
G1垃圾回收器--基本知识及原理解析
G1介绍(Garbage first)
G1主要面向的是服务端的垃圾回收器。在G1之前,JVM的主要垃圾回收器采用的是物理分代的思想,将内存区域严格的划分成年轻代(young GC)和老年代(major GC),然后针对于年轻代和老年代使用不同的垃圾回收器进行GC操作,直到G1,G1采用的是对整个堆进行回收,并且G1使用的分区region思想将内存划分成了许多的分区。
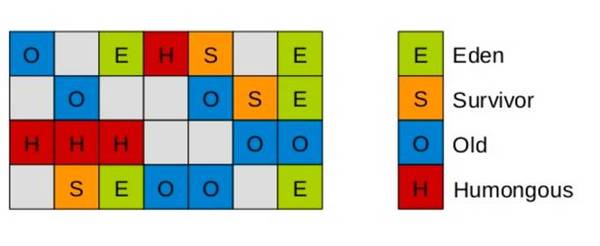
虽说G1不使用严格将内存分为年轻代和老年代,但是在逻辑层面G1还是将分区region贴上了标签Eden,Survivor,Old,也是一种分代的思想,并且G1针对于特别大的对象(当一个对象会占据一个分区的一般以上空间G1称为大对象)会将该大对象用一段连续的多个Humongous分区(专门存放大对象)存放。G1的大多数行为都会将Humougous分区判定为老年代看待。
每个region的大小可以通过XX:G1HeapRegionSize设定(取值范围1~32MB),且为2的N次幂。
G1的停顿时间控制
用户自定义停顿时间
G1的还有一个特点就是用户可以通过设置-XX:MaxGCPauseMills来设置用户允许的停顿时间(默认为200ms),G1会根据这个时间尽可能的回收垃圾,所以这也是G1是比较全能的原因。针对用户自定义停顿时间我们可以猜想到,G1很可能无法完全回收所有垃圾(因为设定了一个时间),但是G1会尽可能的多收集垃圾。
有点类似于老板给员工制定一个KPI,要求高就多收集点,要求低就少收集点。这也是G1的一个回收特点:并不是回收全部垃圾,而是尽可能在用户规定得停顿时间内尽可能回收垃圾多的region。
G1如何实现尽可能回收最多垃圾region?
G1之所以能够建立预测停顿时间的模型,依赖于G1是针对于分区region进行整体回收,即每次回收都是以region为单位。那么G1如何判断哪些region的回收率高(即垃圾多):G1收集器会跟踪每个region里面垃圾堆积的价值(即回收该region所获的空间和所需时间的价值),然后再后台维护一个优先级列表,每次根据该优先级列表进行回收(优先处理优先级高的region),这也是Garbage First的由来。
如果存在跨代引用如何解决?
针对于年轻代的region我们每次都会进行回收,所以不需要考虑年轻代指向老年代。
针对于老年代指向年轻代的引用我们如何选择(如果不管则使用整个堆的GC root扫描),这里提出的思想是记忆集rset(remember set),
G1是对每个region维护了一个rset,记忆集中维护了指向自己的region的指针,并且标记指针分别在那些卡页的范围之内。由于G1使用了很多的region(每个region都有一个rset),所以G1使用了较高的内存,基本占用Java对内存的10%~20%的额外内存来维持收集器的工作。
用户停顿时间的设置
- 如果用户停顿时间过长:那么会导致用户线程停止很长时间,降低吞吐量。
- 如果用户停顿时间过短:那么会导致一次GC回收不了太多的垃圾对象,则会导致频繁GC,也会降低吞吐量。
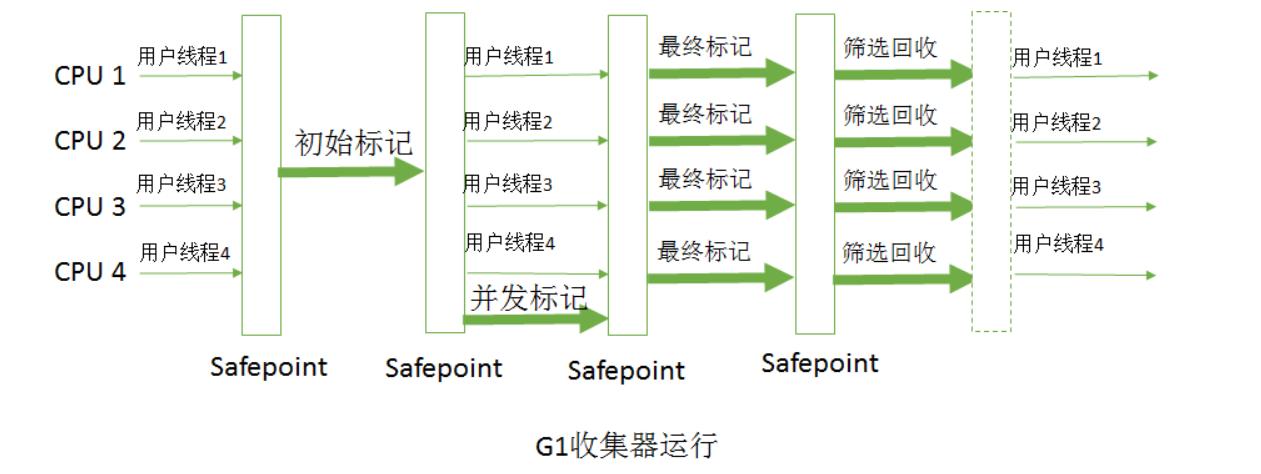
G1垃圾收集的工作流程
G1的收集过程主要分为四步:
1.初始标记
仅仅标记GC roots能直接关联到的对象。该步骤需要STW,但是时间极短。
2.并发标记
从GC roots使用可达性算法,对堆内存中对象进行标记(三色标记法),递归扫描整个堆。该步骤耗时过长,是与用户业务程序并发执行。
3.重新标记
对用户线程短暂的STW,用于处理并发标记中对象的一些变更情况的最终确定。
4.筛选回收
G1会根据用户规定的停顿时间,最大的回收region,将需要被回收的region复制到空白region中,再将原region全部回收。该步骤也需要STW,因为涉及到了对象的移动(一个region到另一个region)。
三色标记法

黑色:自身及其子对象已经被标记。
灰色:自身已经被标记,但是子对象没有完全被标记
白色:自身未被标记,如果标记结束后仍然为白色,则是垃圾对象。

