

Redis-Hash数据类型总结
哈希在很多编程语言中都有着很广泛的应用,而在Redis中也是如此,在redis中,哈希类型是指Redis键值对中的值本身又是一个键值对结构,形如value=[{field1,value1},...{fieldN,valueN}],其与Redis字符串对象的区别如下图所示:
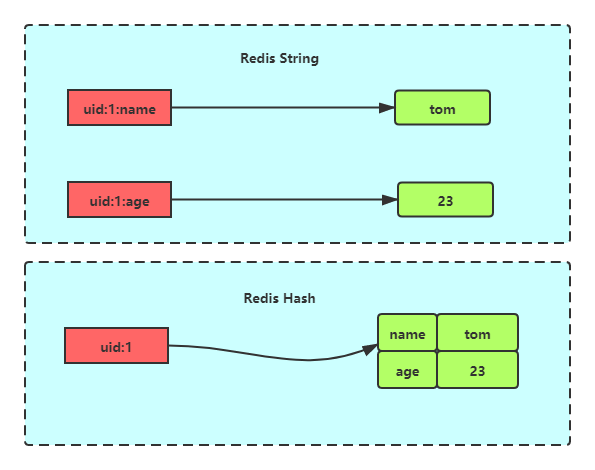
一:内部编码
哈希类型的内部编码有两种:ziplist(压缩列表),hashtable(哈希表)。只有当存储的数据量比较小的情况下,Redis 才使用压缩列表来实现字典类型。具体需要满足两个条件:
- 当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个)
- 所有值都小于hash-max-ziplist-value配置(默认64字节)ziplist使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀。当哈希类型无法满足ziplist的条件时,Redis会使用hashtable作为哈希的内部实现,因为此时ziplist的读写效率会下降,而hashtable的读写时间复杂度为O(1)。
有关ziplist和hashtable这两种redis底层数据结构的具体实现可以参考我的另外两篇文章。
Redis数据结构——压缩列表
Redis数据结构——字典。
二、常用命令
Redis哈希对象常用命令如下表(点击命令可查看命令详细说明)。
| 命令 | 说明 | 时间复杂度 |
|---|---|---|
| HDEL key field [field ...] | 删除一个或多个Hash的field | O(N) N是被删除的字段数量。 |
| HEXISTS key field | 判断field是否存在于hash中 | O(1) |
| HGET key field | 获取hash中field的值 | O(1) |
| HGETALL key | 从hash中读取全部的域和值 | O(N) N是Hash的长度 |
| HINCRBY key field increment | 将hash中指定域的值增加给定的数字 | O(1) |
| HINCRBYFLOAT key field increment | 将hash中指定域的值增加给定的浮点数 | O(1) |
| HKEYS key | 获取hash的所有字段 | O(N) N是Hash的长度 |
| HLEN key | 获取hash里所有字段的数量 | O(1) |
| HMGET key field [field ...] | 获取hash里面指定字段的值 | O(N) N是请求的字段数 |
| HMSET key field value [field value ...] | 设置hash字段值 | O(N) N是设置的字段数 |
| HSET key field value | 设置hash里面一个字段的值 | O(1) |
| HSETNX key field value | 设置hash的一个字段,只有当这个字段不存在时有效 | O(1) |
| HSTRLEN key field | 获取hash里面指定field的长度 | O(1) |
| HVALS key | 获得hash的所有值 | O(N) N是Hash的长度 |
| HSCAN key cursor [MATCH pattern] [COUNT count] | 迭代hash里面的元素 |
三:适用场景
3.1存储对象
Redis哈希对象常常用来缓存一些对象信息,如用户信息、商品信息、配置信息等。
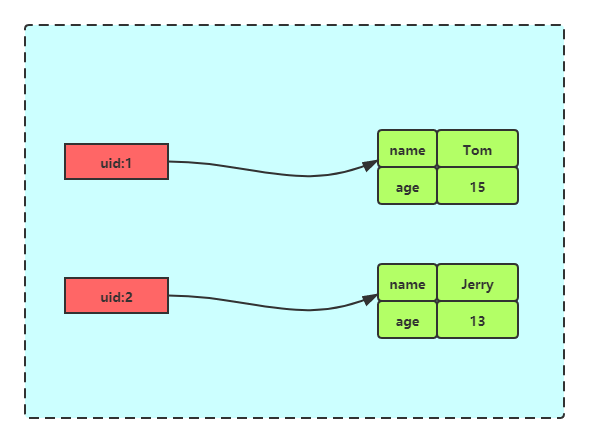
我们以用户信息为例,它在关系型数据库中的结构是这样的
| uid | name | age |
|---|---|---|
| 1 | Tom | 15 |
| 2 | Jerry | 13 |
而使用Redis Hash存储其结构如下图:
相比较于使用Redis字符串存储,其有以下几个优缺点:
1、原生字符串每个属性一个键。
set user:1:name Tom
set user:1:age 15
优点:简单直观,每个属性都支持更新操作。
缺点:占用过多的键,内存占用量较大,同时用户信息内聚性比较差,所以此种方案一般不会在生产环境使用。
2、序列化字符串后,将用户信息序列化后用一个键保存
set user:1 serialize(userInfo)
优点:简化编程,如果合理的使用序列化可以提高内存的使用效率。
缺点:序列化和反序列化有一定的开销,同时每次更新属性都需要把全部数据取出进行反序列化,更新后再序列化到Redis中。
3、序列化字符串后,将用户信息序列化后用一个键保存
hmset user:1 name Tom age 15
优点:简单直观,如果使用合理可以减少内存空间的使用。
缺点:要控制哈希在ziplist和hashtable两种内部编码的转换,hashtable会消耗更多内存。
此外,我们曾经在做配置中心系统的时候,使用Hash来缓存每个应用的配置信息,其在数据库中的数据结构大致如下表
3.1、购物车
很多电商网站会使用cookie实现购物车,也就是将整个购物车都存储到 cookie里面。这种做法的一大优点:无须对数据库进行写入就可以实现购物车功能,这种方式大大提高了购物车的性能,而缺点则是程序需要重新解析和验证( validate) cookie,确保cookie的格式正确,并且包含的商品都是真正可购买的商品。cookie购物车还有一个缺点:因为浏览器每次发送请求都会连 cookie一起发送,所以如果购物车cookie的体积比较大,那么请求发送和处理的速度可能会有所降低。购物车的定义非常简单:我们以每个用户的用户ID(或者CookieId)作为Redis的Key,每个用户的购物车都是一个哈希表,这个哈希表存储了商品ID与商品订购数量之间的映射。在商品的订购数量出现变化时,我们操作Redis哈希对购物车进行更新:
如果用户订购某件商品的数量大于0,那么程序会将这件商品的ID以及用户订购该商品的数量添加到散列里面。
//用户1 商品1 数量1 127.0.0.1:6379> HSET uid:1 pid:1 1 (integer) 1 //返回值0代表改field在哈希表中不存在,为新增的field
如果用户购买的商品已经存在于散列里面,那么新的订购数量会覆盖已有的订购数量;
//用户1 商品1 数量5 127.0.0.1:6379> HSET uid:1 pid:1 5 (integer) 0 //返回值0代表改field在哈希表中已经存在
相反地,如果用户订购某件商品的数量不大于0,那么程序将从散列里面移除该条目。
//用户1 商品1 127.0.0.1:6379> HDEL uid:1 pid:2 (integer) 1
3.3、计数器
Redis 哈希表作为计数器的使用也非常广泛。它常常被用在记录网站每一天、一月、一年的访问数量。每一次访问,我们在对应的field上自增1

