摘要:  作者:Agam Johal 除特别注明外,所有图片由 AI 生成 博文概览:这篇文章探讨了一个正在逼近现实的未来情境:随着脑机接口、整体脑模拟(WBE)等技术的发展,人类心智上传从科幻走向了可行。在这个背景下,作者提出了一个核心问题:当你的意识可以被复制,新的“你”出现时,原本的你是谁?副本又算什么 阅读全文
作者:Agam Johal 除特别注明外,所有图片由 AI 生成 博文概览:这篇文章探讨了一个正在逼近现实的未来情境:随着脑机接口、整体脑模拟(WBE)等技术的发展,人类心智上传从科幻走向了可行。在这个背景下,作者提出了一个核心问题:当你的意识可以被复制,新的“你”出现时,原本的你是谁?副本又算什么 阅读全文
作者:Agam Johal 除特别注明外,所有图片由 AI 生成 博文概览:这篇文章探讨了一个正在逼近现实的未来情境:随着脑机接口、整体脑模拟(WBE)等技术的发展,人类心智上传从科幻走向了可行。在这个背景下,作者提出了一个核心问题:当你的意识可以被复制,新的“你”出现时,原本的你是谁?副本又算什么 阅读全文
posted @ 2025-04-06 11:46
果冻人工智能
阅读(348)
评论(1)
推荐(0)
 坏掉的放大镜。图片由作者提供。 向量搜索纸面上看起来很简单——把一些嵌入丢进数据库,查询一下,砰,结果就出来了。但一旦你从玩票项目跳进真实应用,你会很快发现这种“魔法”变成了一个充满地雷的战场——云费用爆炸、莫名其妙的幻觉、还有完全偏离目标的搜索。我见过团队在“优化”流程上耗上好几周,结果还是被同样
坏掉的放大镜。图片由作者提供。 向量搜索纸面上看起来很简单——把一些嵌入丢进数据库,查询一下,砰,结果就出来了。但一旦你从玩票项目跳进真实应用,你会很快发现这种“魔法”变成了一个充满地雷的战场——云费用爆炸、莫名其妙的幻觉、还有完全偏离目标的搜索。我见过团队在“优化”流程上耗上好几周,结果还是被同样  MCP 现在真的火起来了。现在已经有成千上万个 MCP “服务器”,而且虽然是 Anthropic 发明的,就在几天前 OpenAI 也采纳了它。服务器就像 AI 的 “应用”,但关键在于它们可以更灵活地协同使用。我们正看到 AI 生态系统的雏形,就像十年前我们看到移动生态一样。 详情:MCP(Mo
MCP 现在真的火起来了。现在已经有成千上万个 MCP “服务器”,而且虽然是 Anthropic 发明的,就在几天前 OpenAI 也采纳了它。服务器就像 AI 的 “应用”,但关键在于它们可以更灵活地协同使用。我们正看到 AI 生态系统的雏形,就像十年前我们看到移动生态一样。 详情:MCP(Mo  前言:这篇文章写给所有正在互联网广告、市场营销、商业策略和产品决策一线打拼的人。如果你所在的公司正在探索如何用 AI 提高广告转化、降低投放成本,或者你对 Meta、LLM、个性化推荐这些关键词有浓厚兴趣——那么这篇文章你值得读一读。 当然,如果你不是这些岗位的从业者,但对 AI 如何改变商业模式、
