搭建人工智能多模态大语言模型的通用方法

上一篇:《理解多模态大语言模型,主流技术与最新模型简介》
序言:动手搭建建多模态LLM的两大通用主流方法是:统一嵌入-解码器架构和跨模态注意力架构,它们都是通过利用图像嵌入与投影、跨注意力机制等技术来实现的。
- 构建多模态 LLM 的常见方法
构建多模态 LLM(大型语言模型)主要有两种方法:
方法 A:统一嵌入-解码器架构 (Unified Embedding Decoder Architecture)
方法 B:跨模态注意力架构 (Cross-modality Attention Architecture)
(顺便说一下,我觉得目前这些技术还没有官方的标准术语,如果你听说过什么官方叫法的话,也请告诉我。比如说,简短一点的描述可能就是“纯解码器结构(decoder-only)”和“基于交叉注意力(cross-attention-based)”的两种方法。)

这两种开发多模态 LLM 架构的主要途径
上面这张图展示了两种主要方法。第一种统一嵌入-解码器架构使用的是单一的解码器模型,就像一个没怎么改过的 LLM 架构,比如 GPT-2 或 Llama 3.2。在这种方法里,图像会被转成和文本 token 一样大小的嵌入向量,然后 LLM 会把文本和图像的输入 token 串起来一起处理。
而跨模态注意力架构则是在注意力层里用跨注意力机制来直接融合图像和文本的嵌入。
接下来几节,我们会先在概念层面探讨这些方法是怎么工作的,然后看看最近的一些论文和研究,看看这些方法在实际中是怎么用的。
2.1 方法 A:统一嵌入-解码器架构
咱们先从统一嵌入-解码器架构说起,下面这张图又重新画了这个架构。
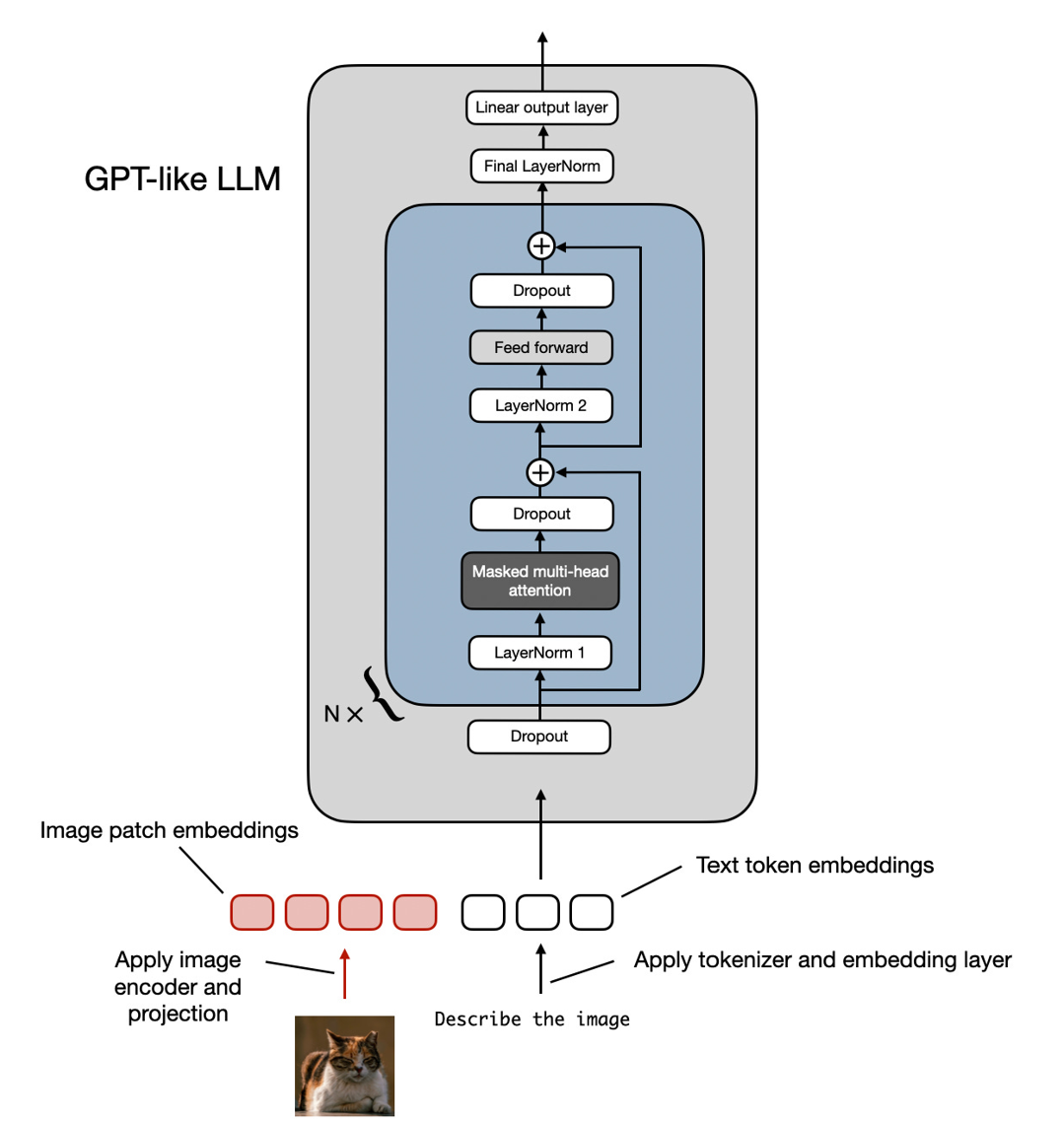
图示:统一嵌入-解码器架构,也就是一个未修改过的解码器风格 LLM(比如 GPT-2、Phi-3、Gemma 或者 Llama 3.2),它接收的输入是包括了图像 token 和文本 token 的嵌入。
在这种统一嵌入-解码器架构中,一张图像会被转成一串嵌入向量,就像在标准的文本 LLM 里文本被转成嵌入向量那样。
对一个典型的纯文本 LLM 来说,处理文本时通常会先把文本分词(比如用 BPE),然后送进一个嵌入层,如下图所示。

