

人工智能是这样理解“情绪”的

前一篇:《人工智能模型训练:从不同格式文件中读取训练数据集》
前言:在前面的内容中,我们经常提到“特征”,那么如何表示特征呢?举个例子,在日常生活中,我们描述一个快递包装盒时可能会提到它的高度、宽度和深度(这三个值就是盒子的特征,当然也可以用颜色、重量、材料等来描述)。当我们仅用高度、宽度和深度三个数据来描述盒子的特征时,我们就说这个盒子的特征是三维的。如果再加上颜色、重量和材料等特征,那么这个特征空间就是六维的了。
在前面的三篇中,我们学到了如何将单词编码成数值(即令牌)。然后又学会了如何将包含多个单词的句子编码成一系列的令牌,并通过填充或截断的方式得到一个适用于神经网络训练的形状良好的数据集。然而,这其中并未涉及任何对单词含义的建模。尽管没有绝对的数值编码可以完全概括单词的含义,但却有相对的编码方式。在接下来的知识中,我们将学习这些编码方式,特别是嵌入的概念,即在高维空间中创建向量来表示单词。这些向量的方向可以随着单词在语料中的使用逐渐被学习出来。之后,当你得到一句话时,可以分析单词向量的方向,将它们相加,从相加结果的整体方向来判断句子的情感,作为单词的产物。
在本知识中,我们将探讨这种方法的工作原理。借助前面几节中的“讽刺”数据集,你将构建嵌入,帮助模型识别句子中的讽刺情感。你还会看到一些很酷的可视化工具,帮助你了解语料库中的单词如何映射为向量,让你看到哪些单词决定了整体的分类。
从单词中建立意义
在进入用于嵌入的高维向量之前,让我们用一些简单的例子来尝试可视化如何通过数值推导出意义。考虑这样一个情况:使用前面几节中的“讽刺”数据集,如果你将组成讽刺标题的所有单词编码为正数,而将现实标题的单词编码为负数,会发生什么?
举一个简单的例子:正数与负数
例如,看看数据集中的这个感觉讽刺情绪的标题:
christian bale given neutered male statuette named Oscar
假设我们词汇表中的所有单词初始值都为0,我们可以将这个句子中的每个单词的值加1,最终得到:
{ "christian" : 1, "bale" : 1, "given" : 1, "neutered": 1, "male" : 1, "statuette": 1, "named" : 1, "oscar": 1}
注意,这并不是上一节中你所做的单词令牌化。你可以考虑将每个单词(例如“christian”)替换为语料库中代表它的令牌,但我会将单词保留在这里,以便于阅读。
然后,考虑一个普通的非讽刺情绪的标题,例如:
gareth bale scores wonder goal against germany
由于这是不同的情感,我们可以改为从每个单词的当前值中减去1,因此我们的值集将如下所示:
{ "christian" : 1, "bale" : 0, "given" : 1, "neutered": 1, "male" : 1, "statuette": 1, "named" : 1, "oscar": 1, "gareth" : -1, "scores": -1, "wonder" : -1, "goal" : -1, "against" : -1, "germany" : -1}
注意,讽刺的“bale”(来自“christian bale”)被非讽刺的“bale”(来自“gareth bale”)抵消了,因此它的分数最终为0。重复这一过程数千次后,你将得到一个庞大的语料库单词列表,根据它们的使用情况进行评分。
现在,假设我们想要判断以下句子的情感:
neutered male named against germany, wins statuette!
使用我们现有的值集,我们可以查看每个单词的分数并将它们相加。我们得到的总分为2,表示(因为这是一个正数)这是一个讽刺句子。
顺带一提,“bale”在讽刺数据集中被使用了五次,其中两次出现在普通标题中,三次出现在讽刺标题中,因此在这样的模型中,“bale”在整个数据集中的得分将是-1。
一个简单的例子:正数与负数
举个例子,看看数据集中的这个讽刺标题:
“克里斯蒂安·贝尔获得一座名为奥斯卡的去势男性雕像”
假设我们词汇表中的所有单词初始值都为0,我们可以将这个句子中的每个单词的值加1,最终得到:
{ "christian" : 1, "bale" : 1, "given" : 1, "neutered": 1, "male" : 1, "statuette": 1, "named" : 1, "oscar": 1}
注意,这并不是上一节中你所做的单词令牌化。你可以考虑将每个单词(比如“christian”)替换为语料库中代表它的令牌,但我会将单词保留在这里,以便于阅读。
接着,我们来考虑一个普通的非讽刺标题,例如:
gareth bale scores wonder goal against germany
因为这是不同的情感,我们可以从每个单词的当前值中减去1,因此我们的值集会变成这样:
{ "christian" : 1, "bale" : 0, "given" : 1, "neutered": 1, "male" : 1, "statuette": 1, "named" : 1, "oscar": 1, "gareth" : -1, "scores": -1, "wonder" : -1, "goal" : -1, "against" : -1, "germany" : -1}
注意,讽刺的“bale”(来自“christian bale”)被非讽刺的“bale”(来自“gareth bale”)抵消了,因此它的分数最终为0。重复这一过程数千次后,你将得到一个庞大的语料库单词列表,根据它们的使用情况进行评分。
现在,假设我们想要判断以下句子的情感:
neutered male named against germany, wins statuette!