前言:这篇文章写给所有正在互联网广告、市场营销、商业策略和产品决策一线打拼的人。如果你所在的公司正在探索如何用 AI 提高广告转化、降低投放成本,或者你对 Meta、LLM、个性化推荐这些关键词有浓厚兴趣——那么这篇文章你值得读一读。 当然,如果你不是这些岗位的从业者,但对 AI 如何改变商业模式、  作者:Derek McBurney 这会是你公司的下一个高级程序员吗?图源:Emilipothèse Anthropic 的 CEO 说,AI 在 3 到 6 个月内将写出 90% 的代码。他说出这种话是有很强的动机的——数字和时间线都这么惊人,这种说法很可能又是一个被炒作的噱头,在这个行业里这种现
作者:Derek McBurney 这会是你公司的下一个高级程序员吗?图源:Emilipothèse Anthropic 的 CEO 说,AI 在 3 到 6 个月内将写出 90% 的代码。他说出这种话是有很强的动机的——数字和时间线都这么惊人,这种说法很可能又是一个被炒作的噱头,在这个行业里这种现  作者:Ignacio de Gregorio 图片来自 Unsplash 的 Bahnijit Barman 几周前,我们看到 Anthropic 尝试训练 Claude 去通关宝可梦。模型是有点进展,但离真正通关还差得远。 但现在,一个独立的小团队用一个只有一千万参数的模型通关了宝可梦,比主流前沿
作者:Ignacio de Gregorio 图片来自 Unsplash 的 Bahnijit Barman 几周前,我们看到 Anthropic 尝试训练 Claude 去通关宝可梦。模型是有点进展,但离真正通关还差得远。 但现在,一个独立的小团队用一个只有一千万参数的模型通关了宝可梦,比主流前沿  作者:朱莉·卓 一前几天,一位著名亿万富翁在毕业典礼上发表了演讲。核心信息?努力工作,才能成功。一年后,另一位著名亿万富翁也在毕业典礼上演讲。核心信息?努力工作是糟糕的建议。做让你觉得有趣的事,才能成功。 欧洲人嘲笑美国人太拼命。婴儿潮一代感慨千禧一代懒散且自以为是。共和党人怒斥美国的立国之本——勤
作者:朱莉·卓 一前几天,一位著名亿万富翁在毕业典礼上发表了演讲。核心信息?努力工作,才能成功。一年后,另一位著名亿万富翁也在毕业典礼上演讲。核心信息?努力工作是糟糕的建议。做让你觉得有趣的事,才能成功。 欧洲人嘲笑美国人太拼命。婴儿潮一代感慨千禧一代懒散且自以为是。共和党人怒斥美国的立国之本——勤  作者:Kollibri terre Sonnenblume 公有领域艺术作品,作者提供,来自公共领域元素。 **前言: **如果你不想阅读完整篇,这里是本篇的作者的核心观点:人工智能(AI)虽然在技术上有巨大的潜力,但它对环境的负面影响极其严重,可能加剧当前面临的多重危机,如气候变化、资源枯竭、污染
作者:Kollibri terre Sonnenblume 公有领域艺术作品,作者提供,来自公共领域元素。 **前言: **如果你不想阅读完整篇,这里是本篇的作者的核心观点:人工智能(AI)虽然在技术上有巨大的潜力,但它对环境的负面影响极其严重,可能加剧当前面临的多重危机,如气候变化、资源枯竭、污染  作者:Laurel W 来源:Adobe 作为一名数据科学和数学老师,我其实不介意我的学生使用像 ChatGPT 这样的 LLM,只要它是用来辅助他们学习,而不是取代学习过程。加州理工学院的申请文书指南启发了我为编程和机器学习课制定 AI 使用政策: 哪些是加州理工申请文书中不道德的 AI 使用方式
