MySQL窗口函数汇总(一)
1.窗口函数概述
窗口函数是一种SQL函数,非常适合于数据分析,其最大的特点就是:输入值是从SELECT语句的结果集中的一行或者多行的"窗口"中获取的,也可以理解为窗口有大有小(行数有多有少)。
通过OVER子句,窗口函数与其他的SQL函数有所区别,如果函数具有OVER子句,则它是窗口函数。如果它缺少了OVER子句,则他就是个普通的聚合函数。
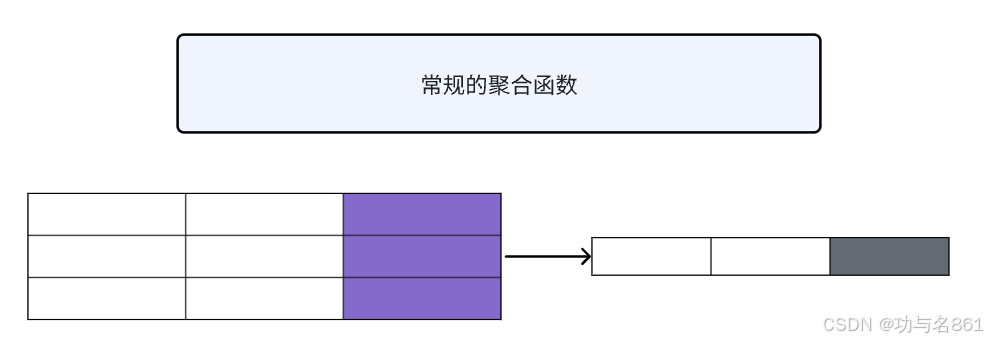
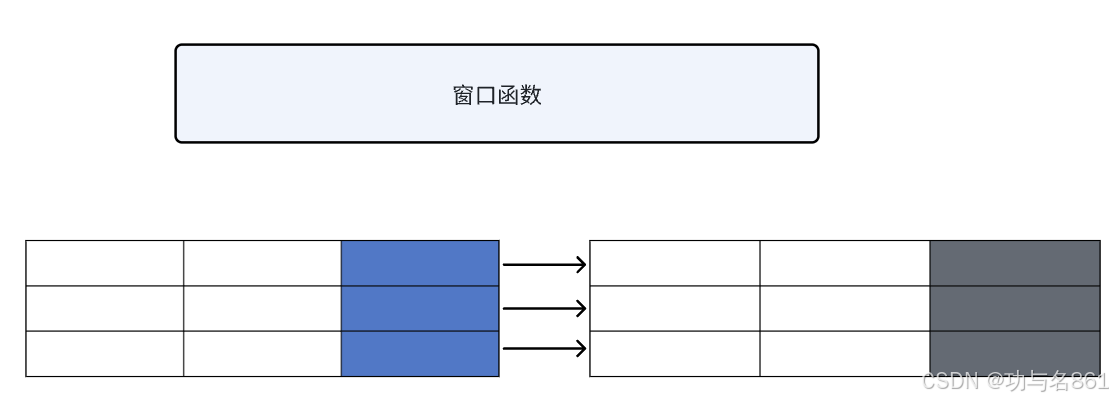
窗口函数可以简单地解释为类似于聚合函数的计算函数,但是通过GROUP BY子句组合的常规聚合会隐去正在聚合的各个行,最终输出称为一行。但是窗口函数聚合完之后还可以访问当前行的其他数据,并且可以将这些行的某些属性添加到结果当中去。
下面可以通过两个图来区分普通的聚合函数和窗口函数
首先让我们先添加测试数据,并查看表。
CREATE DATABASE IF NOT EXISTS EmployeeDB; USE EmployeeDB; CREATE TABLE Employees ( EmployeeID INT AUTO_INCREMENT PRIMARY KEY, Name VARCHAR(100), DepartmentID INT, Salary DECIMAL(10, 2) ); INSERT INTO Employees (Name, DepartmentID, Salary) VALUES ('Alice', 1, 50000), ('Bob', 1, 55000), ('Charlie', 2, 