

ClickHouse知识汇总
什么是OLAP与OLTP
- OLAP(OnLine Analytical Processing)联机分析系统;
- OLTP(OnLine Transaction Processing)联机事务处理系统;
- OLAP主要用来读取数据、分析数据,辅助运营决策分析。数据一次性批量写入后,分析师需要从各种角度出发,对数据进行挖掘分析,以期发现其中的商业价值、业务变化趋势等;
- OLAP主要用来做离线分析,对时效性要求不高。
- OLAP主要的开源产品包括HDFS、HIVE和Impala等;目标应用场景就是一次写入,多次读取;
- OLTP是进行事务的增删改查。比如在电商系统中进行商品的购买、库存减少、购物车下单支付等。
- OLTP是传统的关系型数据库的主要应用,也被称为是面向交易的处理系统,一般用于大数据在线业务系统中,要求有实时性。
- OLAP:读 + 一次性的写入;
- OLTP:实时的读 + 实时的写
如此理解:OLTP可变相视为是OLAP的数据源。
前期我们需要通过OLTP来进行数据的累积,当数据累积到一定的程度,我们需要对过去发生的事情做一个统计分析,来为公司的决策提供支持,这时候就是在做OLAP了。综上,简单地说,OLAP是OLTP的延展,让数据发挥更大价值。再加一点,传统的数据库,主要是面向OLTP,而数据仓库主要面对OLAP,侧重决策分析。所谓数据仓库,是一个更好的支持企业或者组织的决策分析处理的面向主题的、集成的、不可更新的、随时间不断变化的数据集合。

行式数据库与列式数据库
什么是行式和列式?
行式数据库:以行相关的存储体系进行数据存储;
列式数据库:以列相关的存储体系进行数据存储;
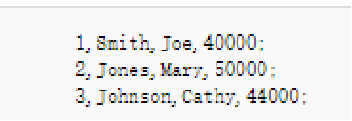
假设现在我们有下图这样的数据:

行式存储,会将一行数据串成一串字符,一行一行存储,即:
列式存储,会将一列字符串成一串,一列一列做存储,即:
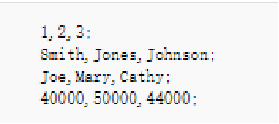
相比来讲,列式存储更适合查询,每一列都是索引。
行式和列式的优缺点
列式数据库:
- 每一列单独存储,意味着数据本身就是索引,查询快;
- 每一列数据类型一致,意味着更高效的压缩;
- 只将select集合中需要的列读入内存,极大降低系统的IO。
列式的优点就是行式的缺点。
- 行式数据库擅长随机读操作,列式数据库更擅长大批量数据的查询。
- 列式数据库本身就是面向大数据环境下的数据分析而生,适合大量数据而不是小批量数据,适合查询操作而不是增删改。
- 列式数据库在并行查询处理和压缩上更有优势,列式数据库的主要应用场景就是在99%的操作都是查询的应用。很适合OLAP。
- 列式数据库的代表包括:[HANA], [Sybase IQ]],ParAccel, Sand/DNAAnalytics和 Vertica。
ClickHouse
什么是clickhouse?俄罗斯第一大搜索引擎Yandex在2016年6月15日开源了一个数据分析的数据库,名字叫做ClickHouse,开源免费,圈内人戏称为“喀秋莎数据库。
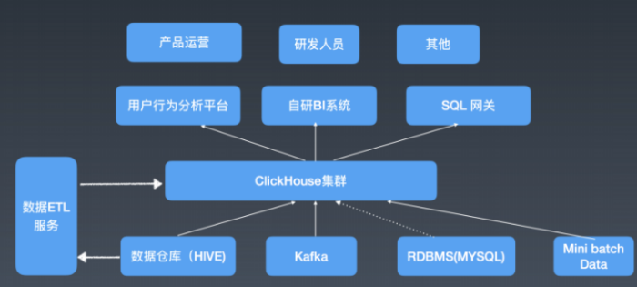
clickhouse的优点和缺点
clickhouse的三大特点:跑分快、功能多、限制多。
为什么说它跑分快?
一亿数据:ClickHouse比Vertica约快5倍,比Hive快279倍,比My SQL快801倍;
十亿数据:ClickHouse比Vertica约快5倍,MySQL和Hive已经无法完成任务了;
ClickHouse的快是因为采用了并行处理机制,在默认情况下,即使一个查询,也会占用服务器一半的CPU去执行,这也是ClickHouse不能支持高并发的原因。(当然,这个占用核数是可以配置的)
另外,它的压缩率高,目前clickhouse的数据压缩能够达到30%~40%。
为什么说限制多?据说,clickhouse生来就是为小资服务的。
- 目前只支持Ubuntu系统。windows下需要Ubuntu虚拟环境;
- 不支持高并发,官方建议QBS(每秒查询率)为100;
- 不提供设计和架构文档,设计很神秘的样子,只有开源的C++源码;
- 不理睬Hadoop生态,采用 Local attached storage 作为存储,走自己的路,自我实现分布式部署。
- 不支持事务,不存在隔离级别;
- 写入慢;
- 上手存在难度,老毛子做的有些粗犷(所谓的喀秋莎数据库,有一部分是源于这里);
- join性能欠佳,远不如其在单表上的表现,所以建议多使用宽表来代替join。(clickhouse支持列宽到一万列左右)
clickhouse的功能特性
计算层
多核并行、分布式计算、近似计算和复杂数据类型支持等;
多核并行:在clickhouse中数据被分成了多个分区,查询某条数据时通过多分区的数据,利用CPU的多核同时并行处理获取数据,降低了查询时长;
分布式计算:ClickHouse将查询任务拆分成多个子任务下发到多个集群中进行多机并行处理,最后汇聚结果给到用户,提供最近hostname规则(即将任务下发到机器最近的hostname节点)、inorder(即按顺序进行分发,当某个分片不可用时,下发到下一个分片)
近似计算:指的是牺牲一定的精确度获取数据,在海量数据的分析中,其实并不需要非常精准的数据,近似数据足以分析决策,ClickHouse提供了中位数、分位数(二分位数即中位数、四分位数等)等多种聚合函数,极大的提高了查询性能,减轻了计算压力。所谓的近似计算,实际上就是提供了一堆写好的聚合函数是吗,可提供迅速的近似计算。支持对数据进行抽样处理。
复杂数据类型支持:ClickHouse还提供了array、json、tuple、set等复合数据类型,也是极为有效的;
参考文档:https://blog.csdn.net/wlh2220133699/article/details/131519819