图示:标准的文本分词和转成 token 嵌入的流程,然后在训练和推理时,这些嵌入会传给 LLM。
2.1.1 理解图像编码器 (Image encoders)
就像文本在送进 LLM 前要分词和嵌入一样,图像的嵌入是通过图像编码器模块(而不是分词器)来搞定的,如下图所示。

图示:把图像编码成图像 patch 的嵌入的过程。
上面这个图里,图像处理的流程是啥?基本上就是先把图像分成好几块小 patch,就像分词把单词拆成子词,然后用一个预训练的视觉 Transformer(ViT)来对这些小块进行编码,就像下面这张图演示的一样。

图示:经典的 Vision Transformer (ViT) 架构,类似 2020 年那篇 “An Image is Worth 16x16 Words” 里的模型。
注意,ViT 通常用来做分类任务,所以上面那张图里还画了个分类头。但是这里我们只需要用到图像编码器那一部分就行了。
2.1.2 线性投影模块 (linear projection) 的作用
前面图里提到的“linear projection”(线性投影)就是一层全连接的线性层。它的目的就是把图像的 patch(已经展平成一个向量)投影到和 Transformer 编码器匹配的嵌入维度中。这在下图中演示了。一个图像 patch,原本展平后是 256 维,会被升维到 768 维的向量。

图示:线性投影层把展平的图像 patch 从 256 维投影到 768 维嵌入空间。
如果你想看代码示例的话,用 PyTorch 可以这样写这层线性投影:
import torch
class PatchProjectionLayer(torch.nn.Module):
def init(self, patch_size, num_channels, embedding_dim):
super().init()
self.patch_size = patch_size
self.num_channels = num_channels
self.embedding_dim = embedding_dim
self.projection = torch.nn.Linear(
patch_size * patch_size * num_channels, embedding_dim
)
def forward(self, x):
batch_size, num_patches, channels, height, width = x.size()
x = x.view(batch_size, num_patches, -1) # 把每个patch展平
x = self.projection(x) # 投影
return x
使用示例
batch_size = 1
num_patches = 9 # 每张图像的patch数
patch_size = 16 # 每个patch是16x16像素
num_channels = 3 # RGB图像
embedding_dim = 768 # 嵌入向量维度
projection_layer = PatchProjectionLayer(patch_size, num_channels, embedding_dim)
patches = torch.rand(
batch_size, num_patches, num_channels, patch_size, patch_size
)
projected_embeddings = projection_layer(patches)
print(projected_embeddings.shape)
输出: torch.Size([1, 9, 768])
如果你看过我那本《Machine Learning Q and AI》书,你可能知道可以用卷积来代替线性层,数学上等价的实现也有。这种方法在这里很有用,因为可以用两行代码就同时实现patch的创建和投影:
layer = torch.nn.Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))
image = torch.rand(batch_size, 3, 48, 48)
projected_patches = layer(image)
print(projected_patches.flatten(-2).transpose(-1, -2).shape)
输出:torch.Size([1, 9, 768])
2.1.3 图像和文本的分词对比 (Image vs text tokenization)
咱们已经大概说了图像编码器和线性投影的用途,现在再回头看看文本分词的类比。下图展示了图像和文本的分词与嵌入过程的对比。

