人工智能大语言模型起源篇,低秩微调(LoRA)

上一篇: 《规模法则(Scaling Law)与参数效率的提高》
序言:您在找工作时会不会经常听到LoRA微调,这项技术的来源就是这里了。
(12)Hu、Shen、Wallis、Allen-Zhu、Li、L Wang、S Wang 和 Chen 于2021年发表的《LoRA: Low-Rank Adaptation of Large Language Models》,https://arxiv.org/abs/2106.09685
现代的大型语言模型在大数据集上进行预训练后,展现了突现能力,并且在多种任务中表现优异,包括语言翻译、总结、编程和问答。然而,如果我们希望提升变换器在特定领域数据和专业任务上的能力,微调变换器是非常值得的。
低秩适配(LoRA)是微调大型语言模型的一种非常有影响力的方法,它具有参数高效的特点。虽然还有其他一些参数高效的微调方法(见下文的综述),但LoRA特别值得一提,因为它既优雅又非常通用,可以应用于其他类型的模型。
虽然预训练模型的权重在预训练任务上是全秩的,但LoRA的作者指出,当预训练的大型语言模型适配到新任务时,它们具有低“内在维度”。因此,LoRA的核心思想是将权重变化(ΔW)分解成低秩表示,这样可以更高效地使用参数。

LoRA 的示例及其性能来自 https://arxiv.org/abs/2106.09685。
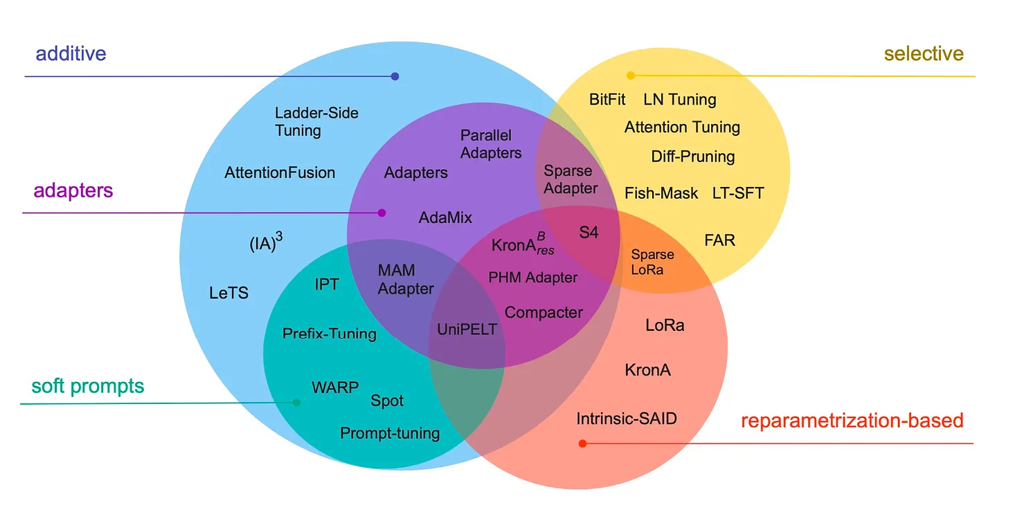
(13)Lialin、Deshpande 和 Rumshisky 于2022年发表的《Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning》,https://arxiv.org/abs/2303.15647
现代的大型语言模型在大数据集上进行预训练后,展现了突现能力,并且在多种任务中表现优异,包括语言翻译、总结、编程和问答。然而,如果我们希望提升变换器在特定领域数据和专业任务上的能力,微调变换器是非常值得的。本文综述了40多篇关于参数高效微调方法的论文(包括前缀调优、适配器、低秩适配等流行技术),旨在使微调过程(变得)更加高效,尤其是在计算上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号