60000), ('David', 1, 50000), ('Eve', 2, 65000), ('Frank', 3, 45000), ('Grace', 3, 47000), ('Hannah', 3, 48000), ('Ian', 2, 70000), ('Jack', 1, 52000);

select DepartmentID, sum(salary) as total
from employees
group by DepartmentID;

我们可以看的出来,常规聚合函数把id进行分组然后把每组的薪资综合计算出来放在最后面。
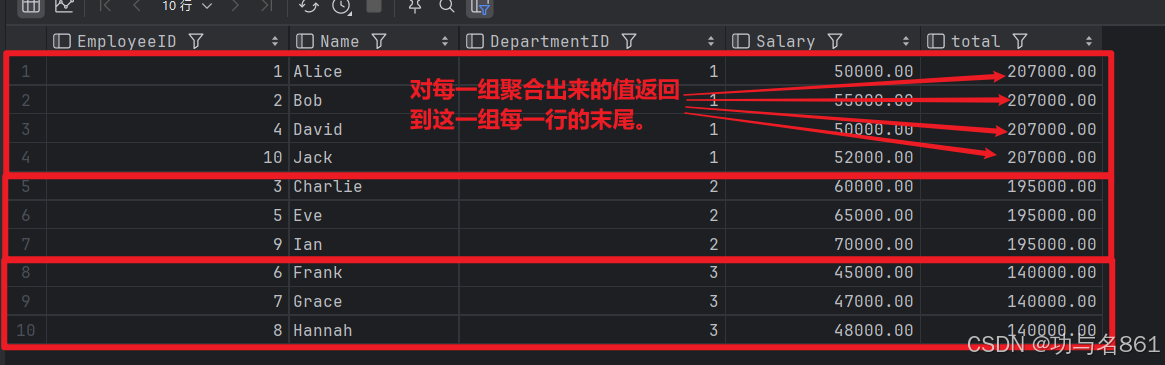
我们可以通过这两个例子看出来,聚合函数和窗口聚合函数的区别。就是窗口函数会进行分组,但不会把行进行合并。对于每一组窗口函数返回出来的结果都会重复的放在最后面。
2.窗口函数的语法
Function(arg1,..., argn) OVER ([PARTITION BY <...>] [ORDER BY <....>] [<window_expression>])
对于以上的窗口函数的语法[ ]中的语法是可以根据自己的需求进行选择(非必须写入语法),并且此语法严格按照上面的顺序来规定。
Function(arg1,..., argn)是表示函数的分类,可以是下面分类中的任何一组。
----------聚合函数,例如sum,min,avg,count等函数(常用)
----------排序函数,例如rank row_number dense_rank()等函数(常用)
----------跨行函数,lag lead 函数