作者:Laurel W 来源:Adobe 作为一名数据科学和数学老师,我其实不介意我的学生使用像 ChatGPT 这样的 LLM,只要它是用来辅助他们学习,而不是取代学习过程。加州理工学院的申请文书指南启发了我为编程和机器学习课制定 AI 使用政策: 哪些是加州理工申请文书中不道德的 AI 使用方式  诺米·科托博士(Normi Coto, PhD) 配图来自 Unsplash 的 Element5 Digital 3 月 15 日星期六,我参加了一场名为“人文学科中的 AI”的职业发展工作坊。会场人满为患,坐满了来自弗吉尼亚州中学和高中的英语和历史老师。来自弗吉尼亚大学和朗伍德大学的教授主持了这
诺米·科托博士(Normi Coto, PhD) 配图来自 Unsplash 的 Element5 Digital 3 月 15 日星期六,我参加了一场名为“人文学科中的 AI”的职业发展工作坊。会场人满为患,坐满了来自弗吉尼亚州中学和高中的英语和历史老师。来自弗吉尼亚大学和朗伍德大学的教授主持了这  Sam Liberty 《Citizen Sleeper 2》(2025)开发者:Jump Over The Age 还记得你第一次玩《Citizen Sleeper》的时候吗?如果不记得,那你真是错过了。真的。 来看看这个场景:你是个逃亡中的人造人。你在一座熙熙攘攘的太空站醒来,耳边是机器环境音持
Sam Liberty 《Citizen Sleeper 2》(2025)开发者:Jump Over The Age 还记得你第一次玩《Citizen Sleeper》的时候吗?如果不记得,那你真是错过了。真的。 来看看这个场景:你是个逃亡中的人造人。你在一座熙熙攘攘的太空站醒来,耳边是机器环境音持 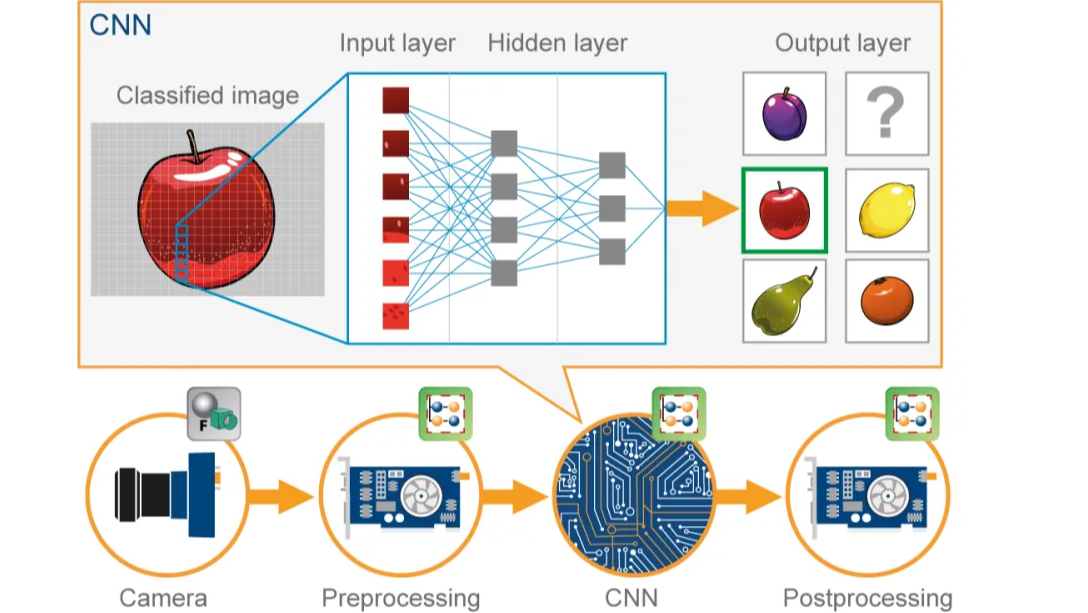 作者:Vishal Rajput 前言: 本文作者以一种极具人文关怀的视角,从 AI 的发展历程切入,逐层揭示出当下技术狂奔背后隐藏的伦理隐患、社会裂痕与意义危机。他大胆质疑权力精英在 AI 发展中的动机,也对超级智能可能带来的“文明结构性瓦解”发出警告。这不是一篇介绍模型原理的科普文,也不是一次未
作者:Vishal Rajput 前言: 本文作者以一种极具人文关怀的视角,从 AI 的发展历程切入,逐层揭示出当下技术狂奔背后隐藏的伦理隐患、社会裂痕与意义危机。他大胆质疑权力精英在 AI 发展中的动机,也对超级智能可能带来的“文明结构性瓦解”发出警告。这不是一篇介绍模型原理的科普文,也不是一次未  David Rodenas 博士 「你本该听卡珊德拉的」由作者生成。 几周前,The Friday Checkout(TechAltar)在 Nebula 的问答节目中收到一个问题:“你认为欧洲能追上 AI 吗?”他的回答简而言之是:“AI 不行,欧洲应该投资汽车产业”,但我觉得他错了。事实是,欧洲