图示:左边是图像的分块和嵌入,右边是文本的分词和嵌入,对比放一起。
你可以看到上面那张图里,我还放了个额外的投影器(projector)模块在图像编码器后面。这玩意儿一般就是另一层线性投影(和刚才说的差不多)。它的目的是把图像编码器输出的维度调整到和文本 token 嵌入同样的维度,如下图所示。(后面我们会看到,这个 projector 有时候也叫 adapter、adaptor 或 connector。)

图示:再对比一次,图像和文本的分词过程。这里 projector 的作用就是让图像 token 嵌入的维度和文本 token 嵌入的维度匹配。
现在图像 patch 的嵌入维度和文本 token 嵌入维度相同了,我们就可以把它们简单地拼接起来,作为输入给 LLM,如下图开头时候展示的那样。下面是同样的图,方便你对照。

图示:在把图像 patch token 投影到和文本 token 嵌入相同的维度后,我们就能轻松地把它们拼接在一起,送进标准的 LLM。
顺便说一句,这里用到的图像编码器通常是一个预训练的 Vision Transformer,比如 CLIP 或 OpenCLIP。
不过,也有一些使用方法 A 的模型是直接处理图像 patch 的,比如 Fuyu,就不需要额外的图像编码器。看下图:

图示:Fuyu 多模态 LLM 的示意图。它直接对图像 patch 进行处理,不需要独立的图像编码器。(图片出自 https://www.adept.ai/blog/fuyu-8b,已做标注。)
上图中可以看到,Fuyu 是直接把输入的图像patch送进线性投影(或者embedding层)中,自学自己的图像 patch 嵌入,而不像其他方法那样依赖一个已经预训练好的图像编码器。这让架构和训练流程更简化。
2.2 方法 B:跨模态注意力架构 (Cross-Modality Attention Architecture)
现在我们已经讨论了统一嵌入-解码器架构(方法 A),并理解了图像编码的基本概念,让我们来看看另一种实现多模态 LLM 的方法——用跨注意力机制,如下图总结所示。

图示:跨模态注意力架构方法的示意图。
在上面的跨模态注意力架构中,我们依然使用之前讨论过的图像编码器设置。但与把图像的patch嵌入作为LLM输入不同,这里是在多头注意力层中通过跨注意力机制把图像信息接入进来。
这个点子其实和最初的 transformer 架构有关系,也就是 2017 年那篇 “Attention Is All You Need” 论文中使用的机制。下面的图高亮了这一点。

图示:最初的 Transformer 架构里使用的跨注意力机制。(图片来自“Attention Is All You Need”论文:https://arxiv.org/abs/1706.03762,有标注)
注意,最初的 Transformer 是用来做语言翻译的,所以它有一个文本编码器(图的左半部分)和一个文本解码器(图的右半部分)。在多模态 LLM 的场景下,这里的“编码器”就是图像编码器,而不是文本编码器,但原理是一样的。
跨注意力是怎么工作的?让我们先看一下常规自注意力(self-attention)是啥样。下图是自注意力机制的示意图。

图示:常规自注意力机制的流程。(这里展示的是多头注意力中的一个注意力头的处理流程)
上面这张图里,x 是输入,Wq 是生成查询(Q)的权重矩阵,同理 K 是 keys 的权重,V 是 values 的权重。A 是注意力分数矩阵,Z 是最终的上下文向量输出。(如果你觉得这有点绕,可以参考我《Build a Large Language Model from Scratch》这本书的第3章,或者看看我的文章《Understanding and Coding Self-Attention, Multi-Head Attention, Cross-Attention, and Causal-Attention in LLMs》。)
在跨注意力(cross-attention)里,不同于自注意力只有一个输入序列,我们会有两个不同的输入源,如下图示意。

图示:跨注意力(cross-attention)的示意图,有两个不同的输入 x1 和 x2
在自注意力中,输入序列是同一个。在跨注意力中,我们是把两个不同的输入序列混合起来。
在最初的 Transformer 架构中,x1 和 x2 对应的是左边编码器输出的序列(x2)以及右边解码器正在处理的输入序列(x1)。在多模态 LLM 的场景中,x2 就是图像编码器的输出。(一般来说,query 来自解码器,而 key 和 value 来自编码器。)
要注意的是,在跨注意力中,这两个输入序列 x1 和 x2 可以有不同的长度。但它们的嵌入维度必须相同。如果我们让 x1 = x2,那其实就又退化回自注意力了。
总结:本文详细介绍了构建多模态大语言模型的两种主流方案:统一嵌入-解码器架构和跨模态注意力架构,并说明了图像编码与投影在文本-图像融合中的关键作用。通过对基础概念、典型实现方式及现有研究进行分析,读者可初步了解多模态LLM的设计思路和技术路径。下一篇将重点探讨如何为这两类架构的方法实际训练多模态大语言模型,以期在实践中取得更高效、更稳定的性能表现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号