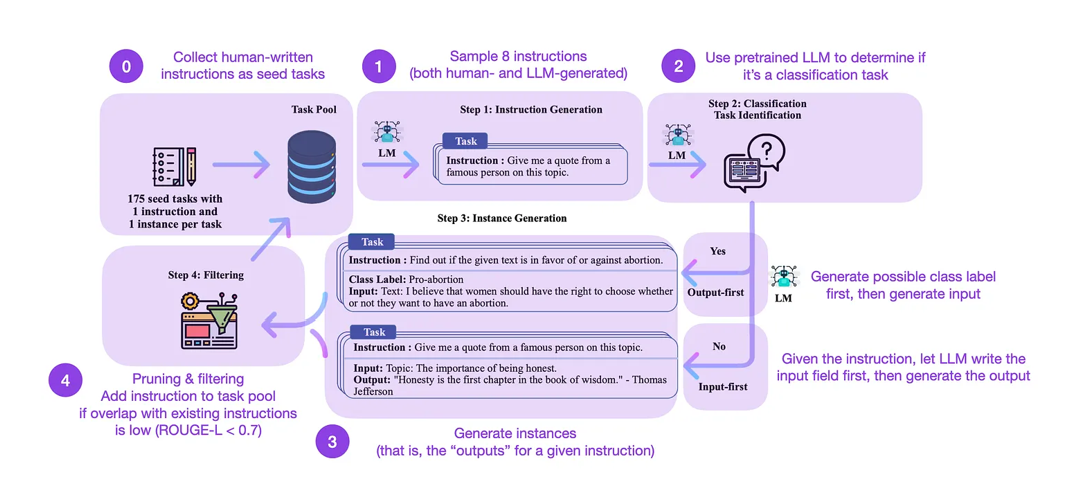
自我指导方法的注释版本来自https://arxiv.org/abs/2212.10560。
实际上,根据ROUGE评分,这个方法效果相对不错。
举个例子,一个经过Self-Instruct微调的LLM比GPT-3基础版LLM(1)表现更好,并且能够与在大型人类编写指令集上预训练的LLM(2)竞争。而Self-Instruct也能对已经在人工指令上微调过的LLM(3)有所帮助。
但当然,评估LLM的金标准是通过人类评分。根据人类评估,Self-Instruct优于基础LLM,并且超越了用人工指令数据集进行监督训练的LLM(如SuperNI,T0 Trainer)。但有趣的是,Self-Instruct并没有超过通过人类反馈强化学习(RLHF)训练的方法。
那么,更有前景的是人工生成的指令数据集还是自我指令数据集呢?我支持两者。为什么不先从像databricks-dolly-15k的15k个人工指令数据集开始,然后再用Self-Instruct进行扩展呢?
结论与进一步阅读
我尽量保持上面的列表简洁明了,专注于理解当代大型语言模型背后的设计、约束和演变,列出了前10篇重要论文(加上3篇关于RLHF的额外论文)。
如果想进一步阅读,我建议跟随上述论文中的参考文献。或者,为了给你提供一些额外的指引,下面是一些附加资源(这些列表并不全面):
GPT的开源替代品
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model (2022), https://arxiv.org/abs/2211.05100
OPT: Open Pre-trained Transformer Language Models (2022), https://arxiv.org/abs/2205.01068
UL2: Unifying Language Learning Paradigms (2022), https://arxiv.org/abs/2205.05131
ChatGPT的替代品
LaMDA: Language Models for Dialog Applications (2022), https://arxiv.org/abs/2201.08239
(Bloomz) Crosslingual Generalization through Multitask Finetuning (2022), https://arxiv.org/abs/2211.01786
(Sparrow) Improving Alignment of Dialogue Agents via Targeted Human Judgements (2022), https://arxiv.org/abs/2209.14375
BlenderBot 3: A Deployed Conversational Agent that Continually Learns to Responsibly Engage, https://arxiv.org/abs/2208.03188
计算生物学中的大型语言模型
ProtTrans: Towards Cracking the Language of Life’s Code Through Self-Supervised Deep Learning and High Performance Computing (2021), https://arxiv.org/abs/2007.06225
Highly Accurate Protein Structure Prediction with AlphaFold (2021), https://www.nature.com/articles/s41586-021-03819-2
Large Language Models Generate Functional Protein Sequences Across Diverse Families (2023), https://www.nature.com/articles/s41587-022-01618-2