//记录我的 127.0.0.1:6379> HINCRBY MyBlog 202001 1 (integer) 1 127.0.0.1:6379> HINCRBY MyBlog 202001 1 (integer) 2 127.0.0.1:6379> HINCRBY MyBlog 202002 1 (integer) 1 127.0.0.1:6379> HINCRBY MyBlog 202002 1 (integer) 2
也经常被用在记录商品的好评数量,差评数量上
127.0.0.1:6379> HINCRBY pid:1 Good 1 (integer) 1 127.0.0.1:6379> HINCRBY pid:1 Good 1 (integer) 2 127.0.0.1:6379> HINCRBY pid:1 bad 1 (integer) 1
也可以实时记录当天的在线的人数。
//有人登陆 127.0.0.1:6379> HINCRBY MySite 20200310 1 (integer) 1 //有人登陆 127.0.0.1:6379> HINCRBY MySite 20200310 1 (integer) 2 //有人登出 127.0.0.1:6379> HINCRBY MySite 20200310 -1 (integer) 1
小结
本篇文章我们总结了Redis 哈希对象的内部实现、常用命令以及常用的一些场景,那么大家在项目中对Redis哈希对象的使用都有哪些场景呢,欢迎在评论区给我留言和分享,我会第一时间反馈!我们共同学习与进步!
参考博客:
https://www.cnblogs.com/hunternet/p/12651530.html
https://www.jianshu.com/p/28d4198085c8


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2021-05-03 设计模式总结
2021-05-03 策略模式-设计模式