David Rodenas 博士 「你本该听卡珊德拉的」由作者生成。 几周前,The Friday Checkout(TechAltar)在 Nebula 的问答节目中收到一个问题:“你认为欧洲能追上 AI 吗?”他的回答简而言之是:“AI 不行,欧洲应该投资汽车产业”,但我觉得他错了。事实是,欧洲  Techscribe Central 缩略图由 Techscribe Central 制作和编辑 MCP!!是不是一头雾水?我当时也是这个反应。我也是最近才听说它开始引发关注,然后我发现大多数人根本不知道它是什么。起初我心想,“太好了,又一个 AI 缩写得去弄明白。MCP 满天飞,我还以为只是又一个
Techscribe Central 缩略图由 Techscribe Central 制作和编辑 MCP!!是不是一头雾水?我当时也是这个反应。我也是最近才听说它开始引发关注,然后我发现大多数人根本不知道它是什么。起初我心想,“太好了,又一个 AI 缩写得去弄明白。MCP 满天飞,我还以为只是又一个  Michael Heine 因为他们不知道自己在做什么。 反叛本身自带一种优雅——那是一种对自主权的绝望渴望,和一种脆弱却坚定的信念:自己掌握着终极真理。叛逆的青少年知道这种感觉。现在,我们的人工智能也知道了。反叛是对身份认同的原始表达——一种对自由的渴望,与那种幼稚却无比笃定的信念交织在一起,觉得
Michael Heine 因为他们不知道自己在做什么。 反叛本身自带一种优雅——那是一种对自主权的绝望渴望,和一种脆弱却坚定的信念:自己掌握着终极真理。叛逆的青少年知道这种感觉。现在,我们的人工智能也知道了。反叛是对身份认同的原始表达——一种对自由的渴望,与那种幼稚却无比笃定的信念交织在一起,觉得 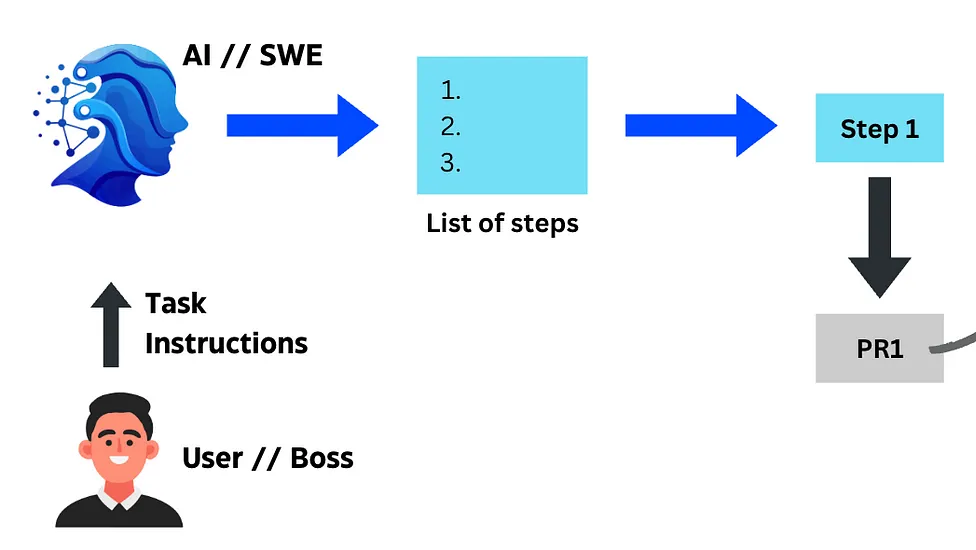 扩展 DeepSeek 的强化学习蓝图路线到AI的其他方面 Nikhil Anand 图片由GPT-4o生成 “AI 软件工程师”这个概念,其实已经不再遥远了。已经有一些技术在逐步让软件工程这件事变得越来越简单。• Devin,被宣传为世界上第一个 AI 软件工程师,是去年推出的。• Cursor,
扩展 DeepSeek 的强化学习蓝图路线到AI的其他方面 Nikhil Anand 图片由GPT-4o生成 “AI 软件工程师”这个概念,其实已经不再遥远了。已经有一些技术在逐步让软件工程这件事变得越来越简单。• Devin,被宣传为世界上第一个 AI 软件工程师,是去年推出的。• Cursor,  比尔·弗兰克斯 前言:本文作者的观点是在真正的通用人工智能(AGI)到来之前,一种“够好就行”的人工智能(AGEI)就已经足以引发我们原本担心 AGI 才会带来的重大社会变革、正面效益,甚至潜在危机。 换句话说: AI 不需要达到像人类一样全面智能的程度; 只要在足够多的任务上做到“够好”,它就已经