使用我们现有的值集,我们可以查看每个单词的分数并将它们相加。我们得到的总分为2,表示(因为这是一个正数)这是一个讽刺句子。
顺带一提,“bale”在讽刺数据集中被使用了五次,其中两次出现在普通标题中,三次出现在讽刺标题中,因此在这样的模型中,“bale”在整个数据集中的得分将是-1。
向量
希望前面的例子帮助你理解了通过将单词与同一“方向”中的其他单词关联,来为单词建立某种相对意义的思维模型。在我们的例子中,尽管计算机并不理解单个单词的意义,但它可以将来自已知讽刺标题的令牌单词向一个方向移动(加1),而将来自已知正常标题的令牌单词向另一个方向移动(减1)。这给了我们对单词意义的基本理解,但确实会丢失一些细微之处。
如果我们增加方向的维度以尝试捕捉更多的信息会怎么样?例如,假设我们看一下简·奥斯汀小说《傲慢与偏见》中的人物,考虑性别和贵族维度。我们可以将性别映射到x轴,贵族身份映射到y轴,并用向量的长度表示每个人物的财富(图6-1)。
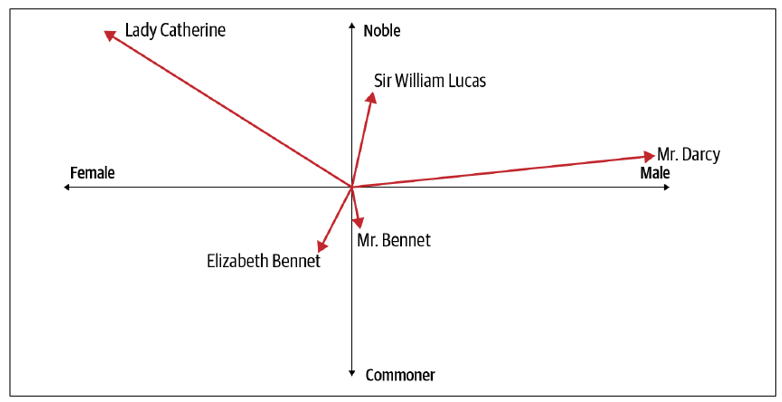
图6-1. 《傲慢与偏见》中的人物作为向量
从图中我们可以推测出每个人物的相当多的信息。三个人是男性。达西先生非常富有,但他的贵族身份不明确(他被称为“先生”,而不是像威廉·卢卡斯爵士那样的贵族称号)。另一位“先生”本内特先生显然不是贵族,且经济困难。本内特先生的女儿伊丽莎白与他类似,但性别不同。示例中的另一位女性角色凯瑟琳夫人是贵族,且非常富有。达西先生与伊丽莎白之间的爱情造成了紧张关系——偏见来自向量中贵族方向对非贵族的偏见。
这个例子表明,通过考虑多个维度,我们可以开始看到单词(这里是人物名称)中的真实意义。我们并不是在谈论具体的定义,而是基于坐标轴以及一个单词的向量与其他向量之间的关系,得出相对的意义。
这就引出了嵌入的概念,即在训练神经网络的过程中学习的单词的向量表示。我们将在接下来的部分探讨这个概念。
总结:本章深入探讨了如何通过多维空间的向量表示来构建和理解特征。在前面的内容中,我们学习了如何将单词编码成数值(令牌)并构建适合神经网络训练的数据集。然而,这些编码方式尚未涉及单词的实际含义。通过引入嵌入的概念,我们可以在高维空间中用向量表示单词,捕捉其相对意义。
为解释嵌入的工作原理,文中提供了一个使用讽刺数据集的示例:为不同情感的句子分别赋予正数和负数值,通过累加词向量来判断整体情感。这种方法模拟了不同情感间的偏移效果。此外,通过借助《傲慢与偏见》中的人物关系例子,展示了如何在多个维度中表示特征,如性别、贵族身份和财富,以便更丰富地体现含义。整体上,嵌入向量的引入使我们能够从数据中捕捉出单词间的相对关系与含义。
这为后续神经网络训练中的词向量学习打下了基础。