OVER [PARTITION BY <...>] 类似于group by 用于指定分组
--每个分组你可以把它叫做窗口
--不分组的情况可以写成partition by null 或者直接不写partition by,所有列为一个大组
--分组的情况下,partition by 后面可以跟多个列,例如partition by cid,cname
[ORDER BY <....>] 用于指定每个分组内的数据排序规则 支持ASC、DESC
[<window_expression>] 用于指定每个窗口中 操作的数据范围 默认是窗口中所有行
1.窗口函数语法解释-Function(arg1,..., argn)
通常和partition by分组使用。当然也可以不分组使用,但也不分组使用通常没有意义。
----------聚合函数,例如sum,min,avg,count等函数(常用)
----------排序函数,例如rank row_number dense_rank()等函数(常用)
----------跨行函数,lag lead 函数
1.聚合函数
我们还通过上文的测试数据进行演示。我们就演示2个函数,其他的聚合类函数都是相同的用法。
sum函数:求和
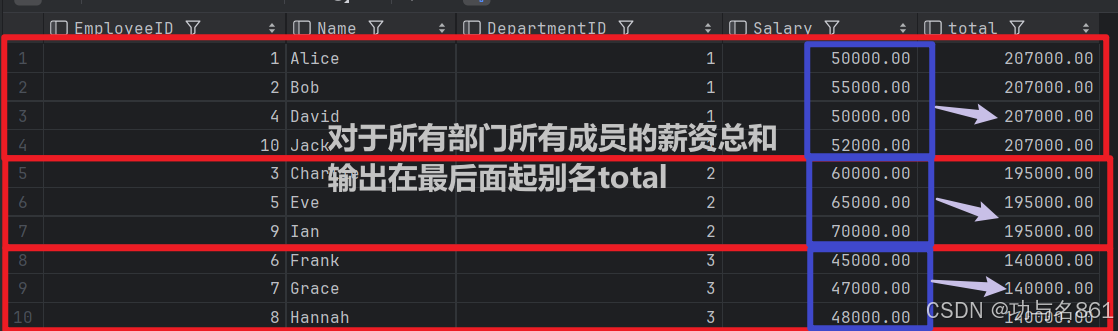
select *,
sum(Salary) over (partition by DepartmentID) total
from employees
min函数 :最小值
select *,
min(Salary) over (partition by DepartmentID) total
from employees;
