
ElasticSearch-Search运行机制
Search
Search执行的时候实际上是分为两个步骤运作的:Query 和 Fetch。
Query阶段

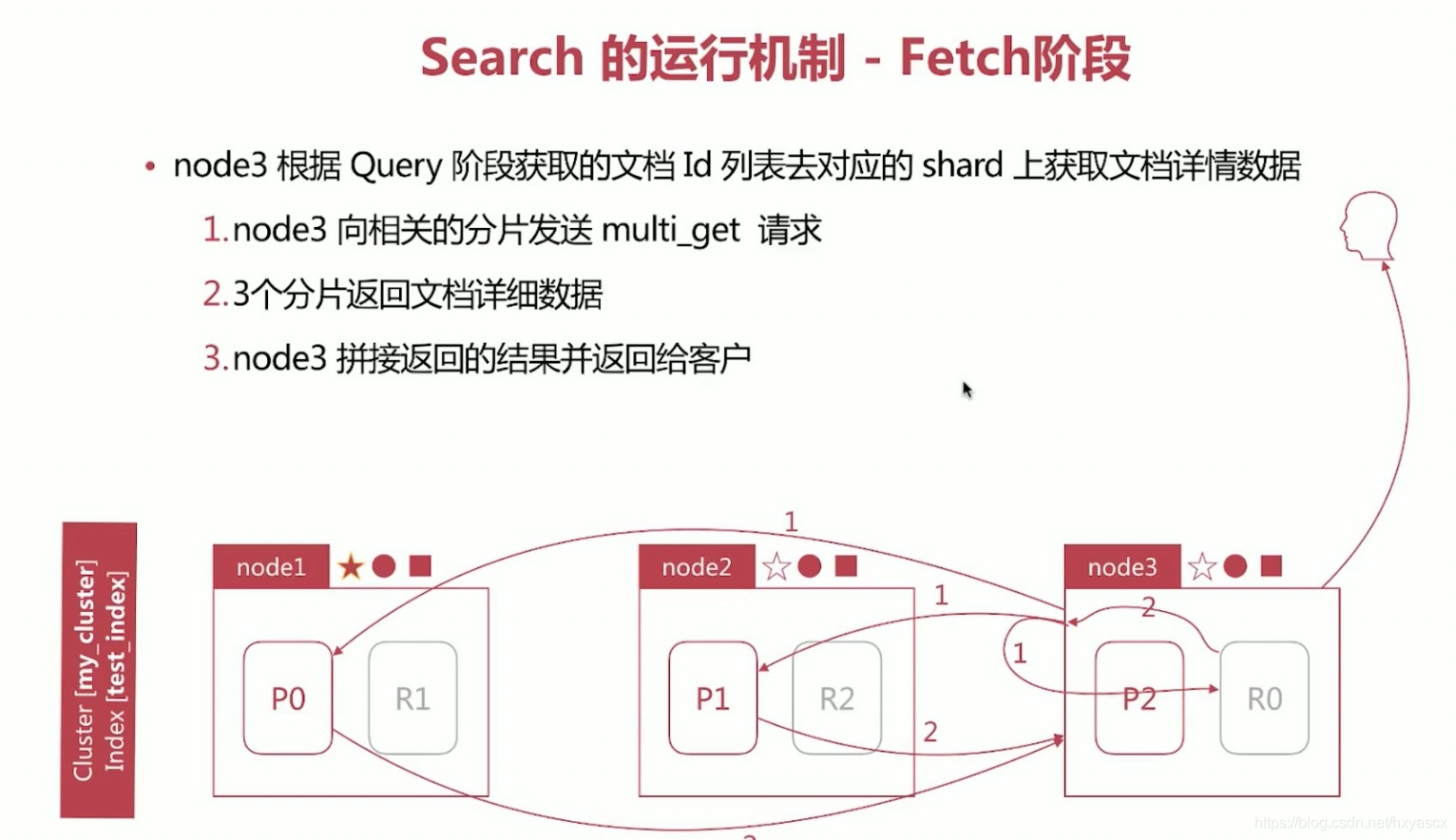
Fetch
排序
es默认采用相关性算分排序,用户可以通过设定sorting参数来自行设定排序规则。
GET book/_search { "query": { "bool": { "must": [ { "match": { "author": "张三" } } ] } }, "sort": [ { "publishDate": { "order": "desc" } } ] }
排序的过程实质是对字段原始内容排序对的过程,这个过程中倒排索引无法发挥作用,需要用到正排索引,也就是通过文档id和字段可以快速得到字段原始内容。
es对此提供了2种实现方式:
- fieldata 默认禁用。
- doc values默认启用,除了text类型。
Fieldata VS DocValues