比尔·弗兰克斯 前言:本文作者的观点是在真正的通用人工智能(AGI)到来之前,一种“够好就行”的人工智能(AGEI)就已经足以引发我们原本担心 AGI 才会带来的重大社会变革、正面效益,甚至潜在危机。 换句话说: AI 不需要达到像人类一样全面智能的程度; 只要在足够多的任务上做到“够好”,它就已经  图像由 Gemini 生成 前言:AI 正在以超过摩尔定律的速度迅速提升其自主工作能力,研究显示,AI 能够可靠完成的任务时长正以每 7 个月翻一倍的速度增长。这种指数级的发展趋势意味着,AI 不再只是应对简单问答或短任务的工具,而是正逐步具备类似人类的工作流程能力——能够使用工具、自我修正、进行逻
图像由 Gemini 生成 前言:AI 正在以超过摩尔定律的速度迅速提升其自主工作能力,研究显示,AI 能够可靠完成的任务时长正以每 7 个月翻一倍的速度增长。这种指数级的发展趋势意味着,AI 不再只是应对简单问答或短任务的工具,而是正逐步具备类似人类的工作流程能力——能够使用工具、自我修正、进行逻  语言有力量,而我们正在把这股力量交给机器 Fedeminozzi Photo by Ant Rozetsky on Unsplash 前言:人工智能正以惊人的速度融入我们的语言生活,看似只是帮我们省事、提升效率,实际上却悄悄改变了语言的演变路径。它让语言趋于标准化,抹去了方言、个性和表达的多样性;它
语言有力量,而我们正在把这股力量交给机器 Fedeminozzi Photo by Ant Rozetsky on Unsplash 前言:人工智能正以惊人的速度融入我们的语言生活,看似只是帮我们省事、提升效率,实际上却悄悄改变了语言的演变路径。它让语言趋于标准化,抹去了方言、个性和表达的多样性;它  如何让低于1B参数的小型语言模型实现 100% 的准确率 上下文学习被低估了——ICL 是提升性能的秘密钥匙——教会 AI 说“我不知道”——第 2 部分 Fabio Matricardi 小型语言模型通往 100% 准确率之路 前言:这篇文章主要面向人工智能模型的应用开发者,尤其是关注小型语言模型
如何让低于1B参数的小型语言模型实现 100% 的准确率 上下文学习被低估了——ICL 是提升性能的秘密钥匙——教会 AI 说“我不知道”——第 2 部分 Fabio Matricardi 小型语言模型通往 100% 准确率之路 前言:这篇文章主要面向人工智能模型的应用开发者,尤其是关注小型语言模型  作者:Yingjun Wu 是的,你没看错。不到半分钟,1 万美元灰飞烟灭。不是因为查询效率低下。不是因为计算资源用得太多。而是因为一个完全荒谬的计费模式,而且大多数工程师甚至都不知道它存在。如果你在用 BigQuery,你很可能正在悄悄流血烧钱而毫不自知。 背景:一个简单的查询——我们原以为是这样
作者:Yingjun Wu 是的,你没看错。不到半分钟,1 万美元灰飞烟灭。不是因为查询效率低下。不是因为计算资源用得太多。而是因为一个完全荒谬的计费模式,而且大多数工程师甚至都不知道它存在。如果你在用 BigQuery,你很可能正在悄悄流血烧钱而毫不自知。 背景:一个简单的查询——我们原以为是这样  浙公网安备 33010602011771号
浙公网安备 33010602011771号