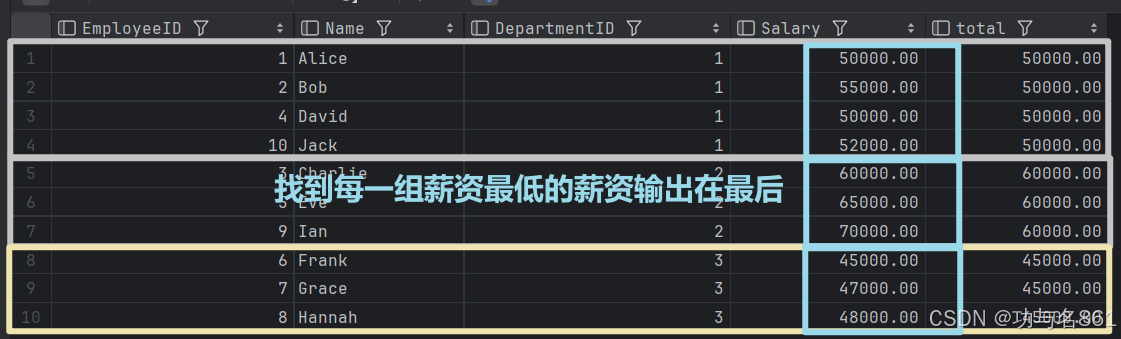
其他的聚合函数都是同样的用法。
2.排序函数
rank row_number dense_rank()等函数,通常与order by函数一起使用。
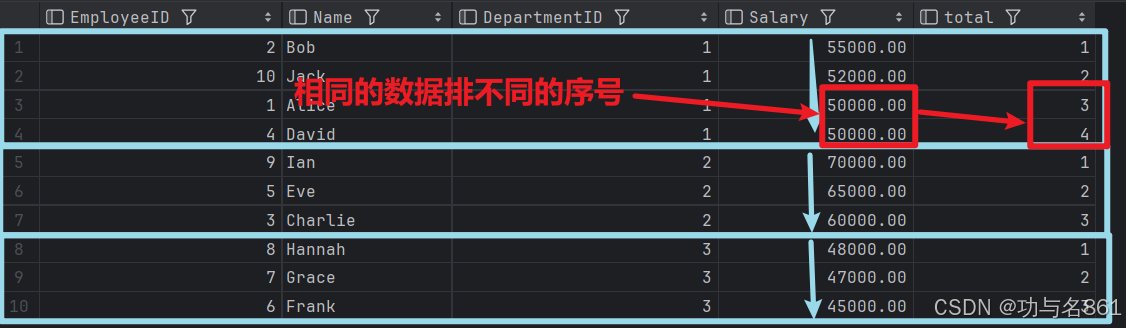
row_number()函数:对分组之后按照某些规则从高到低或者从低到高进行排序(order by),然后打上序号,不考虑并列的情况。
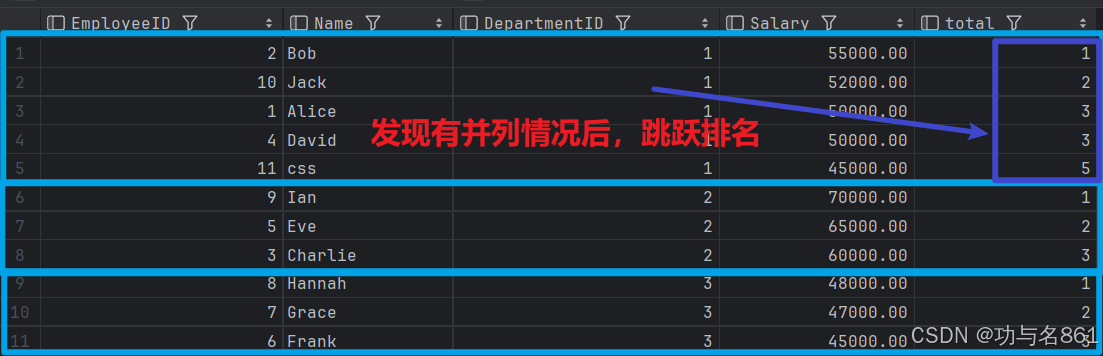
rank()函数:对分组之后按照某些规则从高到低或者从低到高进行排序(order by),然后打上序号,考虑并列情况并且跳跃排名,对此我们需要增添一组数据。
INSERT INTO Employees (Name, DepartmentID, Salary) VALUES('css',1,45000);
select *,
rank() over (partition by DepartmentID order by Salary desc ) total
from employees;
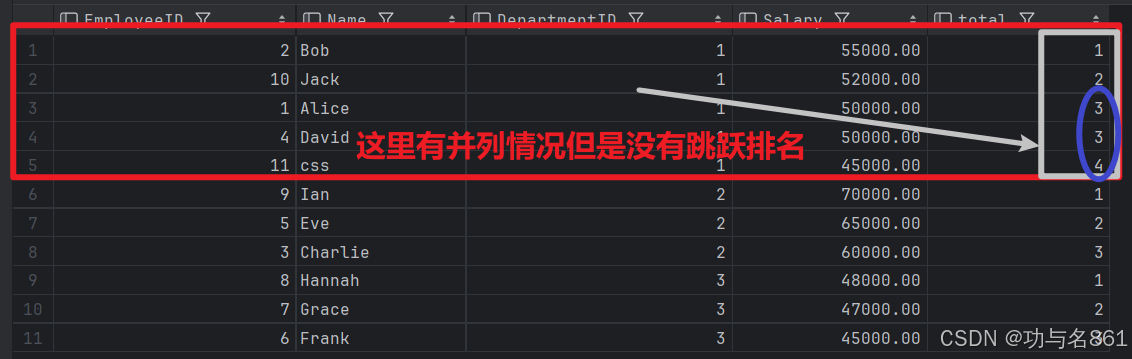
dense_rank()函数:
select *,
dense_rank() over (partition by DepartmentID order by Salary desc ) total
from employees;
3.跨行函数
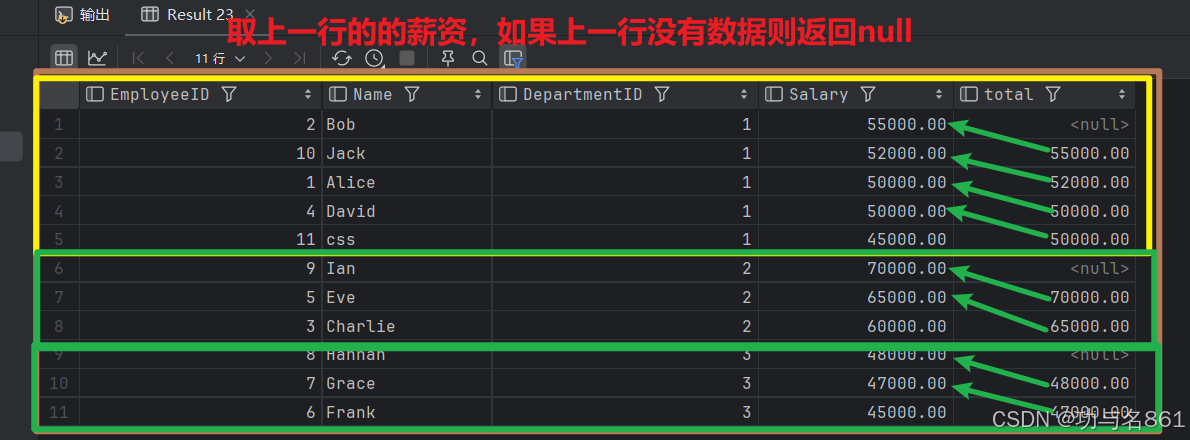