分页与遍历
es提供了3种方式来解决分页与遍历的问题:
- from/size
- scroll
- search_after
from/size
最常用的分页方案。from 指明开始位置 size 指明获取总数。from从0开始算起。
GET book/_search { "query": { "bool": { "must": [ { "match": { "author": "张三" } } ] } }, "from": 0, "size": 1 }
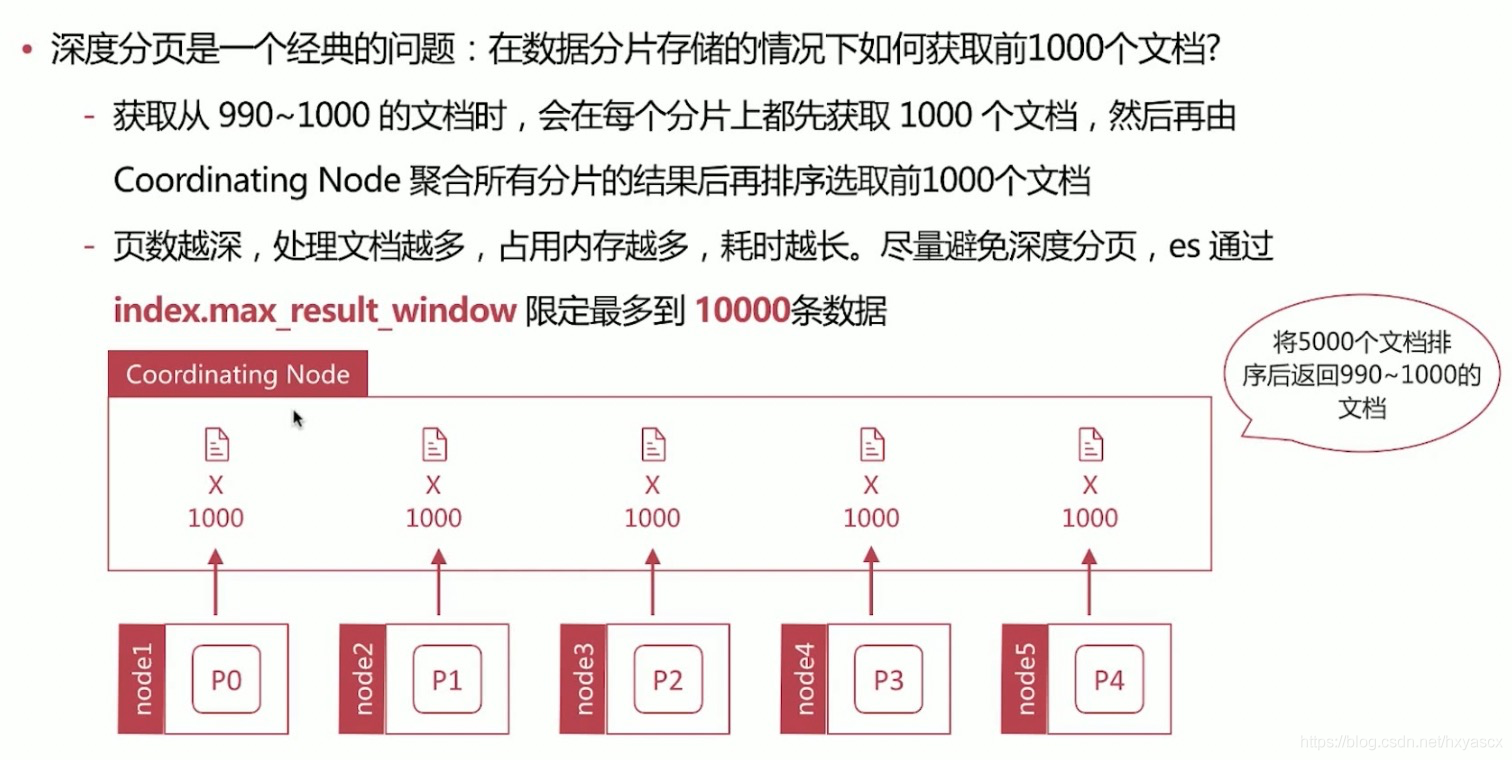
深度分页问题
scroll
遍历文档集都api,以快照的方式来避免深度分页的问题
- 不能用来做实时搜索,因为数据不是实时的。
- 尽量不要使用复杂的sort条件,使用_doc最高效。
- 使用稍微复杂
Search_After
避免深度分页的性能问题,提供实时的下一页文档的获取功能。
- 缺点是不能使用from参数,即不能指定页数。
- 只能下一页不能上一页。
- 使用简单
应用场景

郭慕荣博客园

