
kafka文件存储形式
Kafka 中消息是以 topic 进行分类的,生产者生产消息,消费者消费消息,都是面向topic的。topic存储结构见下图:
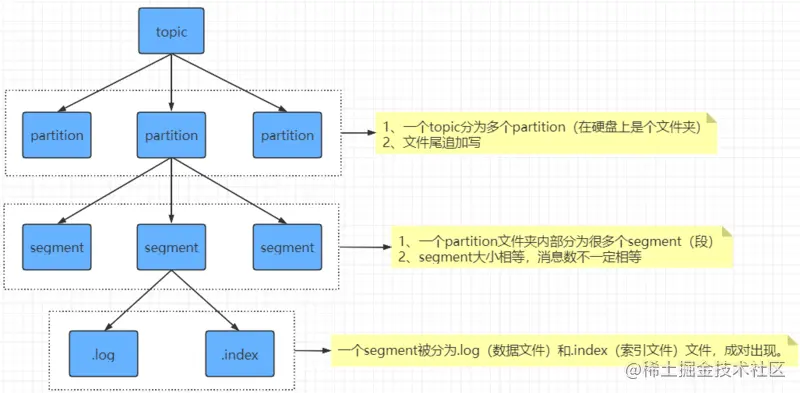
由于生产者生产的消息会不断追加到 log 文件末尾,为防止 log 文件过大导致数据定位效率低下,Kafka 采取了分片和索引机制,将每个partition分为多个segment。每个 segment对应两个文件——“.index”文件和“.log”文件。
partition文件夹命名规则
topic 名称+分区序号,举例有一个topic名称文“kafka”,这个topic有三个分区,则每个文件夹命名如下:
kafka-0 kafka-1 kafka-2
index和log文件的命名规则
1)partition文件夹中的第一个segment从0开始,以后每个segement文件以上一个segment文件的最后一条消息的offset+1命名(当前日志中的第一条消息的offset值命名)。
2)数值最大为64位long大小。19位数字字符长度,没有数字用0填充。
举例,有以下三对文件:
0000000000000000000.log 0000000000000000000.index 0000000000000002584.log 0000000000000002584.index 0000000000000006857.log 0000000000000006857.index
以第二个文件为例看下对应的数据结构:
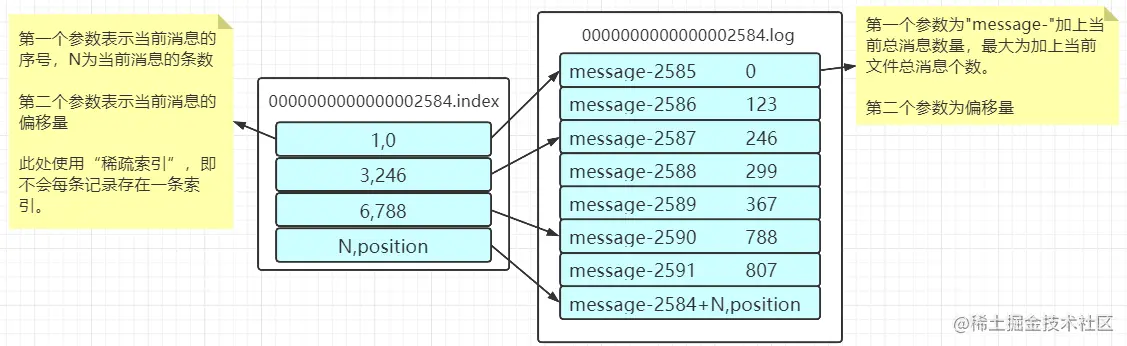
稀疏索引需要注意下。
消息查找过程:一定要学习会查找一个offset所在的位置以及所在的segment文件、log文件中。首先从index文件中进行查找,然后定位到所在的log文件中的offset文件中。
找message-2589,即offset为2589:
1)先定位segment文件,在0000000000000002584中。
2)计算查找的offset在日志文件的相对偏移量,其实可以假设一个绝对的偏移量:相对偏移量 + baseOffset
offset - 文件名的数量 = 2589 - 2584 = 5;
在index文件查找第一个参数的值,若找到,则获取到偏移量,通过偏移量到log文件去找对应偏移量的数据即可;
本例中没有找到,则找到当前索引中偏移量的上线最接近的值,即3,偏移量文246;然后到log文件中从偏移量为246数据开始向下寻找。