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL);
select *, lag(Salary,1) over (partition by DepartmentID order by Salary desc ) total from employees;
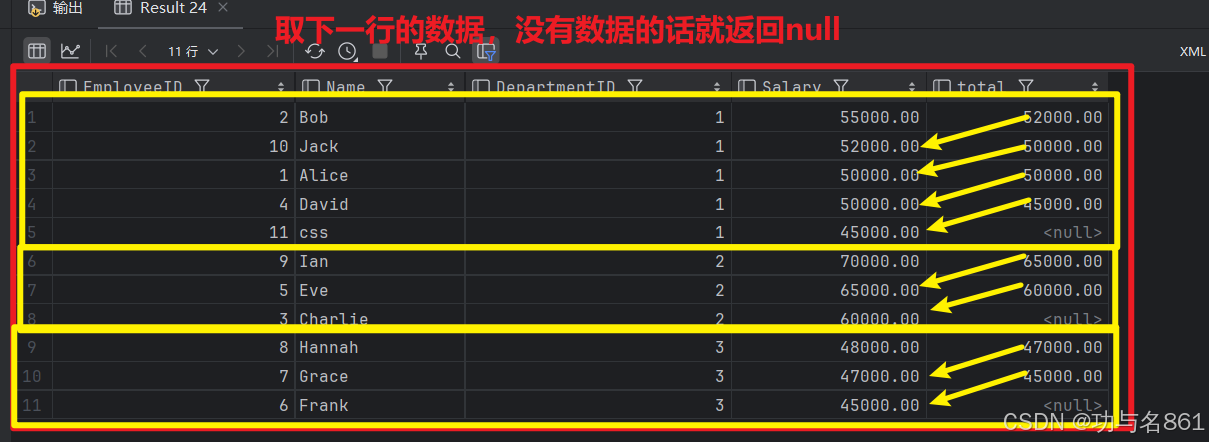
LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值
第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL);
select *, lead(Salary,1) over (partition by DepartmentID order by Salary desc ) total from employees;
FIRST_VALUE 取分组内排序后,截止到当前行,第一个值;
select *,
first_value(Salary) over (partition by DepartmentID order by Salary desc ) total
from employees;
LAST_VALUE 取分组内排序后,截止到当前行,最后一个值;
select *,
last_value(Salary) over (partition by DepartmentID order by Salary desc ) total
from employees;
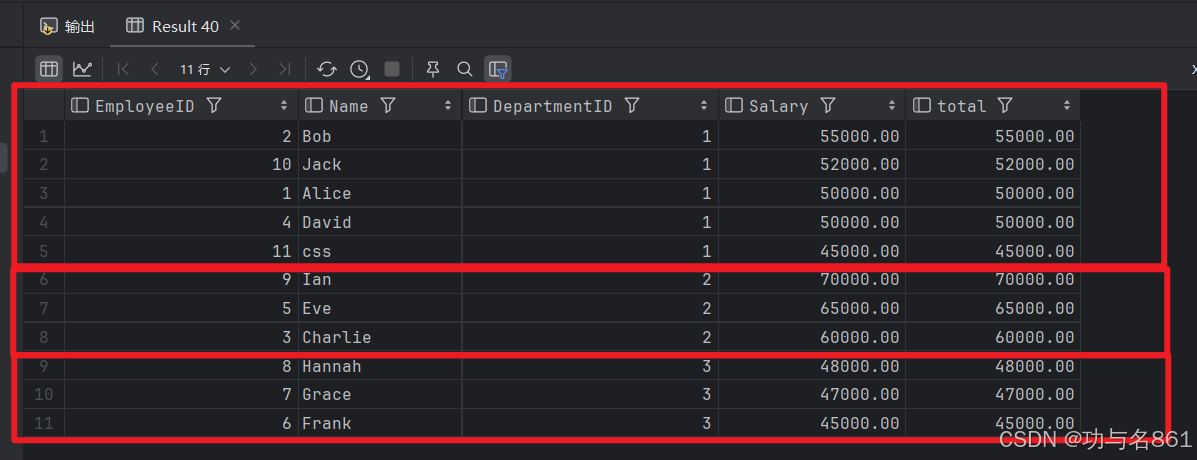
从这个数据我们有个疑问,为啥不是去分组内的最后一个值呢?
在这里我给大家解释一下,对于我们分的窗口(比如部门id=1)里面还有个小窗口row函数
对于我们没有指定小窗口默认是当之前所有行到当前行,这样理解可以很抽象,我们举个例子。对于部门id=1来说,我们从第一行来看(心里默念从之前所有行到当前行)从之前所有行到当前行来看确实输出的值应该是55000.00,那么我们看第二行(心里默念从之前所有行到当前行)那么确实输出的是52000.00。这样我们通过row函数来改变一下小窗口的范围。更清晰的感受一下这个函数。
select *,
last_value(Salary) over (partition by DepartmentID order by Salary desc
rows between unbounded preceding and unbounded following ) total
from employees;
解释一下设置小窗口的含义:rows between unbounded preceding and unbounded following
之前所有的行到之后所有的行,那么让我们输出一下。

我们可以很清晰的看出来,输出的是每一组里面最后一个的薪资。
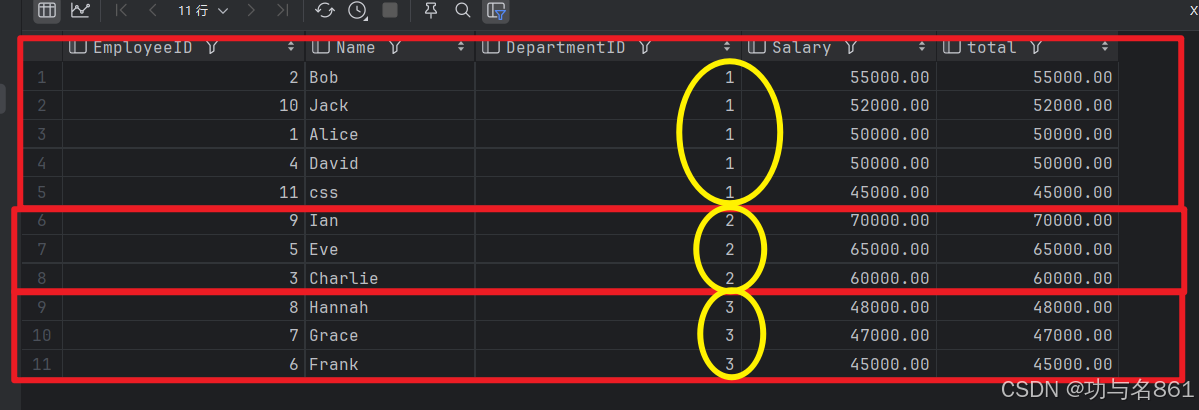
2.窗口函数语法解释-OVER [PARTITION BY <...>]
over是窗口函数的标志,partition by 用来指定分组,把partition by 后面跟的字段相同的放在一起
参考博客:https://blog.csdn.net/qq_62757927/article/details/140793659

 浙公网安备 33010602011771号
浙公网安备 33010602011771号